



Немного статистики
Как уже упоминалось в предыдущей статье, для пакета «smooth» написана документация с подробный объяснением всех моделей, лежащих в основе функций. Здесь мы обсудим несколько основных аспектов, касающихся функции es(). Сегодня мы обсудим аддитивные модели. У этих моделей все компоненты представлены не в мультипликативном виде, что облегчает их понимание и построение.
Функция es() использует математическую модель пространства состояний (State-Space model, к которой мы, возможно, когда-нибудь доберёмся в учебнике на этом сайте) с единым источником ошибки (Single Source of Error). Практически все основные элеименты модели взяты из книги Hyndman et al. (2008). Преимущество этой модели заключается в том, что она позволяет записать в компактной форме любой метод экспоненциального сглаживания. Однако модель, лежащая в основе функции es() имеет несколько отличий по сравнению с обсуждаемой в упомянутой выше книге. Одно из важнейших отличий заключается в том, как моделируют сезонные компоненты у нас и у них: в то время, как они используют фиктивные переменные, мы используем для тех же целей лаговые. Есть и другие отличии, но мы о них поговорим несколько позже.
Сегодня мы обсуждаем аддитивную модель. Записывается она следующим образом:
\begin{equation} \label{eq:ssGeneralAdditive}
\begin{matrix}
y_t = w’ v_{t-l} + \epsilon_t \\
v_t = F v_{t-l} + g \epsilon_t
\end{matrix} ,
\end{equation}
где \(y_{t}\) — это фактическое значения на наблюдении \(t\), \(v_{t}\) — это вектор состояний (содержащий в себе компоненты временного ряда, такие как уровень ряда, тренд и сезонность), \(w\) и \(F\) — это заданные измерительный вектор и матрица переходов, а \(g\) — это вектор постоянства (не знаю, как его правильно перевести… В общем, он в себе содержит постоянные сглаживания). Наконец, \(\epsilon_t\) — это ошибка модели, относительно которой, в случае с аддитивной моделью, обычно делают предположение о том, что она распределена нормально.
Используя эти обозначения, любая аддитивная модель экспоненциального сглаживания может быть записана в виде \eqref{eq:ssGeneralAdditive}. Например, модель с демпфированным трендом, обозначающаяся обычно так же как ETS(A,Ad,N), имеет следующую структуру:
\begin{equation} \label{eq:ssAAdNMatrices}
w = \begin{pmatrix}
1 \\ \phi
\end{pmatrix},
F = \begin{pmatrix}
1 & \phi \\
0 & \phi
\end{pmatrix},
g = \begin{pmatrix}
\alpha \\
\beta
\end{pmatrix},
v_t = \begin{pmatrix}
l_t \\
b_t
\end{pmatrix},
v_{t-l} = \begin{pmatrix}
l_{t-1} \\
b_{t-1}
\end{pmatrix} .
\end{equation}
Подставляя эти значения в \eqref{eq:ssGeneralAdditive}, мы получим модель, которая, возможно, известна некоторым из вас:
\begin{equation} \label{eq:ssAAdN}
\begin{matrix}
y_t = l_{t-1} + \phi b_{t-1} + \epsilon_t \\
l_t = l_{t-1} + \phi b_{t-1} + \alpha \epsilon_t \\
b_t = \phi b_{t-1} + \beta \epsilon_t
\end{matrix} ,
\end{equation}
где \(l_t\) — уровень ряда, \(b_t\) — тренд, \(\phi\) — параметр демпфирования тренда, \(\alpha\) и \(\beta\) — параметры сглаживания. Эта же модель приведена в упомянутом уже дважды учебнике. Так что модели без сезонности, реализованные в es() не отличаются практически ничем от несезонных моделей функции ets() пакета forecast. Однако различия начинают проявляться, когда мы обращаемся к сезонным компонентам…
Если вы обратили внимание, у вектора \(v_{t-l}\) в \eqref{eq:ssGeneralAdditive} есть индекс \(l\), который мы ещё не обсудили. Этот индекс указывает на то, что компоненты временного ряда могут иметь разные лаги. Например, сезонная компонента будет иметь какой-нибудь лаг \(m\) (в случае с месячными данными \(m=\)12), в то время как все остальные будут использоваться с лагом 1. Например, простая аддитивная сезонная модель ETS(A,A,A) имеет в нашей реализации следующую структуру вектора состояний:
\begin{equation} \label{eq:ssETS(A,A,A)StateVector}
v_{t-l} =
\begin{pmatrix}
l_{t-1} \\
b_{t-1} \\
s_{t-m}
\end{pmatrix} ,
\end{equation}
где, как видим, уровень и тренд имеют лаг 1, а сезонная компонента имеет лаг \(m\). Если мы теперь подставим значения \eqref{eq:ssETS(A,A,A)StateVector} в \eqref{eq:ssGeneralAdditive}, то мы получим широко известную в узких кругах аддитивную модель Хольта-Уинтерса:
\begin{equation} \label{eq:ssETS(A,A,A)}
\begin{matrix}
y_t = l_{t-1} + b_{t-1} + s_{t-m} + \epsilon_t \\
l_t = l_{t-1} + b_{t-1} + \alpha \epsilon_t \\
b_t = b_{t-1} + \beta \epsilon_t \\
s_t = s_{t-m} + \gamma \epsilon_t
\end{matrix} .
\end{equation}
В случае с моделями из книги Hyndman et al. (2008) в \eqref{eq:ssETS(A,A,A)} нужно было бы добавить \(m-1\) сезонную компоненту, каждая из которых не обновлялась бы на данном наблюдении. Суть модели бы не поменялась, но размер её увеличился бы. По сути, используя лаговую структуру, мы уменьшаем размеры \(v_t, w, F\) и \(g\), что позволяет упростить некоторые выкладки и требует проводить по-другому нормализацию сезонных компонент (не как в четырежды упомянутой книге). Финальные прогнозы от использования такой структуры могут быть другими, но незначительно, все статистические свойства модели сохраняются. Например, концентрированная логарифмированная функция правдоподобия для неё считается точно так же, как и для оригинальной ETS:
\begin{equation} \label{eq:ssConcentratedLogLikelihoodNorm}
\ell(\theta | Y) = -\frac{T}{2} \left( \log \left( 2 \pi e \right) +\log \left( \hat{\sigma}^2 \right) \right),
\end{equation}
где \(\theta\) — это вектор параметров модели, а \(T\) — число наблюдений. Функция правдоподобия \eqref{eq:ssConcentratedLogLikelihoodNorm} может быть использована для оценки параметров модели, а так же для расчёта информационных критериев и выбора оптимальной модели.
Пара примеров в R
Впрочем, хватит всякой статистики и непонятных слов. Посмотрим, как оно работает. Для наших примеров мы будем использовать временные ряды из базы M3, которая доступна в пакете «Mcomp» для R, так что не забудьте его установить и загрузить (library(Mcomp)).
Начнём с оценки модели по ряду N1234. В этом ряде имеется явные возрастающий тренд, а для прогнозирования таких рядов имеет смысл обратиться к модели демпфированного тренда (об этом нам говорит научная литература). Сделаем это с помощью команды:
es(M3$N1234$x, "AAdN", h=8, intervals=TRUE)
В результате этого мы получим две вещи: вывод функции и следующий график:
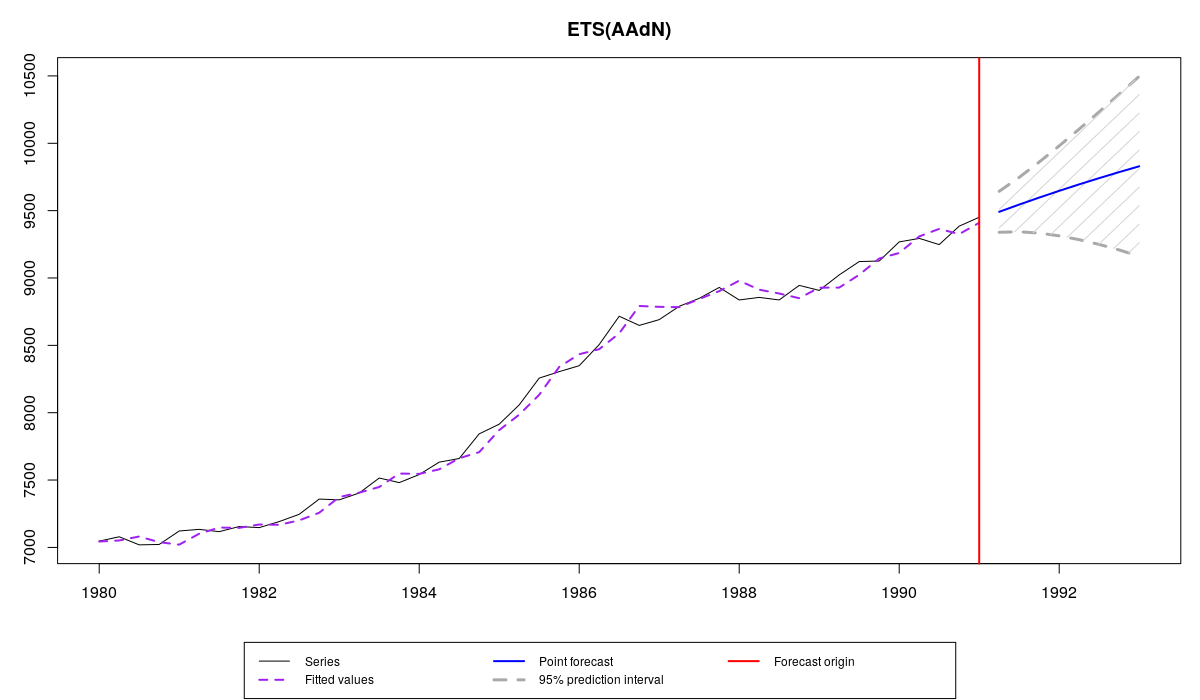
Ряд N1234 из базы M3 и прогноз с помощью es()
Если график вам ненужен, то можете попросить функцию его не выводить с помощью параметра silent=»graph». Если вам ненужно, чтобы функция что-либо печатал по итогам работы, то это можно сделать так:
ourModel <- es(M3$N1234$x, "AAdN", h=8, intervals=TRUE, silent="graph")
В случаях с выбором наилучшей модели и комбинированием прогнозов (которые мы обсудим позже), может быть полезно указать, чтобы функция вообще заткнулась и ничего не выводила. Для этого надо задатьsilent="all" или silent=TRUE.
Итак, что же там у нас получилось в выводе? А вот что:
Time elapsed: 0.15 seconds
Model estimated: ETS(AAdN)
Persistence vector g:
alpha beta
0.623 0.26
Damping parameter: 0.964
Initial values were optimised.
6 parameters were estimated in the process
Residuals standard deviation: 75.206
Cost function type: MSE; Cost function value: 4902
Information criteria:
AIC AICc BIC
522.0857 524.2962 532.9256
95% parametric prediction intervals were constructed
Первые две строки говорят нам о том, сколько времени ушло на работу функции и какую модель мы оценили.
"Persistence vector g" - это тот самый вектор постоянства с постоянными сглаживания из \eqref{eq:ssGeneralAdditive}. В нашем случае он содержит две постоянные сглаживания (для уровня и для тренда).
"Damping parameter" показывает значение параметра демпфирования тренда.
Фраза "Initial values were optimised" говорит о том, что стартовые значения вектора состояний \(v_0\) были оптимизированы. Альтернативные варианты - это инициализация с помощью механизма обратного прогноза (backcast) или задание этих значений вручную пользователем.
Далее нам говорят о том, что при построении модели было оценено 6 параметров ("6 parameters were estimated in the process"). В них входят: 2 постоянные сглаживания, 2 стартовых значения, 1 параметр демпфирования и 1 оценённая дисперсия. Дисперсия тут считается для корректного учёта степеней свободы модели.
За этой строкой нам приводят значение стандартного отклонения ошибок, которое составило 75.206. Это несмещённая оценка стандартного отклонения, учитывающая количество степеней свободы и рассчитывающаяся по формуле:
\begin{equation} \label{eq:sd_Value}
s = \sqrt{\frac{1}{T-k} \sum_{t=1}^T e_t },
\end{equation}
где \(k\) - это число параметров модели (в нашем случае - 6, как мы уже выяснили). Само по себе стандартное отклонение нам мало о чём говорит. Однако его можно, по идеи, использовать для сравнения разных моделей с аддитивной ошибкой.
Далее нам говорят, что в качестве целевой функции использовалась MSE, и приводят итоговое значение. Это чисто информация для любопытных.
Строка "Information criteria" и следующая за ней таблица - это значения информационных критериев. С помощью них можно выбрать наиболее подходящую модель для данного временного ряда.
Ну, и, наконец, нам написали о том, что функция так же построила 95% параметрические прогнозные интервалы.
Всё вот это вот, фактически, говорит нам о том, чего можно ожидать от итогового объекта ourModel, который по сути своей представляет собой список (list). Например, ourModel$model содержит в себе название модели, а прогнозы хранятся в ourModel$forecast. Обо всём этом написано подробно в помощи к функции в R.
Что ж, попробуй теперь усложнить себе жизнь и посмотрим, как модель себя ведёт на проверочной части выборки:
y <- ts(c(M3$N1234$x,M3$N1234$xx),start=start(M3$N1234$x),frequency=frequency(M3$N1234$x)) es(y, "AAdN", h=8, holdout=TRUE, intervals=TRUE)
Итоговый график похож на предыдущий, но теперь на нём ещё есть значения из проверочной выборки:
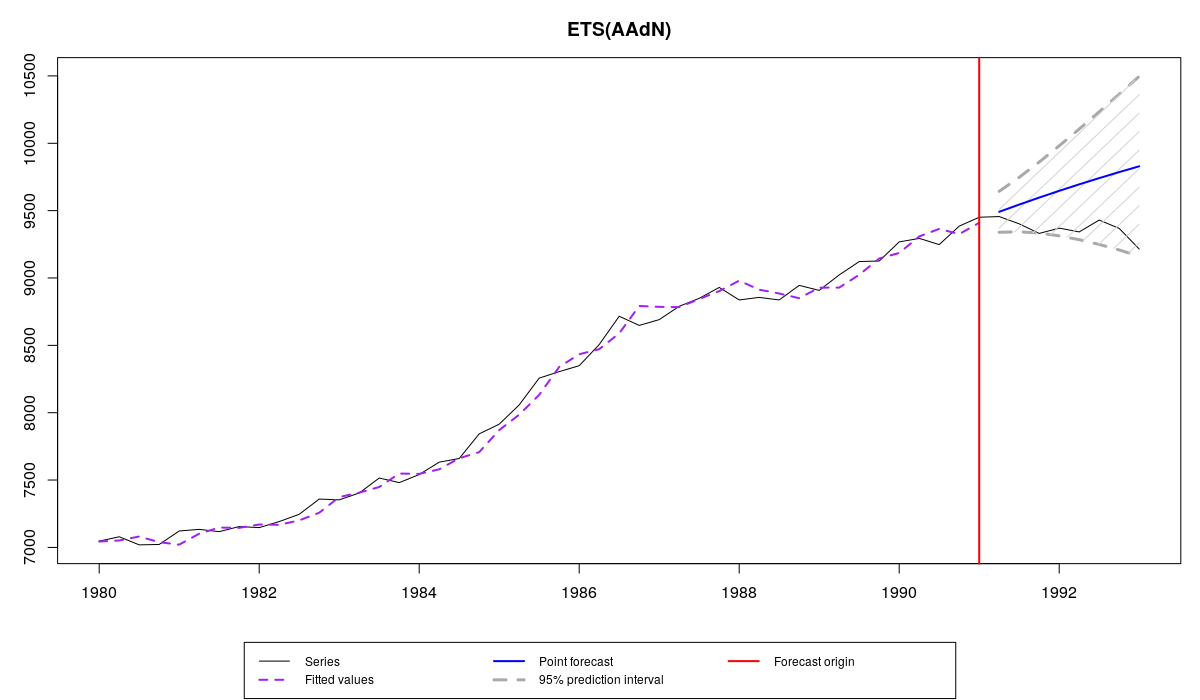
Ряд N1234 из базы M3, прогноз с помощью es() и фактические значения из проверочной выборки
Как видим, мы не сумели дать точный точечный прогноз ряда, однако прогнозные интервалы накрыли фактические значения, что указывает на то, что ещё не всё потеряно, и мы хотя бы правильно смогли оценить неопределённость. Что касается вывода в консоли, то у меня получилось следующее:
Time elapsed: 0.18 seconds
Model estimated: ETS(AAdN)
Persistence vector g:
alpha beta
0.623 0.260
Damping parameter: 0.964
Initial values were optimised.
6 parameters were estimated in the process
Residuals standard deviation: 75.206
Cost function type: MSE; Cost function value: 4902
Information criteria:
AIC AICc BIC
522.0857 524.2962 532.9256
95% parametric prediction intervals were constructed
88% of values are in the prediction interval
Forecast errors:
MPE: -3.2%; Bias: -100%; MAPE: 3.2%; SMAPE: 3.2%
MASE: 4.183; sMAE: 3.7%; RelMAE: 3.436; sMSE: 0.2%
Здесь помимо уже упомянутых ранее строк, появились строка о том, какой процент фактических значений оказались в прогнозном интервале (88%), а так же теперь представлены разные прогнозные ошибки, которые мы как-то обсуждали в учебнике. Единственная новая для нас - это Bias, которая измеряет симметричность распределения ошибки и лежит в пределах от -100% (прогноз оказался завышен) до 100% (систематическое занижение прогноза). Сами по себе ошибки мало о чём говорят (за исключением наверно, Bias и RelMAE: первая говорит о том, что мы сильно промахнулись с нашим прогнозом, вторая говорит о том, что простой метод Naive дал прогнозы в 3,436 раза более точные, чем по нашему методу), поэтому их стоит сравнивать с ошибками по другим моделям. Например, по модели ETS(A,A,N) у меня получились следующие ошибки:
MPE: -3.7%; Bias: -100%; MAPE: 3.7%; SMAPE: 3.6% MASE: 4.82; sMAE: 4.3%; RelMAE: 3.958; sMSE: 0.2%
Как видим, модель ETS(A,Ad,N) оказалась несколько точней, чем модель ETS(A,A,N).
Все эти прогнозные ошибки хранятся в объекте ourModel$accuracy в виде вектора. Кроме того, из-за того, что мы использовали параметр holdout=TRUE, нам стала доступна ещё одна переменная - фактические значения из проверочной части выборки: ourModel$holdout. Они могут быть использованы для расчёта каких-нибудь ещё ошибок. Ни в чём себе не отказывайте!
Чуть ранее мы упомянули про особенности сезонных моделей, так что давайте взглянем на какой-нибудь пример такой модели. Возьмём простую модель, без тренда, ETS(A,N,A) и построим её для ряда N1956:
ourModel <- es(M3$N1956$x, "ANA", h=18)
Получим вот такой график:
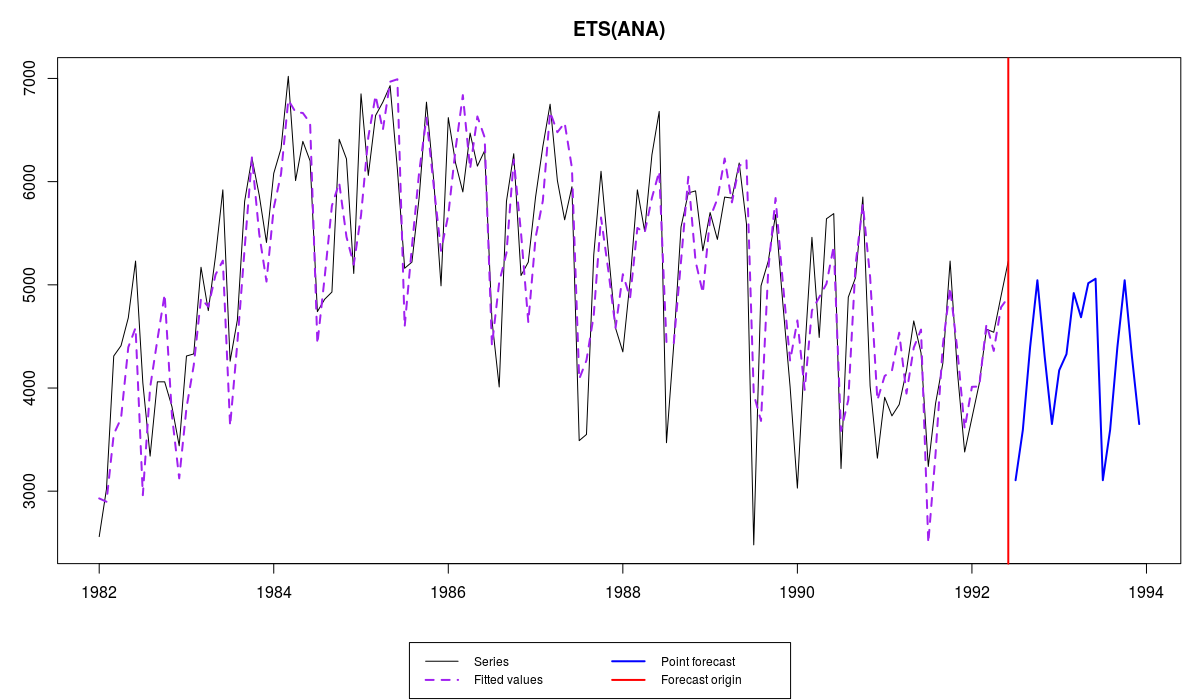
Ряд N1956 из базы M3 и его прогноз с помощью es()
Особо ничего по этому графику не скажешь кроме того, что выглядит всё достаточно адекватно. Если бы мы сравнили итоговую модель с оценённой с помощью ets(), мы бы заметили мелкие различия - постоянные сглаживания и стартовые значения, скорее всего, различались бы, стандартное отклонение ошибки было бы другим, информационные критерии так же отличались бы. Это в свою очередь влияет на прогнозы модели. Вот пример прогнозов, полученных с помощью функций es() и ets():
| h | es() | ets() |
| 1 | 3106.583 | 3105.761 |
| 2 | 3592.868 | 3580.976 |
| 3 | 4395.580 | 4389.775 |
| 4 | 5044.109 | 5052.459 |
| 5 | 4305.332 | 4364.522 |
| 6 | 3650.615 | 3733.528 |
Как видим, для некоторых наблюдений разницы практически нет никакой (например, для \(h=\)1). Однако есть несколько случаев, где отклонения оказываются чуть серьёзней (например, -82.913 при \(h=\)6). Впрочем, разница между прогнозами в среднем всё равно составляет не больше 0,431% от среднего уровня данных. Эти 0,431%, конечно, могут в итоге определить, что одна функция дала более точный прогноз, чем вторая, однако, какая из них лучше, сказать без проверочной выборки сложно.
Фух! На сегодня, пожалуй, всё. В следующий раз мы взглянем на мультипликативные модели - там есть важные различия по сравнению с моделями в основе ets().