



Один из главнейших вопросов статистики — «Что же происходит на самом деле в генеральной совокупности». Найти на него ответ трудно и приходится пользоваться методом индукции (то есть делать вывод о том, что там происходит на самом деле, на основе того небольшого количества данных, которое есть в нашем распоряжении). Я, например, люблю ходить в лес и собирать грибы. Каждый раз, приходя домой, в моём распоряжении оказывается огромная корзина с выборками лисичек, опят, подберёзовиков и сыроежек. Хотя вру, конечно. Сыроежки я не беру. Так вот, по этой выборке иногда волей — не волей делаешь вывод о том, что собой представляют соответствующие генеральные совокупности, то есть та самая поляна с лисичками и тот лес с подберёзовиками. Сам собой напрашивается вывод о том, что одно место грибное, а другое — нет. Этот вывод индуктивный, так же как и любой другой вывод, который можно сделать о виде, форме, вкусе и цвете собранных грибов. Собрать все грибы в лесу, очевидно, не представляется возможным, поэтому мы делаем выводы на основе того, что имеем в корзине.
Аналогично любые статистические методы используют метод индукции. Когда бы мы ни делали какие-либо выводы о том или ином показателе, мы всегда имеем в виду, что вывод сделан лишь по выборке из всех потенциально имеющихся данных.
Я не собираюсь вдаваться в детали того, как правильно формировать выборку (для временных рядов это не так актуально, как для пространственных) и не хочу углубляться в теорию вероятностей. Поэтому для ответов на вопросы, касающиеся этих тем, рекомендую обратиться к специализированной статистической литературе, например, к учебнику Гмурмана В.Е. «Теория вероятностей и математическая статистика» или Вентцель Е.С. «Теория вероятностей». Здесь я хочу обсудить кратко наиболее важные вопросы выборочного метода с точки зрения прогнозирования. Должен предупредить, что мой взгляд на вещи может не совпадать со взглядами других учёных.
Однако прежде чем двигаться дальше, нужно разобраться с одним важным вопросом. Что такое вероятность? Например, диктор в новостях сказал, что вероятность выпадения осадков сегодня днём составляет 0,41. Как это понять?! Некоторые трактуют эту величину как то, что в 41 из абсолютно одинаковых 100 дней выпадут осадки. Это не совсем правильная трактовка. Дело в том, что даже в этих 100 днях осадки на практике могут идти в 10 или, скажем, в 80 случаях. На самом деле эта вероятность показывает что можно ожидать ассимптотически: если бы у нас было огромное (а может, даже и бесконечное) количество таких же дней как этот, то в 41% из них шёл бы дождь. Даже в опыте с бросанием монеты получить половину решек, а половину орлов можно лишь асимптотически, когда число испытаний оказывается достаточно большим. Поэтому даже, если вероятность чего-то на практике (по имеющимся данным) оказалась меньше 5%, это не говорит о том, что так оно и есть на самом деле. Эту особенность относительно вероятностей очень важно понимать, так как с ними в статистике и прогнозировании приходится встречаться достаточно часто, а неправильная их трактовка может приводить к неправильному принятию решений.
Свойства оценок
Говоря о том, что вероятность выпадения осадков составляет 0.41, диктор на самом деле имеет в виду не ту самую истинную вероятность из генеральной совокупности, а лишь её оценку по имеющимся данным. Под оценкой какого-либо показателя в статистике понимают значение, полученное с помощью некоторого метода. Это значение обычно характеризует некоторый показатель в генеральной совокупности. Например, средняя величина является оценкой математического ожидания в генеральной совокупности.
Из-за того, что оценки зависят от тех данных, которые есть в нашем распоряжении, мы всегда сталкиваемся с неопределённостью. Например, средняя величина по ряду чисел, взятых из моей головы: {3, 7, 5} — равна 5, а средняя похожего ряда {3, 7, 5, 3} — уже 4,5. Ряды отличаются только одним числом (последней тройкой), но оценки, как видим, оказываются различными. Поэтому, оценив среднюю по первой выборке, сказать, что в моей голове сидит средняя, равная 5, однозначно нельзя — с добавлением новой информации оценка уточняется.
Из-за этой неопределённости у оценок показателей могут быть разные свойства, наиболее полезными из которых в статистике считаются:
- Несмещённость. Грубо говоря несмещённая оценка — это такая, которая не имеет систематического отклонения относительно некоторого истинного, из генеральной совокупности. Естественно, мы не можем знать, что там происходит в генеральной совокупности на самом деле, но иногда мы можем показать чисто математически, что наша оценка не имеет серьёзных систематических отклонений относительно нашего «идеала». Если оценка показателя смещённая, то прогнозы по модели, использующей данный показатель, так же могут быть смещёнными. Соответственно, прогноз по некоторой модели можно считать несмещённым, если у него нет систематических занижений или завышений (то есть прогнозное значение проходит каким-то образом в «середине» фактических).
- Эффективность. В грубом статистическом понимании эффективность — это мера дисперсии нашей оценки. Не очень понятно, да? Рассмотрим пример. Допустим, я нагенерировал чисел на 100 наблюдений. Затем я хитрым образом оценил математическое ожидание по первым 50 наблюдениям и у меня получилось 4,5. Потом я оценил математическое ожидание по второй группе из 50 наблюдений. Получилось 50. Так вот, из-за того, что значения полученных оценок в этих двух случаях разнятся очень сильно, хитрый метод, который я использовал, дал мне неэффективные оценки математического ожидания (это при условии того, что выборка у нас репрезентативна, а генератор случайных чисел в моей голове стабилен). Это всё потому, что полученная оценка колеблется в достаточно больших пределах, от 4,5 до 50. Впрочем, мы не можем однозначно сказать, эффективна ли некоторая оценка или нет. Зато мы можем сравнивать эффективность одних оценок с эффективностью других. И если простая средняя величина по тем же двум частям выборки даёт нам 4,5 и 5 соответственно, то можно сказать, что это более эффективная оценка математического ожидания, нежели мой хитрый метод. Это свойство так же, как и первое, обычно показывают математически. В прогнозировании эффективные оценки важны, так как гарантируют своеобразную стабильность модели. Меняя выборку, мы не получим что-то разительно другое. Эффективные оценки будут лежать в некотором узком интервале (по сравнению с неэффективными).
- Состоятельность. Если с ростом числа наблюдений наша оценка не меняется радикально, а уточняется, приближается к «истинному» значению, то такая оценка состоятельна. По мере увеличения числа наблюдений дисперсия оценки будет приближаться к нулю (так как фактор случайности будет нивелироваться). Если это свойство нарушается, то с ростом числа наблюдений мы будем получать значение, находящееся всё дальше и дальше от истинного, а значит и точность прогнозов с ростом \(T\) будет падать. Это свойство важно в прогнозировании, так как гарантирует, что с появлением новой информации мы не получим какие-то совершенно другие оценки параметров модели. То есть нам не придётся срочно менять все планы по производству, продвижению и т.п. просто из-за того, что значение какого-то коэффициента сменилось с 2 на -3.
- Ассимптотическая нормальность. Это свойство фактически связано с предыдущими. Оно означает, что по мере увеличения числа наблюдений все отклонения наших оценок относительно истинных будут носить случайный и непрогнозируемый характер. Этот процесс может описываться двумя параметрами: математическим ожиданием и дисперсией оценки. Это свойство позволяет на практике строить доверительные интервалы для оценок на основе нормального закона распределения случайных величин.
Стоит заметить, что эти свойства в реальности на малых выборках не выполняются, а вступают в силу лишь с ростом числа наблюдений, на больших выборках. Получаемые параметры практически всегда будут далеки от истинных значений, но знать, что какой-нибудь метод наименьших квадратов при выполнении ряда условий даёт несмещённые, эффективные и состоятельные оценки полезно, так как это гарантирует, что мы на верном пути и что использование доверительных интервалов для оценок действительно имеет какой-то смысл, а с появлением новой информации мы будем уточнять наш прогноз, а не ухудшать его. Всё это, впрочем, актуально лишь в том случае, если модель правильно специфицирована и в ней нет пропущенных переменных (об этом мы поговорим в одной из следующих глав).
Вообще, конечно, ассимптотически (с приближением числа наблюдений к бесконечности) никакая модель ненужна, и любой процесс описывается двумя показателями: средней величиной и дисперсией. Это объясняется такими явлениями как Закон Больших Чисел (ЗБЧ) и Центральная Предельная Теорема (ЦПТ). Первый утверждает, что с ростом числа наблюдений средняя величина по выборке приближается к истиной средней. Вторая говорит о том, что сумма любых слабозависимых случайных чисел, имеющих примерно один масштаб, будет асимптотически распределена нормально. То есть, дайте мне большое (очень большое (очень-очень большое)) число наблюдений, и я вам опишу, любой процесс. Однако в прогнозировании этот факт особо не помогает.
Введение в проверку статистических гипотез
Теперь мы знаем, что оценки параметров носят случайный характер и могут обладать всякими теоретически полезными свойствами. Но частенько нам бывает нужно понять, лежит ли истинное значение в некотором интервале, построенном на основе нашей оценки, или нет. Для этого обычно используют либо доверительные интервалы, либо механизм проверки статистических гипотез. На самом деле это две связанные вещи, но второму иногда отдают предпочтение из-за простоты восприятия.
Для начала ещё раз обратим внимание на один важный элемент — все описанные ниже механизмы основываются на индуктивном методе познания. А это означает, что мы никогда не можем с уверенностью сказать, что в генеральной совокупности какой-нибудь коэффициент какой-нибудь модели равен нулю или не равен нулю. Обычно в нашем распоряжении есть данные, которые указывают на результат, но никогда однозначного и точного ответа нам не дают. Именно поэтому при проверке гипотез используют фразы «гипотеза не отклоняется на таком-то уровне» или «гипотеза отклоняется на сяком-то уровне». Мы никогда не принимаем никаких гипотез! И мы никогда не можем сказать, что у нас есть какие-то доказательства в пользу или против гипотезы. Мы имеем дело с неопределённостью, поэтому и результат проверки гипотез — это тоже неопределённость. Просто путём проверки гипотез мы первоначальную неопределённость можем уменьшить. К сожалению, убрать её окончательно невозможно.
Хорошим примером механизма гипотез и неопределённости является история с чёрными лебедями (см. Нассим Талеб, «Чёрный лебедь»). До 1697 года считалось, что все лебеди белые, так как данные различных наблюдений показывали, что лебедей других цветов просто не бывает. Однако голландская экспедиция обнаружила в западной Австралии чёрных лебедей, таким образом опровергнув первоначальную гипотезу. Вывод: если наши наблюдения показывают нам, что какой-то параметр незначим, то это ещё не говорит о том, что это действительно так.
Итак, что же собой представляет этот замечательный механизм уменьшения неопределённости.
Для того, чтобы проверить какую-либо гипотезу, её нужно сначал сформулировать. Обычно гипотезы формулируются в двух частях: как нулевая (\( H_0 \)) и альтернативная (\( H_1 \)). Альтернативной обычно является то, что мы пытаемся проверить, а нулевой — то, что мы пытаемся опровергнуть. Таким образом аналитик собирает доказательства для опровержения нулевой гипотезы в пользу альтернативной. В связи с этим альтернативную гипотезу принято формулировать в виде неравенства. Например, гипотеза о том, что средняя величина чисел в моей голове равна пяти может быть сформулирована следующим образом:
\begin{equation} \label{eq:msh_hypothesis}
\begin{matrix}
H_0: \mu = 5 \\
H_1: \mu \neq 5 ,
\end{matrix}
\end{equation}
где \( \mu \) — это та самая средняя в генеральной совокупности всех чисел в моей голове. Если такую гипотезу не удастся опровергнуть, то это не означает, что средняя действительно равна пяти. Это скорее означает что мы не смогли найти доказательств обратного. В этом смысле отвержение нулевой гипотезы в пользу альтернативной является более полезным результатом, так как даёт представление о том, чем средняя в моей голове, скорее всего, не является.
Иногда такую же гипотезу переписывают в другой форме, оставляя в правой части ноль:
\begin{equation} \label{eq:msh_hypothesis1}
\begin{matrix}
H_0: \mu -5 = 0 \\
H_1: \mu -5 \neq 0
\end{matrix} .
\end{equation}
Сути это не меняет, но иногда облегчает восприятие задачи.
Гипотезы могут быть разными. Например, нас может интересовать, больше ли это число 10. В этом случае будем иметь:
\begin{equation} \label{eq:msh_hypothesis2}
\begin{matrix}
H_0: \mu = 10 \\
H_1: \mu > 10
\end{matrix} .
\end{equation}
Причём знак «>» в \eqref{eq:msh_hypothesis2} поставлен в альтернативную гипотезу не просто так: не отклонение нулевой гипотезы мало что даёт, так как это может просто означать, что нам не хватило наблюдений для того, чтобы сделать это. А вот отклонение её даже на небольшом числе наблюдений уменьшает ту самую пресловутую неопределённость и говорит о том, что, возможно таки средняя больше 10. Поэтому нулевую гипотезу принято формулировать в форме «равно», а альтернативную — в интересующем нас виде.
Иногда гипотезу \eqref{eq:msh_hypothesis2} формулируют в несколько ином виде, что, однако, не меняет её сути:
\begin{equation} \label{eq:msh_hypothesis3}
\begin{matrix}
H_0: \mu \leq 10 \\
H_1: \mu > 10
\end{matrix} .
\end{equation}
Прежде чем двигаться дальше, нужно разъяснить два важных термина, связанных с проверкой гипотез непосредственно.
Доверительная вероятность — это вероятность, с которой наблюдаемая случайная величина попадёт в интервал заданной ширины. На самом деле правильное определение немного не такое, а вот такое: это вероятность, с которой интервал заданной ширины накроет случайную величину. Но вдаваться в детали всего этого мне здесь, честно говоря, не хочется.
Остаточная вероятность — это вероятность, с которой наблюдаемая случайная величина выйдет за границы заданного интервала.
Как видите, уже даже в этих определениях мы говорим о каких-то интервалах — видна та самая связь между проверкой гипотезы и построением доверительных интервалов, упомянутая вскользь выше.
В чём же заключается сам механизм проверки гипотез? Вначале исследователь определяет уровень доверительной вероятности. Типичными являются 90%, 95% и 99%. В реальной жизни выбор доверительной вероятности определяется какими-нибудь бизнес условиями и задачами. Например, какой-нибудь кол-центр может иметь цель обслуживать 95% позвонивших клиентов в первые 5 минут после их дозвона. Или компания-производитель мягких тёплых булочек может в качестве ориентира поставить себе удовлетворение 99% спроса. В этих случаях есть маленький процент (5% в первом и 1% во втором), который соответствует остаточной вероятности. Это будет означать в наших двух примерах, что асимптотически 5% дозвонившихся будут ждать больше 5 минут, а 1% потребителей не получит этих мягких тёплых булочек.
После определения остаточной вероятности рассчитывается статистика по некоторой формуле (подробней об этом ниже), а затем — полученное число сравнивается с некоторым табличным значением (выбранным для нашей остаточной вероятности). Например, если в ходе проверки гипотезы \eqref{eq:msh_hypothesis2} некоторая волшебная формула дала нам значение равное 3.14159265359, а табличное (для 95% доверительной вероятности) при этом составляло 3, то наша гипотеза отклоняется на 5% уровне остаточной вероятности и можно сделать вывод о том, что число в моей голове скорее всего отлично от десяти. Мы в этом не уверены на 100% и допускаем, что могли совершить ошибку, надеясь на то, что она произойдёт не чаще, чем в 5% случаев, если мы подобный тест будем проводить много раз с разными данными из моей головы.
Тот же самый тест бывает легче понять, если обратиться к доверительным интервалам, построенным на основе той же самой волшебной формулы. В этом случае попадание в этот интервал рассчитанного числа будет говорить о не отклонении гипотезы. Ну, а если интервалы число не накрывают, то гипотеза отклоняется.
Графически процесс проверки гипотез показан на следующем кривом рисунке (см. ниже). Доверительная вероятность на нём — это площадь под фигурой с соответствующей надписью, а остаточная — это сумма площадей в хвостах распределения. Доверительный интервал в этом нашем экзотическом случае составляет (-1, 3). Как видим, число 3.14159265359 не попало в интервал, поэтому гипотеза отклоняется.
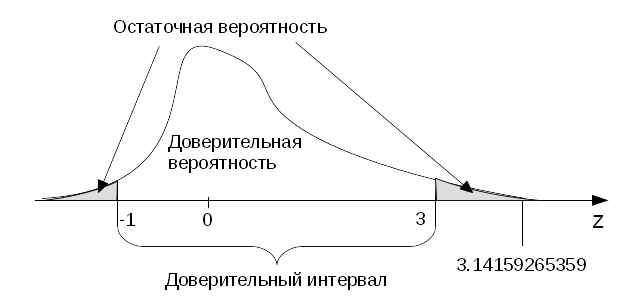
Распределение чисел в моей голове
К точно такому же выводу можно прийти, если рассчитать по таблице на основе того самого числа 3.14159265359 вероятность и сравнить её с нашей остаточной. Эта вероятность называется по английски «p-value» (p-значение) и по сути показывает, какой площади соответствуют хвосты, отсекаемые нашим числом. По рисунку видно, что площадь хвоста правее 3.14159265359 значительно меньше остаточной вероятности. Математически это будет соответствовать низкому значению p-value, что трактуется всё так же — гипотеза может быть отклонена на 5% уровне остаточной вероятности. Очевидно, что при изменении уровня остаточной вероятности, площади в хвостах будут уменьшаться,а интервалы расширяться, что в некоторых случаях может приводить к тому, что результат проверки гипотезы будет меняться. На практике такое встречается нередко: если гипотеза отклоняется на 5%, то она может и не отклониться на 1%. Определение уровня остаточной вероятности в таких ситуациях остаётся на совести исследователя.
В статистике иногда проводят демонстрацию-эксперимент — предлагают каждому студенту сделать случайную выборку из какого-нибудь массива данных и проверить по этой выборке гипотезу, например, о том, что математическое ожидание в генеральной совокупности равно 10 (пусть оно действительно равно 10) с уровнем остаточной вероятности в 5%. Результаты такого эксперимента обычно показывают, что у 5% студентов в группе гипотеза отклоняется, хотя на самом деле и не должна. Это наглядно демонстрирует, что при проверке статистических гипотез мы всегда рискуем. Об этом нельзя забывать. Единственное решение этой проблемы — увеличение объёма выборки, но это не всегда возможно. Почему именно, мы обсудим чуть позже. А пока давайте посмотрим на некоторые популярные тесты.
Вообще существует два метода проверки статистических гипотез: параметрический и непараметрический. В первом случае исследователь должен сделать предположение о законе распределения случайной величины, в то время как во втором случае этого обычно делать ненужно. Тесты из первой группы при этом, как говорят, имеют большую мощность, чем вторые. Здесь имеется в виду, что вероятность прийти к правильным выводам в первом случае оказывается выше, чем во втором, но только при условии выполнения предположения о распределении случайной величины.
Параметрические методы проверки гипотез
Чуть ли ни каждый учебник по прогнозированию, экономитрике, а тем более по статистике, в самом начале обычно рассказывает о параметрических статистических тестах. В нашем учебнике по прогнозированию тоже был подобный разбор. Поэтому здесь мы особенно на этой теме останавливаться не будем. Заметим однако, что все такие тесты выводятся из связи распределений случайных величин. Например, известно, что сумма квадратов нормально распределённых случайных величин распределена по \(\chi^2\). Это свойство обычно используется для проверки гипотезы о равенстве дисперсии какому-нибудь числу. Аналогичным образом можно прийти, например, к тому, что для сравнения дисперсий нужно использовать F-тест.
Рассмотрим кратко самые популярные параметрические тесты.
z-тест
z-тест используется достаточно редко и только для проверки того, что случайная величина получена из нормального распределения. Он же используется для построения прогнозных интервалов в случае, если величина распределена нормально. Пусть нас интересует некоторая величина объёма продаж секир в пятницу 13-го, которую мы обозначим как \(x_j = 51\). По результатам исследований в прошлом и на основе гадания на кофейной гущи, мы выяснили, что истинное математическое ожидание продаж секир составляет 41, а среднеквадратическое отклонение — 4. Допустим, что мы хотим проверить, не выбивается ли 51 из нормального распределения (то есть, не происходит ли чего-то необычного с продажами секир в пятницу 13-го). Фактически в этом случае мы хотим проверить, отличимо ли наше число от 41 в генеральной совокупности, что может быть сформулировано как следующая гипотеза:
\begin{equation} \label{eq:msh_hypothesis_z}
\begin{matrix}
H_0: x_j = 41 \\
H_1: x_j \neq 41 .
\end{matrix}
\end{equation}
Для того, чтобы проверить эту гипотезу, мы должны это число стандартизировать — перевести в шкалу стандартного нормального распределения, для которого у нас имеются табличные значения. Делается это следующим образом:
\begin{equation} \label{eq:msh_z-test}
z = \left| \frac{x_j -\mu} {\sigma} \right| = \left| \frac{51 -41} {4} \right| = 2.5
\end{equation}
После этого число 2.5 надо сравнить с табличным значением для остаточного уровня вероятности. Возьмём для разнообразия 3%. z-статистика для этого случая составляет примерно 2.17 (это с учётом того, что альтернативная гипотеза сформулирована в терминах «неравно», что означает, что надо отсечь оба хвоста нормального распределения). Так как \(2.5 > 2.17\), гипотеза отклоняется на 3% уровне.
К точно такому же выводу можно прийти, если мы построим доверительный интервал. Делается это путём простых манипуляций в формуле \eqref{eq:msh_z-test} и подстановкой вместо z значения из таблицы.
\begin{equation} \label{eq:msh_z-test1}
z_{\alpha} \sigma = \left| x_j -\mu \right| ,
\end{equation}
\begin{equation} \label{eq:msh_z-test2}
\mu -z_{\alpha} \sigma \leq x_j \leq \mu + z_{\alpha} \sigma .
\end{equation}
Подставив значения \(z_{\alpha} = 2.17, \mu = 41 \text{ и } \sigma = 4\) в \eqref{eq:msh_z-test2}, получим следующий интервал:
\begin{equation} \label{eq:msh_z-test-interval}
32.32 \leq x_j \leq 49.68 .
\end{equation}
То есть мы ожидаем, что в 97% случаев продажи секир будут лежать в интервале от 32.32 до 49.68. В 3% случаев продажи могут выходить за эти границы. Наш объём продаж в 51 штуку вышел за границы, что говорит либо о том, что что-то здесь не чисто, либо о том, что всё нормально и мы имеем дело с одним из тех 3% случаев.
Построение интервалов мне кажется более наглядным, чем проведение тестов, но каждому своё…
Как уже, наверно, понятно из этого примера, в прогнозировании эти принципы используются при построении доверительных и прогнозных интервалов. Особый интерес для нас, конечно же, представляют последние. Но подробней мы о них поговорим в другой главе.
t-тест
Если бы мы не знали истинное среднеквадратическое отклонение, то нам нужно было бы его оценить. В этом случае z-тест уже не применим, но зато можно использовать t-тест благодаря тому, что нормальное распределение и распределение Стьюдента связаны следующим отношением:
\begin{equation} \label{eq:msh_t-stat}
\text{Если } \text{iid } z_j \sim N(0, 1), \forall j, \text{ тогда } y_j = \frac{z_j}{\sqrt{\frac{1}{n} \sum_{j=1}^n z_j^2 }} \sim t(n) .
\end{equation}
Данная формула расшифровывается следующим образом: если случайная величина \(z_j\) имеет стандартное нормальное распределение и при этом все \(j\) распределены одинаково и независимо (iid), то \(y_j\), рассчитанный по формуле \eqref{eq:msh_t-stat} будет распределён по Стьюденту с \(n\) степенями свободы.
Несложно показать, что в этом случае для проверки, например, гипотезы о том, что уровень продаж секир за всё время составляет 43 штуки нужно использовать значение, рассчитанное по следующей формуле:
\begin{equation} \label{eq:msh_t-test}
t = \left| \frac{\bar{x} -\mu}{\sqrt{\frac{1}{n} s^2 }} \right| ,
\end{equation}
где \(s^2\) — это выборочная дисперсия по продажам секир.
Все принципы проверки гипотезы здесь остаются такими же, как и в прошлом случае, стоит, однако заметить, что мы фактически в этом тесте предполагаем, что наши продажи секир распределены нормально. Это важно, так как нарушение этого предположения будет приводить к ошибочным результатам.
Важно так же отметить, что при проведении этого и других тестов, рассмотренных нами ниже, требуется знать число степеней свободы. Вычисляется оно как \(n-k\), где \(n\) — это объём выборки, а \(k\) — число оценённых параметров. В случае с нашим примером и t-тестом \eqref{eq:msh_t-test} число оценённых параметров равно одному (выборочная дисперсия).
t-тест чаще всего используется в регрессионном анализе для проверки гипотезы о том, что какой-то коэффициент равен нулю (\(H_0: \beta = 0; H_1: \beta \neq 0\)). Принцип проверки гипотезы в этом случае практически ничем не отличается, просто вместо \(\bar x\) и \(\sqrt{\frac{1}{n} s^2 }\) в этом случае используются значение коэффициента и его стандартное отклонение. Заметим ещё раз (повторение - мать учения), что отклонение гипотезы, как и её не отклонение в этом случае только позволяет уменьшить неопределённость, но ни в коем случае не означает, что какой-то эффект в исследуемом процессе действительно существует.
\(\chi^2\)-тест
Следующий шаг -- проверка гипотез по поводу дисперсии. Могут быть разные причины, почему нам надо знать, равна ли она в генеральной совокупности 16 или нет. Одна из причин -- проверить, не произошло ли изменений в поведении наших потребителей и не стал ли спрос на секиры колебаться сильнее, чем он должен. Для этого используется связь между нормальным распределением и \(\chi^2\):
\begin{equation} \label{eq:msh_chi2-stat}
\text{Если } \text{iid } z_j \sim N(0, 1), \forall j, \text{ тогда } X = \sum_{t=1}^n z_j^2 \sim \chi^2(n) .
\end{equation}
Особенностью этого теста является то, что распределение \(\chi^2\) несимметрично, поэтому при определении остаточной вероятности нужно отдельно определять левый и правый хвосты. Приведём пример:
\begin{equation} \label{eq:msh_hypothesis_chi2_1}
\begin{matrix}
H_0: \sigma^2 = 16 \\
H_1: \sigma^2 > 16 .
\end{matrix}
\end{equation}
Здесь мы проверяем, больше ли дисперсия в генеральной совокупности 16 или нет. Эту же гипотезу можно переписать в виде:
\begin{equation} \label{eq:msh_hypothesis_chi2_2}
\begin{matrix}
H_0: \frac{\sigma^2}{16} = 1 \\
H_1: \frac{\sigma^2}{16} > 1 .
\end{matrix}
\end{equation}
Можно показать (опять же, см. учебник по прогнозированию, если нужны детали), что следующее отношение будет распределено по \(\chi^2\):
\begin{equation} \label{eq:msh_chi2-test}
\frac{s^2}{\sigma^2} \left( n-k \right) \sim \chi^2(n-k).
\end{equation}
Всё, что остаётся сделать для проверки гипотезы \eqref{eq:msh_hypothesis_chi2_2} -- это подставить в числитель \eqref{eq:msh_chi2-test} выборочную дисперсию \(s^2\), а в знаменатель -- число 16. Это даст нам расчётное значение, которое затем мы можем сравнить с критическим в правом хвосте распределения.
В прогнозировании \(\chi^2\)-тест может так же использоваться для выявления связи между переменными, измеренными в номинальных или порядковых шкалах.
F-тест
Последний популярный параметрический тест -- это F-тест. Он бывает нужен, когда есть необходимость проверить гипотезы о равенстве нескольких дисперсий. Что-нибудь типа такого:
\begin{equation} \label{eq:msh_hypothesis_F_1}
\begin{matrix}
H_0: \sigma_1^2 = \sigma_2^2 \\
H_1: \sigma_1^2 > \sigma_2^2 .
\end{matrix}
\end{equation}
Такое может быть нужно, если мы хотим знать, например, отличается ли дисперсия продаж секир по пятницам от дисперсии продаж по воскресениям. Изменение формулировки гипотезы \eqref{eq:msh_hypothesis_F_1} следующим образом:
\begin{equation} \label{eq:msh_hypothesis_F_2}
\begin{matrix}
H_0: \frac{\sigma_1^2}{\sigma_2^2} = 1 \\
H_1: \frac{\sigma_1^2}{\sigma_2^2} > 1
\end{matrix}
\end{equation}
позволяет сделать первый шаг к пониманию, какой именно тест надо использовать. Здесь мы говорим об отношении дисперсий нормально распределённых случайных величин. Как мы выяснили выше, дисперсии, умноженные на число степеней свободы, распределены по \(\chi^2\). Такое отношение непосредственно связано с распределением Фишера:
\begin{equation} \label{eq:msh_F-stat}
\text{Если } df_1 \cdot s_1^2 \sim \chi^2(df_1), df_2 \cdot s_2^2 \sim \chi^2(df_2), \text{ тогда } F = \frac{s_1^2}{s_2^2} \sim F(df_1, df_2) ,
\end{equation}
где \(df_1\) -- число степеней свободы в первом случае, \(df_2\) -- во втором.
Распределение Фишера так же, как и распределение \(\chi^2\) несимметрично, поэтому при проверке гипотезы нужно учитывать эту асимметрию и находить табличной значение отдельно для левого и отдельно для правого хвостов распределения.
F-тест так же позволяет проверять более сложные гипотезы. Например, о том, что несколько случайных величин равны между собой.
В прогнозировании он может использоваться для сравнения прогнозов нескольких моделей. Этот тест применим к сравнению значений между группами, но показывает лишь то, равны ли средние по всем группам или нет, не поясняя, в чём именно выражается и где проявляется отличие.
Тесты в R
Упомянутые выше параметрические тесты -- наиболее популярные. При этом можно вывести и другие, зная как распределена исходная случайная величина, и как она связана с интересующей нас статистикой. Нельзя, конечно, забывать о том, что всё это чаще всего основывается на предположении о том, что некая случайная величина распределена нормально. Вообще специалисты в области статистики любят нормальное распределение, потому что оно такое простое и удобное.
Непараметрические методы проверки гипотез
Общая идея непараметрических тестов заключается в том, чтобы работать не с самими значениями переменной, а с их рангами. То есть ряд данных \(x\) каким-нибудь образом упорядочивается (например, по возрастанию), после чего с ним проводят какие-нибудь хитрые манипуляции. В результате всё так же получается какая-нибудь статистика, которая сравнивается с табличным значением, после чего делаются выводы относительно сформулированной гипотезы. Преимуществом таких тестов является отсутствие предположений относительно распределения случайной величины и высокая робастность. Так при наличии в данных значений сильно выбивающихся из общей картины (выбросов), непараметрические тесты всё равно могут давать адекватные результаты, в то время как параметрические тесты будут ошибаться.
Среди всего разнообразия тестов для целей прогнозирования бывают нужны два:
- Тест Уилкоксона (Wilcoxon),
- Тест Немений (Nemenyi), он же фактически тест множественного сравнения с наилучшим (MCB - Multiple comparison with the best).
Первый может быть полезен, если прогнозисту нужно сравнить два прогноза и понять, отличаются ли они существенно друг от друга. Вместо прогнозов, впрочем, можно использовать какие-нибудь ошибки прогнозов (например, MAPE, MASE, GMRAE) для того, чтобы понять, лучше ли один из методов работает, чем другой. Ошибки обычно распределены ненормально, разности между ошибками разных методов -- тем более, поэтому тест подходит к этой задаче достаточно хорошо.
Гипотеза в тесте Уилкоксона формулируется не очень чётко. Нулевая заключается в том, что две модели дали ошибки, статистически неразличимые друг от друга. Альтернативная -- что различимые. Тест проводится в несколько шагов:
- Рассчитываются разности ошибок между первой и второй моделями. Обозначим их как \(\Delta_j\), где \(j\) -- номер ошибки;
- Значения, для которых \(\Delta_j\) равны нулю убираются;
- Записываются модули разностей (\(| \Delta_j |\)) и их знаки (\(\text{sgn}(\Delta_j)\));
- Значения \(| \Delta_j |\) ранжируются от меньшего к большему, в случае одинаковых рангов, даётся среднее число из соседних. Например, если после числа проранижрованного как 2 идёт два числа с одинаковым рангом, то каждому из них присваивается ранг 3.5 (вместо 3 и 4). В результате этого получается ряд рангов \(R_j\);
- По волшебной формуле рассчитывается статистика Уилкоксона: \(W = \sum_{j=1}^n \left( R_j \cdot \text{sgn}(\Delta_j) \right)\);
- Полученное на предыдущем шаге значение сравнивается с критическим (для заданного уровня остаточной вероятности \(\alpha\)), после чего делается вывод относительно проверяемой гипотезы.
В случае с большим числом наблюдений (скажем, больше 50), вместо статистики Уилкоксона можно использовать нормальное распределение. Для этого нужно рассчитать дисперсию по следующей формуле: \(\sigma_W^2 = \frac{n (n+1) (2n+1)}{6}\). Следующий шаг в данном случае -- фактически проверка нулевой гипотезы о том, что \(W = 0\) с помощью z-теста:
\begin{equation} \label{eq:msh_hypothesis_test_W}
z = \frac{W}{\sigma_W} .
\end{equation}
Фактически проводя этот тест, мы пытаемся оценить, имеют ли два распределения случайных величин идентичные распределения. Если ошибки первой и второй моделей близки друг к другу, то их разности \(\Delta_j\) будут близки к нулю, а это в свою очередь значит, что положительные и отрицательные ранжированные значения будут друг друга уничтожать, что приведёт к тому, что итоговое значение \(W\) будет близко к нулю. Если же разница в ошибках велика, то и дальше от нуля будет находится значение \(W\).
Всё так же, как и с проверкой любых других гипотез, отклонение либо не отклонение нулевой гипотезы не говорит о том, что разница есть или же отсутствует. Это только говорит о том, что полученные данные противоречат / не противоречат данной гипотезе.
Тест Nemenyi в нашей дисциплине обычно используется для сравнения нескольких методов прогнозирования между собой на основе ошибок прогноза (см. параграф Оценка качества прогнозных моделей). Нулевая гипотеза в этом тесте может меняться в зависимости от того, что интересует исследователя. Простейший вариант -- распределения нескольких случайных величин идентичны. В этом смысле тест похож на тест Уилкоксона, однако он позволяет сравнивать несколько (больше двух) моделей, и его можно легко визуализировать.
Давайте предположим, что в нашем распоряжении оказалось 1000 рядов данных, по которым мы оценили 5 моделей. После этого мы дали прогнозы по этим моделям и собрали соответствующие ошибки. Для того, чтобы провести тест Nemenyi нам теперь нужно для каждого ряда ранжировать модели, выставив 1 модели с наименьшей ошибкой и 5 -- с наибольшей. В результате этого мы получаем таблицу 1000x5 с моделями в столбцах и рядами в строках. Следующим шагом мы рассчитываем средние ранги \(\bar{R}_j\) для каждой модели \(j\) и строим интервалы на основе распределения студентизированного размаха (студентизированный размах был предложен Уильямом Госсетом и рассчитывается как стандартизированная разность между максимальным и минимальным значениями случайной величины). В этом случае используется следующая формула для расчёта нижней и верхней границ:
\begin{equation} \label{eq:msh_hypothesis_Nemeyi_intervals}
\left(\bar{R}_j -q_{\alpha,k} \sqrt{\frac{K (K+1)}{12 N}} ,\bar{R}_j +q_{\alpha,k} \sqrt{\frac{K (K+1)}{12 N}} \right) ,
\end{equation}
где \(K\) -- это число моделей (в нашем случае \(K=5\)), \(N\) -- число рядов (у нас \(N=1000\)), \(q_{\alpha,k}\) -- значение упомянутой выше статистики, а \(\alpha\) -- уровень остаточной вероятности.
Рассчитав доверительные интервалы для каждой из пяти моделей, мы можем нанести их на один график и оценить визуально, отличимы ли статистически друг от друга прогнозы, полученные с помощью этих моделей. При этом манипулирование числом моделей \(K\) может приводить к разным результатам: при малом \(K\) разница может быть статистически значимой, при большом -- незначимой. В то же время с увеличением числа рядов \(N\) различия между прогнозами по разным моделям становятся всё более и более значимыми.
x1 <- rnorm(1000,0.6,1) x2 <- rnorm(1000,0.5,1) x3 <- rnorm(1000,1.5,1) x4 <- rnorm(1000,1,1) x5 <- rnorm(1000,2,1)
Объединим их в таблицу:
ourtable <- cbind(x1,x2,x3,x4,x5)
colnames(ourtable) <- c("x1","x2","x3","x4","x5")
Теперь проведём тест и попросим его сделать графики в стиле "MCB":
tsutils::nemenyi(ourtable,plottype="mcb")
В результате этого мы получим несколько строк о рангах, средних значениях и интервалах, а так же график, на подобии следующего:
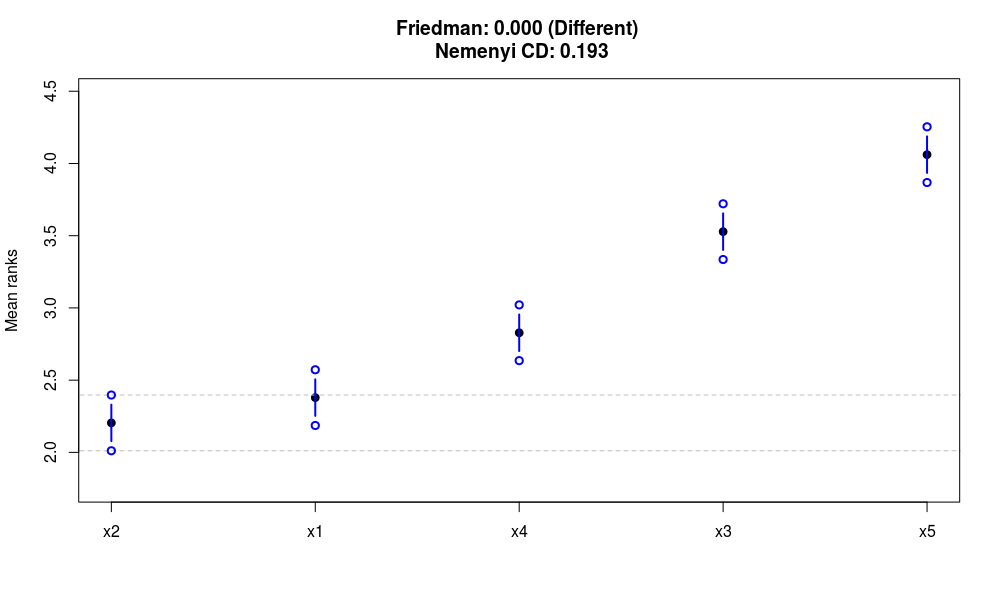
Nemenyi тест для условного примера
В связи с тем, что у распределения x1 и x2 средние величины близки друг к другу (0.5 и 0.6), полученный график демонстрирует, что ошибки прогнозов моделей x1 и x2 статистически не различимы. Кроме того, видно, что ошибка прогноза модели x2 оказалась статистически ниже ошибок прогнозов моделей x3, x4 и x5. Это указывает на то, что на 5% уровне остаточной вероятности модель x2 даёт более точные прогнозы, чем модели x3, x4 и x5.
Конечно же, рассмотренные здесь тесты могут применяться (и применяются) не только для сравнения точности прогнозов разных моделей. Однако для нас применение их в других областях не представляет особый интерес.
Важные особенности математической статистики
Подводя итоги данного параграфа, хотелось бы обратить внимание не несколько важных нюансов.
Во-первых, при проверке статистических гипотез не стоит забывать, что мы никогда не получаем однозначного ответа. Результаты никогда ничего не доказывают, а лишь призваны уменьшить неопределённость относительно интересующего нас вопроса. В некоторых случаях эту неопределённость можно сократить до несущественной, но она никуда никогда не денется. Достичь такого сокращения можно путём увеличения числа наблюдений, однако здесь уже нужно учитывать предпосылки относительно распределений случайных величин и их независимости. Именно последний элемент может поставить крест на проверке любых гипотез при работе с временными рядами, так как достаточно часто наблюдения оказываются зависимыми друг от друга. Кроме того, процессы, с которыми приходится сталкиваться в прогнозировании, частенько носят необратимый характер, что приводит к нарушению всех предпосылок и не позволяет эффективно проводить проверку гипотез.
Во-вторых, все распрекрасные статистические свойства оценок проявляются только ассимптотически. Это, впрочем, может оказаться полезным и на малых выборках, так как у исследователя хотя бы появляется представление о том, чего ждать от того или иного метода оценки, если размер выборки будет меняться.
В-третьих, не стоит забывать о том, что такое вероятность. Тот факт, что оценка вероятности приближается к истиной ассимптотически может быть критически важен при работе с реальными данными (которых на практике обычно не так много). Из-за этого полученные p-value могут не отражать реальной ситуации. Тем более на малых выборках!
Напоследок хотелось бы привести список замечаний по поводу того, что такое p-value, составленный Американской статистической ассоциацией. Он обязателен к прочтению всем исследователям, работающим с p-value.
- p-value может показать, насколько данные не соответствуют выбранной модели.
- p-value не измеряет, насколько гипотеза верна. Это вообще утверждение не о самой гипотезе, а о том, насколько данные ей соответствуют.
- Выводы только на основе p-value делать нельзя. Это не бинарный выбор, мы имеем дело с вероятностями, поэтому для принятия решения нужна дополнительная информация. Нельзя убирать из регрессии или оставлять в ней переменные лишь на основе того, что вероятность оказалась меньше 0.05.
- При проведении исследований нужно предоставлять несколько альтернативных гипотез и сообщать обо всех полученных p-value, а не только о тех, которые оказались выше какого-то порогового значения. В противном случае происходит искажение информации из-за неполноты данных.
- p-value не измеряет размер эффекта либо важность результата. Меньшие значения p-value не говорят о том, что что-то имеет больший эффект или большую важность. Сравнивать одно p-value с другим нельзя. Точно так же нельзя сравнивать расчётные значения статистик разных моделей.
- Сама по себе p-value не является хорошей мерой доказательства гипотезы. Без контекста и дополнительных данных, она даёт очень ограниченную информацию. Анализ ни в коем случае не должен заканчиваться лишь значениями p-value.
Ну, и вместо заключения. Практически все современные исследования в области медицины, психологии, социологии, экономики и т.п. основаны на проверке статистических гипотез. Для получения адекватного и научно обоснованного результата в этих дисциплинах обычно стараются следить за выполнением предпосылок, которые мы обсудили в этом параграфе. Это, впрочем, не означает, что исследователи всегда выполняют хорошую работу. Поэтому, когда в очередной раз вы услышите, что-нибудь типа "Британские учёные доказали, что потребление молока повышает стрессоустойчивость" - имейте в виду: кто-то собрал данные, провёл статистический тест и проверил гипотезу. p-value оказалась ниже заданной остаточной вероятности. Что это значит на самом деле, вы теперь знаете.