



Предыдущие 6 статей мы обсуждали основные свойства функции es(). Пришло время двигаться дальше. Начиная с этой статьи мы обсудим параметры, общие для всех функций, реализованных в пакете smooth. К таким функциям относятся: es(), ssarima(), ces(), ges() и sma(). Однако, беря во внимание, что на данный момент мы обсудили только экспоненциальное сглаживанием, все примеры мы будем рассматривать на основе es().
Начнём с прогнозных интервалов.
Прогнозные интервалы функций пакета smooth
Одна из особенностей пакета smooth — это возможность конструировать разные типы прогнозных интервалов. Самый простой из них — это параметрические (включаются командой interval="p", interval="parametric" или interval=TRUE). Эти интервалы выводятся аналитически из свойств аддитивных и мультипликативных моделей. На данный момент (smooth v2.0.0) только в функции es() реализованы мультипликативные компоненты. Все остальные функции используют аддитивную модель. Это делает функцию es() этакой уникальной снежинкой. И если с чистыми аддитивными или мультипликативными моделями особых проблем нет, то со смешанными начинается головная боль.
В случае с моделями ETS с мультипликативной ошибкой, немультипликативными трендом и сезонностью и низкой дисперсией ошибок (ниже 0.1), интервалы аппроксимируются соответствующими моделями с аддитивной ошибкой. Например, интервалы для модели ETS(M,A,N) могут быть успешно аппроксимированы интервалами модели ETS(A,A,N), так как в случае с низкой дисперсией лог-нормальное распределение оказывается очень близким к нормальному. Все остальные смешанные модели используют симуляции для построения интервалов (с помощью функции sim.es()). Данные генерируются с заданными параметрами модели на \(h\) наблюдений. Процесс симуляции повторяется 10000 раз, так что в нашем распоряжении оказывается 10000 возможных дальнейших траекторий фактических значений. После этого вычисляются нужные квантили для каждого шага прогноза (с помощью функции quantile() из пакета stats) и возвращаются прогнозные интервалы. Конечно, такой метод нельзя считать чистым параметрическим, но в случае со смешанными моделями по другому либо просто нельзя, либо крайне сложно.
В функции es() так же доступны полупараметрические (semiparametric) и непараметрические (nonparametric) прогнозные интервалы. Оба типа этих интервалов основаны на траекторных прогнозных ошибках, которые получаются за счёт построения прогнозов на период от 1 до \(h\) шагов вперёд из каждого наблюдения в обучающей выборке. В результате этого в нашем распоряжении оказывается матрица с \(h\) столбцами и \(T-h\) строками. В случае с полупараметрическими интервалами (вызываются с помощью interval="sp" или interval="semiparametric") на основе этой матрицы рассчитывается \(h\) дисперсий, которые затем используются при построении интервалов на основе либо нормального, либо лог-нормального распределения (в зависимости от типа модели). Такие интервалы могут быть полезны в случае, если нарушаются базовые предпосылки о гомоскедастичности и не автокоррелированности остатков модели. Тем не менее мы всё ещё предполагаем, что у остатков есть какое-то параметрическое распределение (нормальное / лог-нормальное).
В случае с непараметрическими интервалами (вызываются в R через interval="np" или interval=»nonparametric») предпосылка о параметрическом распределении может быть опущена. В этом случае мы используем квантильные регрессии (аналогично тому, как это было сделано в Taylor and Bunn, 1999). В основе этих моделей лежит следующая степенная функция:
\begin{equation} \label{eq:ssTaylorPIs}
\hat{e}_{j} = a_0 j ^ {a_{1}},
\end{equation}
где \(j = 1, .., h\) — это горизонт прогнозирования. Преимуществом модели \eqref{eq:ssTaylorPIs} является отсутствие экстремумов для любых \(j>0\). Это означает, что прогнозные интервалы будут вести себя монотонно и не поменяют направление (в случае с полиномами мы можем получить очень странные интервалы с расширением, а затем — с сужением). Одновременно с этим, степенные функции позволяют аппроксимировать большой спектр возможных траекторий (в зависимости от параметров \(a_0\) и \(a_1\)), включая рост с замедлением, линейный рост или рост с ускорением.
Главная проблема непараметрических интервалов из пакета smooth заключается в том, что квантильные регрессии, лежащие в их основе, плохо себя ведут на малых выборках. Так для того, чтобы построить регрессию для 0.95 квантиля, нам нужно иметь как минимум 20 наблюдений. А для 0.99 квантиль — хотя бы 100. В случае, если в нашем распоряжении недостаточно наблюдений, прогнозные интервалы могут быть неточными и не соответствовать указанному номинальному уровню.
Заметим, что если пользователь строит прогноз на один шаг вперёд, то полупараметрические интервалы будут соответствовать параметрическим (так как в этом случае интервалы строятся на основе дисперсии на один шаг вперёд), а непараметрические интервалы конструируются с помощью функции quantile() пакета stats.
Ну, и последнее. Ширина прогнозных интервалов регулируется с помощью параметра level, который может быть задан как дробное число (level=0.95) либо как число в пределах от 0 до 100 (level=95). Я лично предпочитаю первый метод — второй нужен в основном для того, чтобы сделать функцию совместимой с функциями из пакета forecast. По умолчанию все прогнозные функции пакета smooth конструируют 95% прогнозные интервалы.
Существует ещё ряд особенностей при построении прогнозных интервалов для целочисленных моделей и кумулятивных прогнозов, но их мы пока касаться не будем.
Примеры в R
Рассмотрим построение интервалов на примере ряда N1241. Построим модель ETS(A,Ad,N) следующим образом:
ourModel1 <- es(M3$N1241$x, "AAdN", h=8, holdout=TRUE, interval="p") ourModel2 <- es(M3$N1241$x, "AAdN", h=8, holdout=TRUE, interval="sp") ourModel3 <- es(M3$N1241$x, "AAdN", h=8, holdout=TRUE, interval="np")
В результате мы должны получить следующие графики:
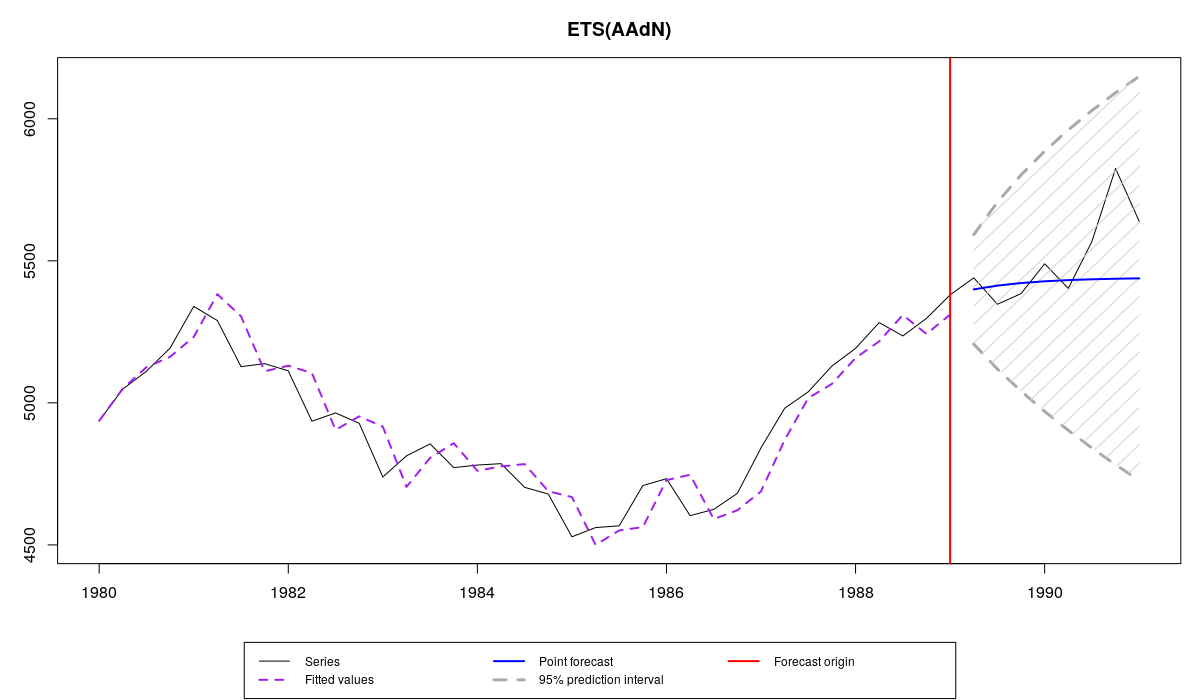
Ряд N1241 из базы M3, прогноз с помощью es(), фактические значения из проверочной выборки и параметрические прогнозные интервалы
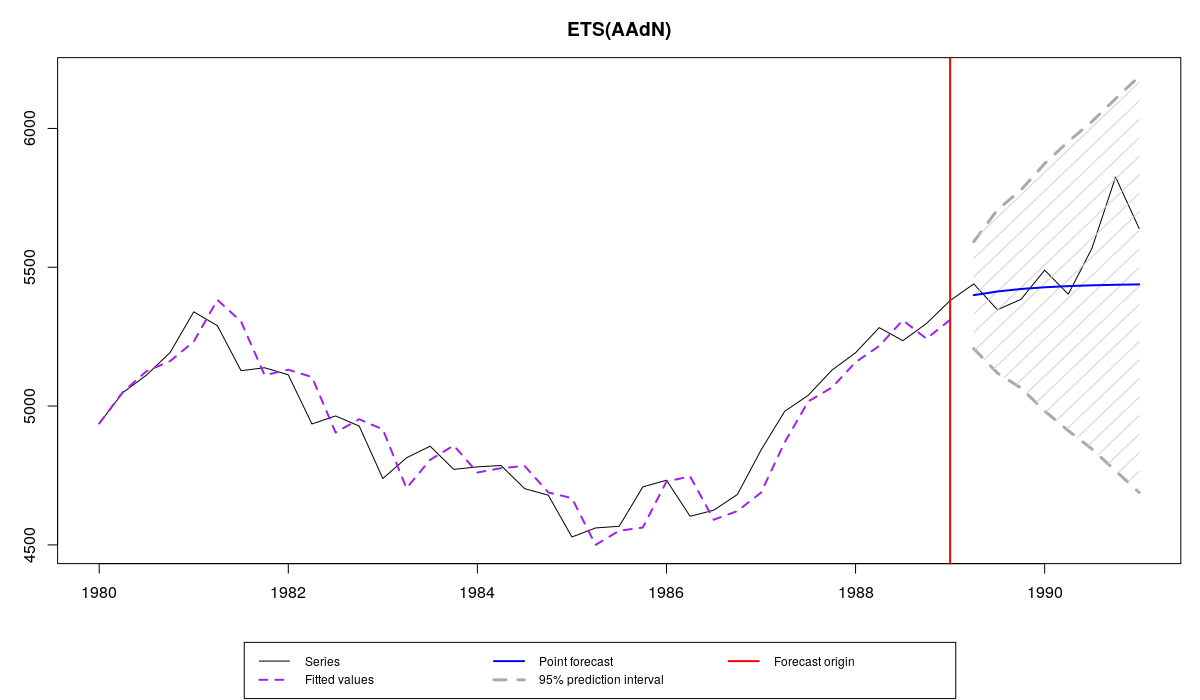
Ряд N1241 из базы M3, прогноз с помощью es(), фактические значения из проверочной выборки и полупараметрические прогнозные интервалы

Ряд N1241 из базы M3, прогноз с помощью es(), фактические значения из проверочной выборки и непараметрические прогнозные интервалы
Как видим, во всех случаях интервалы накрыли все фактически значения из тестовой выборки. В первую очередь это из-за того, что были построены широкие интервалы. В этих условиях совершенно непонятно, какому из методов отдать предпочтение. Для получения дополнительной информации об интервалах можно рассчитать их ширину в единицах следующим образом:
mean(ourModel1$upper-ourModel1$lower) mean(ourModel2$upper-ourModel2$lower) mean(ourModel3$upper-ourModel3$lower)
Получим:
950.4171 955.0831 850.614
В этом конкретном примере непараметрические интервалы оказались самыми узкими, что в сочетании с покрытием всех фактических значений в тестовой выборке, указывает на то, что это наилучший метод построения интервалов в данном случае. Это, впрочем, не означает, что всегда и везде надо строить непараметрические интервалы. Выбор метода должен быть продиктован тем, какие именно предпосылки нарушены в модели. Если бы мы не знали значения из тестовой выборки, мы могли бы провести элементарный анализ остатков. Например:
forecast::tsdisplay(ourModel1$residuals) hist(ourModel1$residuals) qqnorm(ourModel3$residuals) qqline(ourModel3$residuals)
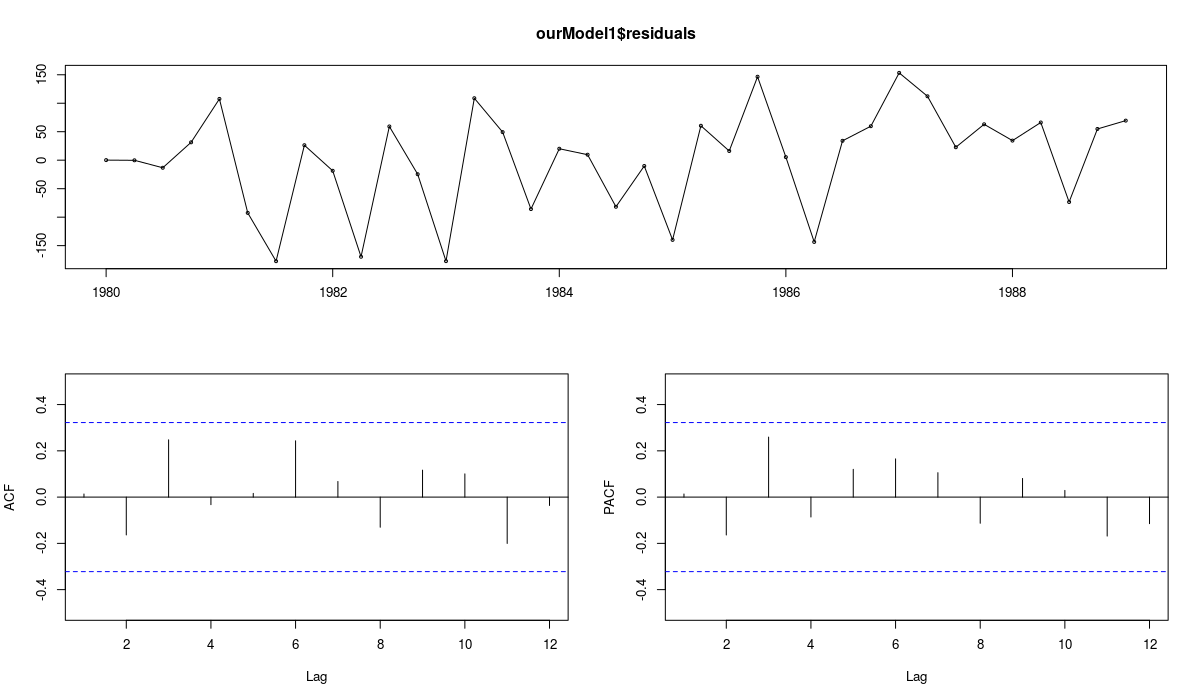
Линейный график и коррелограмма по остаткам модели ETS(A,Ad,N)
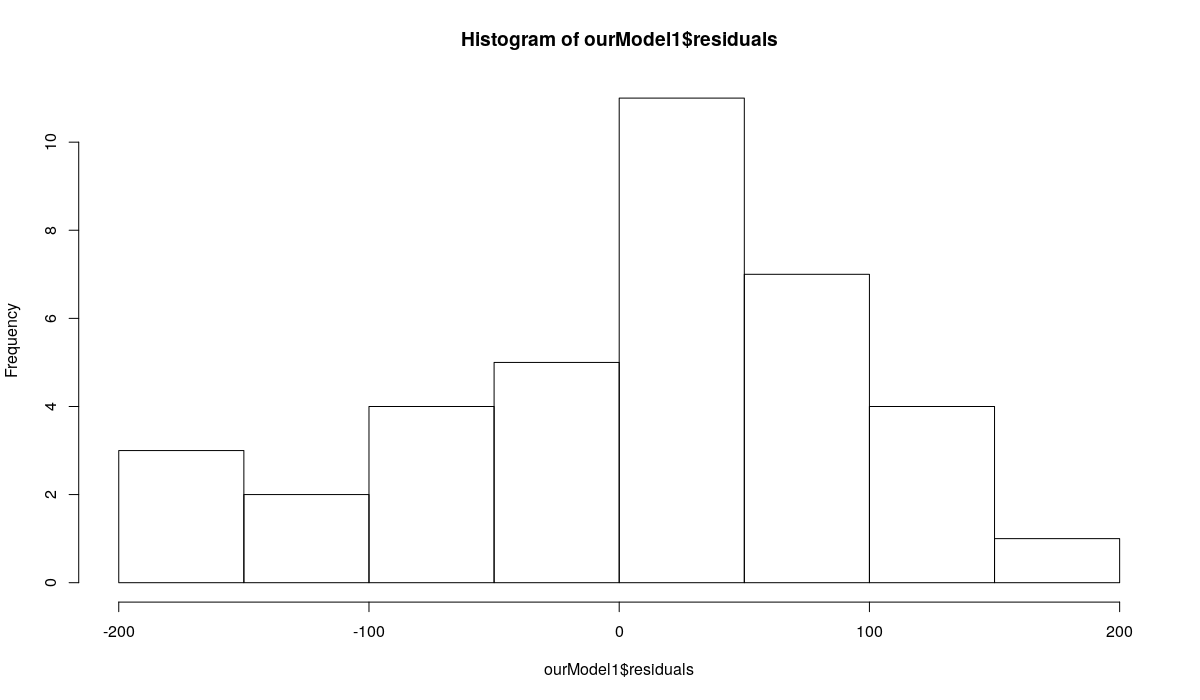
Гистограмма остатков модели ETS(A,Ad,N)
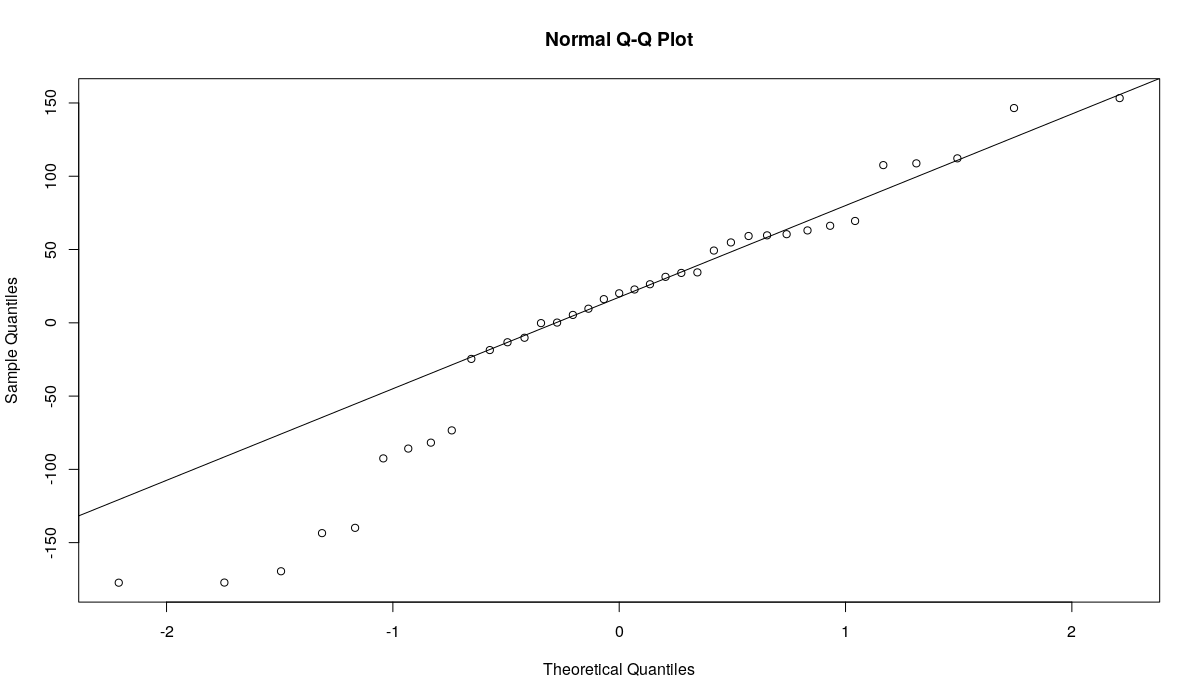
Графи квантиль-квантиль по остаткам модели ETS(A,Ad,N)
Первый график показывает, как остатки меняются во времени и что собой представляют коррелограммы остатков. Как видим, никакой очевидной автокорреляции и гетероскедастичности в остатках не наблюдается. Это означает, что мы можем предположить, что эти предпосылки не наршаются. То есть нет никакой надобности в полупараметрических интервалах. Однако второй и третий графики показывают, что остатки не распределены нормально (как предполагает модель ETS(A,Ad,N)). А значит параметрические интервалы могут быт неточными. Это мотивирует построение непараметрических интервалов в случае использования модели ETS(A,Ad,N) по ряду N1241.
На сегодня всё. До новых встреч!
Иван, здравствуйте.
Скажите как в вашей модели es() вывести точечный прогноз и интервальные прогнозы сразу в один data.frame?
as.data.frame(cbind(ourModel$forecast,ourModel$lower,ourModel$upper))