



Голая теория
В прошлый раз мы обсуждали аддитивные модели экспоненциального сглаживания, сегодня пришла пора мультипликативных.
Вообще в среде прогнозистов имеется некоторый скепсис по поводу мультипликативных моделей экспоненциального сглаживания. Нет, конечно, когда речь заходит о типе сезонности, многие скажут, что нужно использовать мультипликативную, и будут правы (очень многие ряды имеют такой характер сезонности). Однако в случае с трендом, уровнем ряда и ошибкой не всё так однозначно и понятно. Зачем на самом деле умножать уровень на тренд и на ошибку? Что это даёт? Жизнь усложняет, это само собой. Математические выкладки усложняет, это тоже. Точность прогнозов при этом не обязательно возрастает. В общем, проблем добавляется, а результат не очевиден.
Вы спросите меня, зачем тогда вообще эти модели нужны? На то существует как минимум одна причина. Мультипликативные модели подразумевают, что данные, с которыми мы работаем всегда положительны. Это очень полезное свойство, когда нам, например, нужно спрогнозировать уровень продаж, потому что продать -51 ботинок в Апреле 2017 года в принципе невозможно (если не брать в расчёт какие-нибудь технические ошибки). Это и есть та самая причина, по которой мультипликативные модели могут быть нужны.
Давайте посмотрим, в чём их особенность.
Компоненты таких моделей могут быть записаны с помощью натуральных логарифмов в форме, похожей на ту, что мы уже обсуждали:
\begin{equation} \label{eq:ssGeneralMultiplicative}
\begin{matrix}
y_t = \exp \left(w’ \log(v_{t-l}) + \log(1+\epsilon_t) \right) \\
\log(v_t) = F \log(v_{t-l}) + \log (1 + g \epsilon_t)
\end{matrix} .
\end{equation}
Все обозначения мы уже ввели в предыдущей статье, так что здесь опять обсуждать не будем. Единственное, на что хотелось бы обратить внимание — это то, что функции \(\exp\) и \(\log\) здесь применяются к векторам поэлементно. То есть \(\log(v_t)\) будет давать вектор, в котором каждая из компонент прологарифмирована. Важно отметить, что все компоненты модели должны быть положительными, иначе она работать не будет.
Модель \eqref{eq:ssGeneralMultiplicative} позволяет записать любые мультипликативные модели в компактной форме. Например, модель с мультипликативным трендом и мультипликативной ошибкой ETS(M,M,N) может быть записана так:
\begin{equation} \label{eq:ssETS(M,M,N)}
\begin{matrix}
y_t = \exp \left(\log(l_{t-l}) + \log(b_{t-l}) + \log(1 + \epsilon_t) \right) \\
\log(l_t) = \log(l_{t-l}) + \log(b_{t-l}) + \log (1 + \alpha \epsilon_t) \\
\log(b_t) = \log(b_{t-l}) + \log (1 + \beta \epsilon_t)
\end{matrix} .
\end{equation}
Если теперь взять экспоненту во втором и третьем уравнениях в \eqref{eq:ssETS(M,M,N)}, а также упростить первое, то получится вот такая модель, которая лежит в основе метода Пегельса:
\begin{equation} \label{eq:ssETS(M,M,N)_Pegels}
\begin{matrix}
y_t = l_{t-l} b_{t-l} (1 + \epsilon_t) \\
l_t = l_{t-l} b_{t-l} (1 + \alpha \epsilon_t) \\
b_t = b_{t-l} (1 + \beta \epsilon_t)
\end{matrix} .
\end{equation}
Как видим, форма \eqref{eq:ssGeneralMultiplicative} универсальна и объединяет в себе много разных моделей.
Итак, в чём же фишка? Из-за перемножения компонент итоговое значение всегда будет положительным. Однако, в данном случае важно, чтобы ошибка в \eqref{eq:ssGeneralMultiplicative} была распределена лог-нормально:
\begin{equation} \label{eq:ssErrorlogN}
(1 + \epsilon_t) \sim \text{log}\mathcal{N}(0,\sigma^2),
\end{equation}
здесь \(\sigma^2\) это дисперсия логарифма ошибки \(1 + \epsilon_t\). Почему именно такое распределение? Если эта дисперсия невелика, то, в принципе, совершенно неважно, распределена ли ошибка нормально или лог-нормально, так как оба распределения в этом случае оказываются очень близкими друг к другу. Однако, когда дисперсия становится выше, различия становятся более ощутимыми, хвост лог-нормального распределения становится более длинным. В этом случае допущение о нормальности распределения становится некорректным, так как ошибка \(1 + \epsilon_t\) из-за высокой дисперсии может становиться отрицательной, что делает модель \eqref{eq:ssGeneralMultiplicative} непригодной для прогнозирования. Поэтому допущение \eqref{eq:ssErrorlogN} важно для этой модели.
Само предположение \eqref{eq:ssErrorlogN} приводит к следующим результатам.
Во-первых, с высокой дисперсией и низкими фактическими значениями модель даёт медианные прогнозы, а не средние. Нет, конечно, средние тоже можно дать, но сделать это сложнее, да и особо не имеет смысл, так как медиана более робастна в случаях с асимметричными распределениями. Это всё становится особенно важным в случае с целочисленным спросом, до которого мы когда-нибудь, возможно, доберёмся.
Во-вторых, прогнозные интервалы оказываются несимметричными как раз из-за предположения \eqref{eq:ssErrorlogN}. Это, опять же, становится более заметно в рядах данных с высокой дисперсией и низким уровнем ряда. В противном случае разницы между интервалами, построенными с помощью мультипликативной и аддитивной моделями, не будет практически никакой.
Ну, и, в-третьих, оценка параметров модели должна осуществляться иначе. Целевая функция для этих моделей может быть выведена из следующей логарифмированной функции правдоподобия:
\begin{equation} \label{eq:ssConcentratedLogLikelihoodLnorm}
\ell(\theta | Y) = -\frac{T}{2} \left( \log \left( 2 \pi e \right) +\log \left( \hat{\sigma}^2 \right) \right) -\sum_{t=1}^T \log y_t ,
\end{equation}
где дисперсия \(\hat{\sigma}^2 = \frac{1}{T} \sum_{t=1}^T \log^2(1 + \epsilon_{t})\). Целевая функция в этом случае будет иметь вид:
\begin{equation} \label{eq:ssCostFunction}
\text{CF} = \log \left( \hat{\sigma}^2 \right) + \frac{2}{T} \sum_{t=1}^T \log y_t .
\end{equation}
Штуки в R
Наглядным примером того, в чём преимущества мультипликативной модели, является ряд N2457 из базы M3. Несмотря на то, что уровень ряда достаточно велик (в среднем что-то около 5000), дисперсия в нём так же велика. Это указывает на то, что предпочтение стоит отдать мультипликативной модели. Попробуем построить модель ETS(M,N,N) с параметрическими прогнозными интервалами:
es(M3$N2457$x, "MNN", h=18, holdout=TRUE, intervals="p")
Получим вот что:
Time elapsed: 0.1 seconds
Model estimated: ETS(MNN)
Persistence vector g:
alpha
0.145
Initial values were optimised.
3 parameters were estimated in the process
Residuals standard deviation: 0.413
Cost function type: MSE; Cost function value: 1288657
Information criteria:
AIC AICc BIC
1645.978 1646.236 1653.702
95% parametric prediction intervals were constructed
72% of values are in the prediction interval
Forecast errors:
MPE: 26.3%; Bias: 87%; MAPE: 39.8%; SMAPE: 49.4%
MASE: 2.944; sMAE: 120.1%; RelMAE: 1.258; sMSE: 242.7%
Мы уже обсуждали в предыдущей статье, что значит каждая из этих строчек, так что останавливаться на этом не будем. Самой важной строкой для нас является «Residuals standard deviation: 0.413», в которой говорится о том, что стандартное отклонение остатков модели составило 0.413. То есть дисперсия модели составила что-то порядка 0.17. Это, на самом деле, достаточно много для мультипликативной модели и указывает на несимметричность распределения остатков, что находит отражение в следующих прогнозных интервалах:
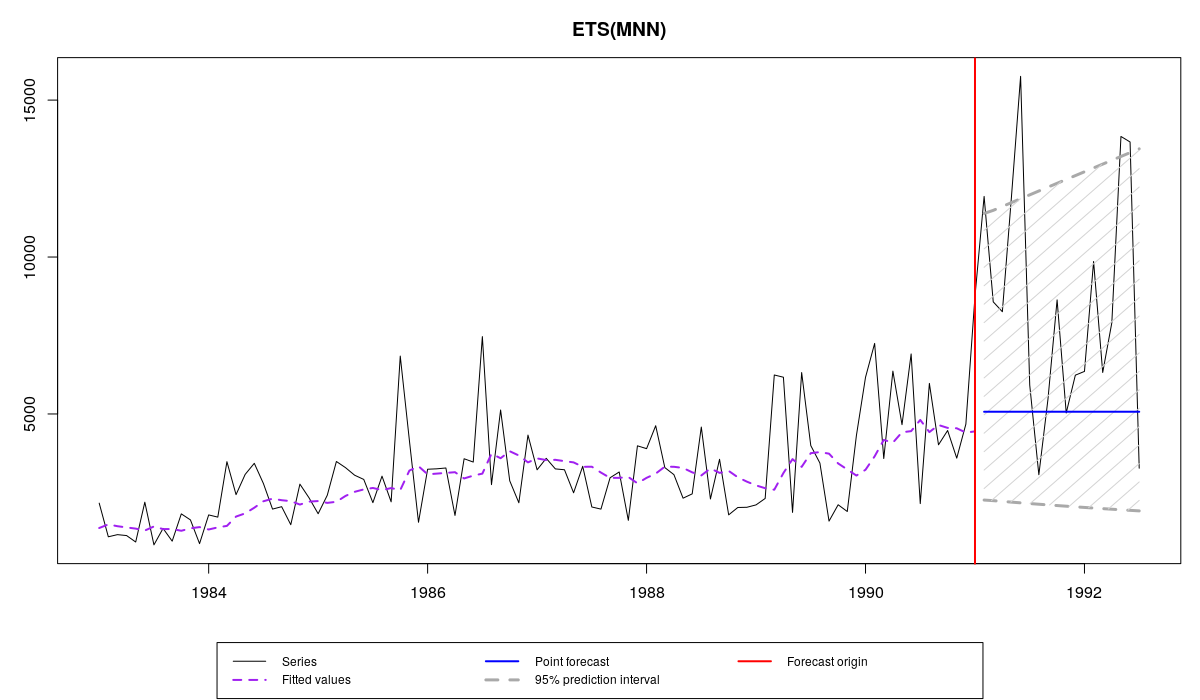
Ряд N2457 из M3 и прогноз и интервал по модели es(«MNN»)
Если бы мы построили модель с аддитивной ошибкой, ETS(A,N,N), то получили бы вот что:
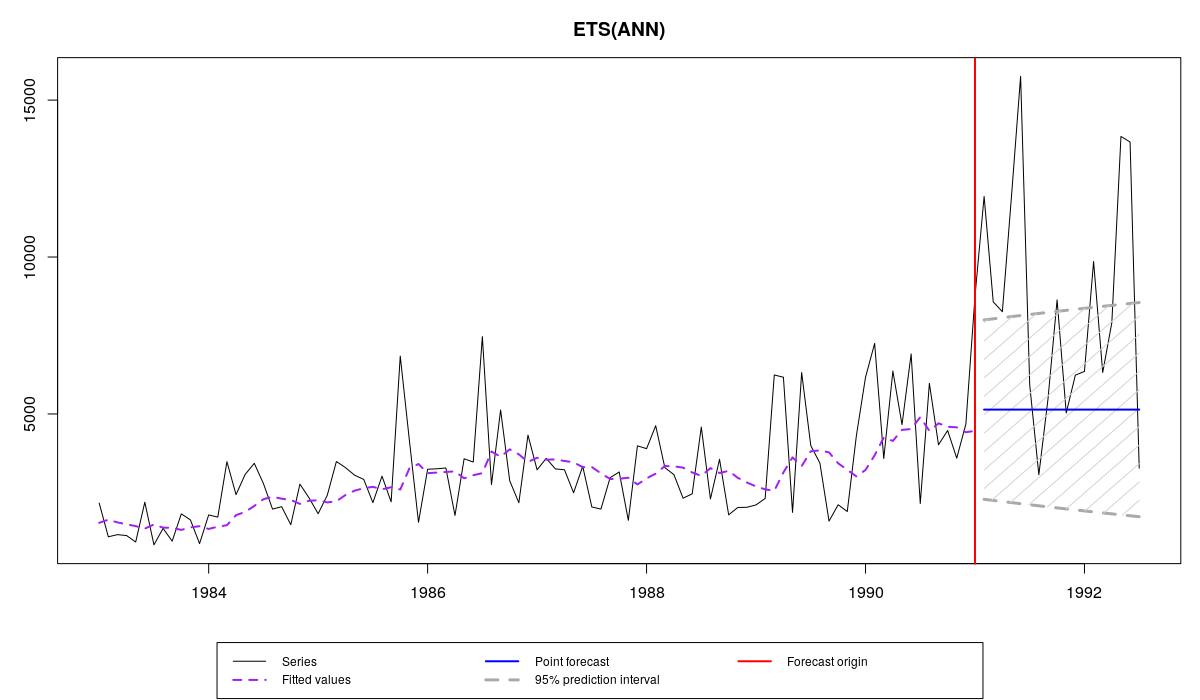
Ряд N2457 из M3 и прогноз и интервал по модели es(«ANN»)
Если сравнить эти два графика, то мы заметим, насколько отличаются у двух моделей прогнозные интервалы. Более того, у первой прогнозный интервал оказался более адекватным и накрыл большее число наблюдений, чем у второй. Как видим, в подобных ситуациях мультипликативные модели оказываются полезными.
Ну, и для очистки совести пример, в котором разница между аддитивной и мультипликативной моделями практически отсутствует. Это ряд N2348:
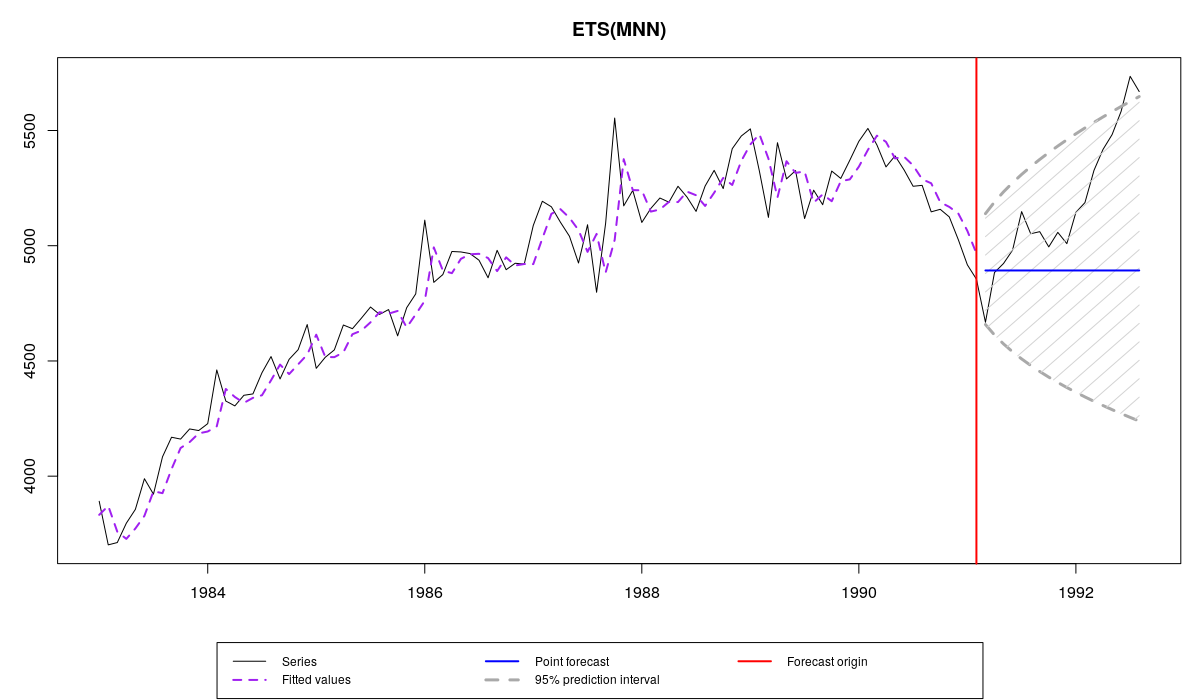
Ряд N2348 из M3 и прогноз и интервал по модели es(«MNN»)
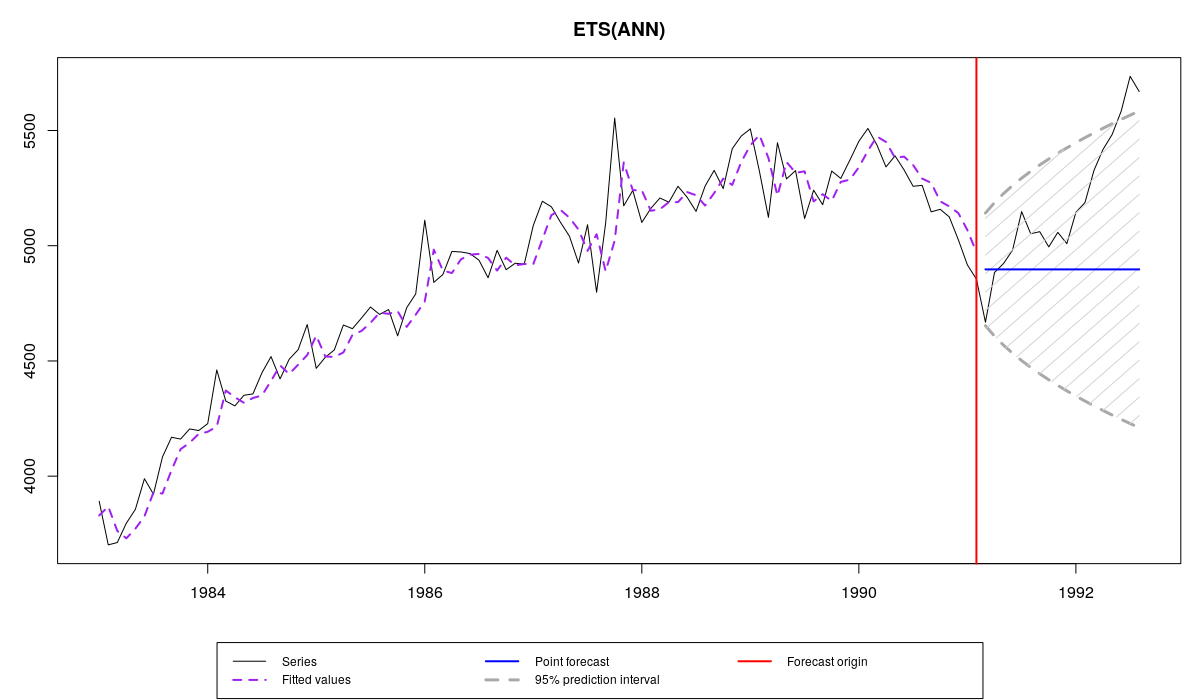
Ряд N2348 из M3 и прогноз и интервал по модели es(«ANN»)
Как видим, прогнозные интервалы и точечные прогнозы у обеих моделей оказались очень схожими. В таких случаях не настолько важно, какой модели отдать предпочтение, можно выбрать ту, с которой удобней работать.
Вот такие дела.