



В предыдущих статьях мы обсудили, как измерять точность точечных и интервальных прогнозов в разных случаях. Теперь мы можем глубже взглянуть на эту проблему и разобраться, в какой именно степени разные методы отличаются друг от друга. Представим гипотетическую ситуацию, в которой мы имеем дело с четырьмя методами на 100 временных рядах, точность которых измеряется с помощью RMSSE:
smallCompetition <- matrix(NA, 100, 4, dimnames=list(NULL, paste0("Method",c(1:4))))
smallCompetition[,1] <- rnorm(100,1,0.35)
smallCompetition[,2] <- rnorm(100,1.2,0.2)
smallCompetition[,3] <- runif(100,0.5,1.5)
smallCompetition[,4] <- rlnorm(100,0,0.3)
Мы можем сравнить среднюю и медианы в данном примере, чтобы понять, как они в целом себя ведут:
overalResults <- matrix(c(colMeans(smallCompetition),apply(smallCompetition,2,median)),
4, 2, dimnames=list(colnames(smallCompetition),c("Mean","Median")))
round(overalResults,5)
Mean Median Method1 0.99869 1.01157 Method2 1.18413 1.19839 Method3 1.00315 1.00768 Method4 1.08543 1.04730
В этом искусственном примере, самым точным (в соответствии со средней RMSSE) оказался первый метод, в то время как самым неточным, оказался метод 2. Что касается медиан, то тут лидирует Метод 3. Однако разность в точность между методами 1, 3 и 4 не выглядит существенной, особенно в случае с медианами. Можем ли мы заключить, что метод 1 самый лучший и надо отдать ему предпочтение? Давайте взглянём на распределение ошибок:
boxplot(overalResults) points(colMeans(smallCompetition),col="red",pch=16)
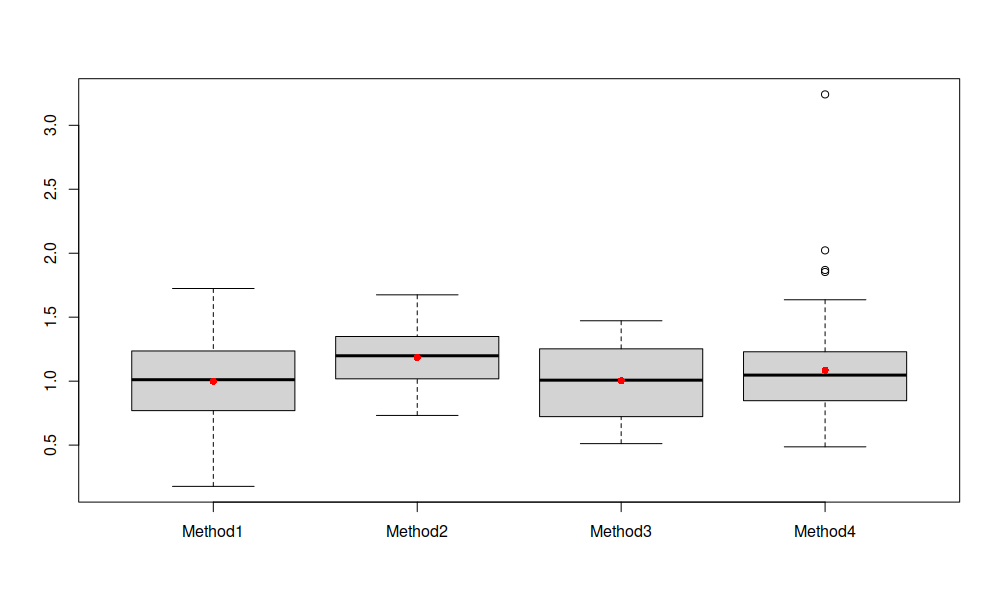
Ящичковая диаграмма по распределению прогнозных ошибок
Эти диаграммы нам показывают, что распределение ошибок метода 2 немного смещено вверх, по сравнению с распределениями для остальных методов. При этом дисперсия ошибок во втором методе ниже, чем в остальных (это из-за того, что мы использовали sd=0.2, когда генерировали данные). Кроме того, по такой диаграмме тяжело однозначно заключить, что метод 1 лучше метода 3 или наоборот - их ящичковые диаграммы пересекаются и очень похожи. Ну, и последнее, метод 4 в целом кажется чуть-чуть хуже, но это возможно из-за нескольких выбросов (несколько рядов, в которых метод не сработал).
Это всё основные описательные статистики, которые мы обычно используем для анализа случайных величин. Они нам позволяют заключить, что методы 1 и 3 очень похожи в плане точности прогнозов, а метод 2 им уступает. Это так же находит отражение в средних и медианных ошибках, которые мы рассчитали ранее. Что же нам заключить по результатам такого анализа? Что выбрать? Метод 1 или метод 3?
Давайте не будем делать поспешных решений. Вспомним, что мы имеем дело с выборкой из временных рядов (100 штук). Это означает, что средняя / медианная точность методов может измениться, если в нашей выборке появится ещё несколько рядов (или если из неё выкинуть несколько). Если бы в нашем распоряжении были все временные ряды во вселенной, мы могли бы оценить наши методы на них (удачи
и терпения в таком случае!) и прийти к каким-то более обоснованным выводам относительно их точности. Но мы имеем дело с выборкой, поэтому имеет смысл понять, является ли разница в точности методов статистически значимой или нет. Как это сделать?
Для начала, мы могли бы сравнить средние распределения ошибок с помощью какого-нибудь параметрического теста. Можно попробовать F-тест для того, чтобы понять, имеются ли какие бы то ни было различия в точности методов или нет. К сожалению, тест не скажет нам, какие именно методы оказались лучше, а какие хуже. Для этих целей можно использовать парный t-тест, но он позволяет сравнить одновременно только два метода друг с другом. Как вариант, можно построить регрессию с фиктивными переменными, для каждого метода и на основе интервалов для полученных параметров понять, как точность в среднем отличается от метода к методу. Главная проблема во всём этом заключается в том, что эти подходы предполагают, что распределение средних ошибок нормальное. В случае с большими выборками (тысячи рядов), центральная предельная теорема может начать работать, и эта предпосылка будет иметь смысл. Но в случае с малыми выборками, она, скорее всего, будет нарушена, особенно учитывая то, что прогнозные ошибки обычно распределены асимметрично, с длинным правым хвостом.
Возможное решение проблемы в этой ситуации - непараметрические тесты. Мы можем сравнить медианы распределений, вместо средних. Медианы менее подвержены влиянию выбросов, так что даже в случае с асимметричным распределением на малых выборках, они будут вести себя более предсказуемо, чем средние. В этой ситуации можно провести тест Фридмана, для того, чтобы понять, есть ли различия в медианах между методами (его можно считать непараметрическим аналогом F-теста). Для попарного сравнения можно использовать тест Уилкоксона вместо t-теста, но он так же покажет нам только, отличаются ли друг от друга выбранные два метода или нет (а у нас их четыре).
Хорошо, что у нас есть тест Nemenyi (Demšar, 2006), который эквивалентен тесту MCB (Koning et al., 2005). Если не вдаваться в детали, то что делает тест, так это ранжирует точность методов для каждого временного ряда, а затем сравнивает средние величины. Средняя рангов соответствует медиане, так что тест фактически сравнивает медианы прогнозных ошибок. Далее строятся доверительные интервалы для каждого из средних рангов и сравниваются друг с другом. Если какие-то интервалы пересекаются, то разница между медианами этих методов не значима статистически. Существуют разные методы представления результатов этого теста, один из них реализован в функции nemenyi() из пакета tsutils для R. Функция поддерживает разные виды графиков (Никос Курентзес обсуждал эту функцию в своём блоге), мне лично нравится стиль MCB:
library(tsutils) nemenyi(smallCompetition, plottype="mcb")
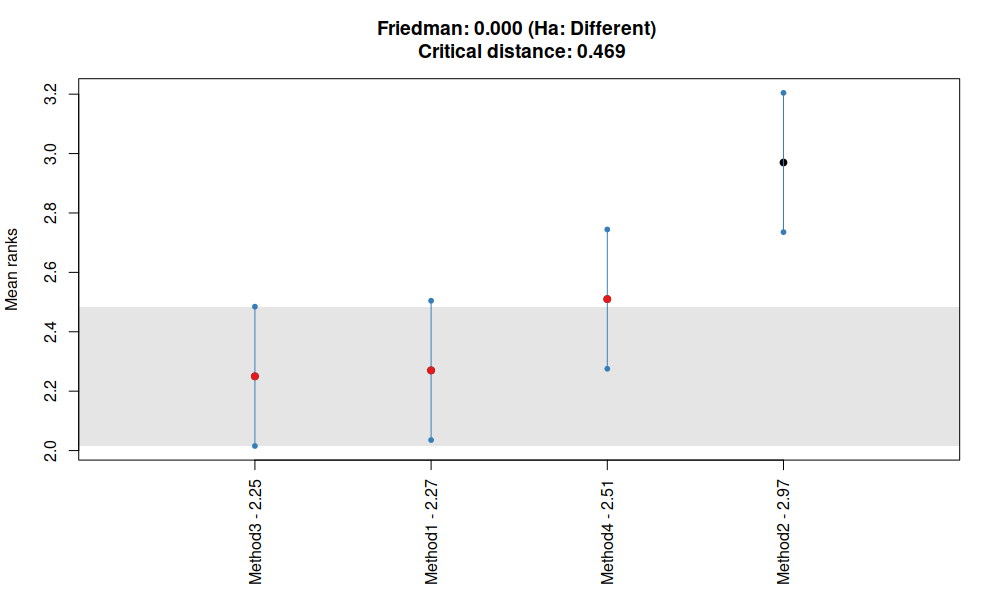
Тест MCB для сравнения медианных ошибок
По этому графику видно, что медианные ошибки методов 1, 3 и 4 не отличаются на 95% доверительном уровне (потому что их интервалы на графике пересекаются). При этом, как и ранее видно, что метод 3 лучше других (его медиана меньше всех), а метод 2 - хуже всех. Помимо этого, интервалы между методом 2 и методами 1 и 3 не пересекаются, так что можно заключить, что их медианные ошибки отличаются на 5% уровне остаточной вероятности. Что любопытно, интервалы второго и четвёртого методов пересекаются, так что между ними нет статистически значимой разницы. Тем не менее, мы можем заключить, что второй метод плохо работает на этих данных, а вот методы 1, 3 и 4 не сильно отличаются друг от друга. Эта ситуация может измениться, если у нас изменится выборка (например, добавится ещё сотня рядов) или увеличится число прогнозных методов.
Альтернативой тесту nemenyi(), дающей примерно такие же результаты, является построение регрессии с фиктивными переменными по рангам прогнозных ошибок. В этом случае мы получим коэффициенты модели и их доверительные интервалы, которые можно так же графически изобразить, как и в случае с Nemenyi / MCB. F-тест в таком случае покажет, отличается ли медианная ошибка хотя бы одного метода от всех остальных или нет (аналог теста Фридмана). Конечно же, статистически более правильным было бы построение порядковой логистической регрессии, но и такой простой метод с простой линейной регрессией даст необходимые результаты. К тому же, с ним значительно проще работать, чем с логистической моделью. Функция rmcb() из пакета greybox как раз реализует подобный подход. Преимущество этого метода по сравнению с nemenyi() заключается в скорости, особенно на больших выборках. Вот пример:
library(greybox) ourTest <- rmcb(smallCompetition,plottype="none") ourTest plot(ourTest,"mcb")
Regression for Multiple Comparison with the Best The significance level is 5% The number of observations is 100, the number of methods is 4 Significance test p-value: 0
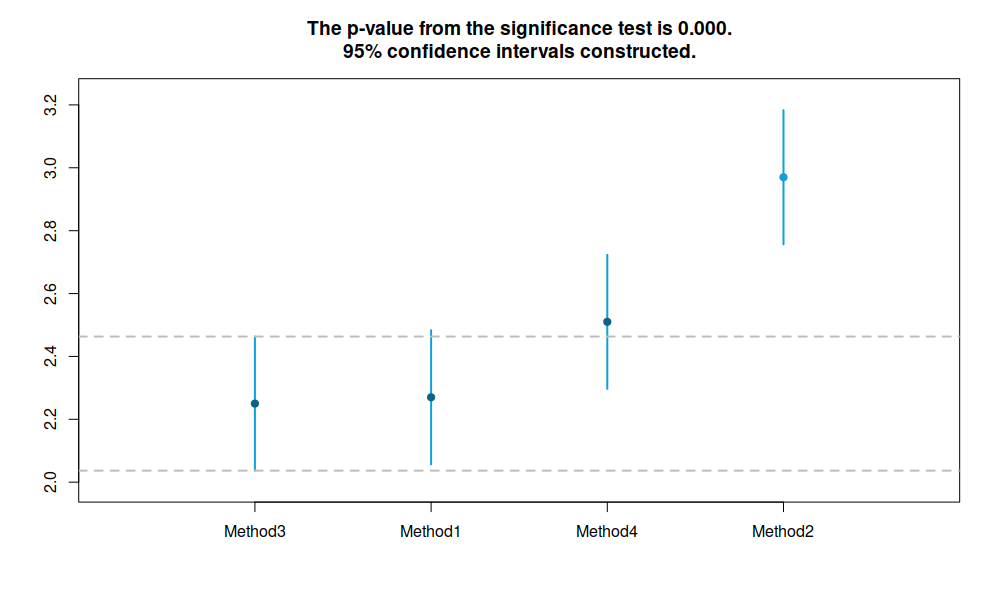
RMCB test for medians of error measures for the small competition
Результаты теста аналогичны тому, что мы уже видели ранее: методы 3, 1 и 4 статистически не различимы в плане медианных RMSSE, а метод 2 оказался значительно менее точным, чем остальные. Главная разница между Nemenyi и регрессией по рангам заключается в том, как именно считаются критические значения в статистике: nemenyi() использует Стьюдентезированный размах, а rmcb() использует распределение Стьюдента (это два разных распределения). Первое более чувствительно к числу методов, которые сравниваются в тесте, чем второе. Однако, с увеличением выборки, результаты тестов будут приближаться друг к другу. Из-за этой разницы rmcb() утверждает, что медиана метод 4 значительно (статистически) ниже медианы метода 2 на 5% уровне остаточной вероятности. Я бы рекомендовал использовать этот метод на больших выборках.
Что касается выводов из всего вышенаписанного, судя по всему, хоть методы и ведут себя по-разному на наших условных данных, медианы некоторых из них не значительно отличаются друг от друга на 5% уровне (методы 3, 1 и 4). Для того, чтобы прийти к какому-то более точному выводы, нам следовало бы собрать больше данных и провести повторный анализ. Вполне возможно, что на выборке из 1000 рядов, разница между методами стала бы статистически значимой на 5% уровне, и мы смогли бы выявить явного лидера. Однако, в нашем случае для выбора наилучшего метода имеет смысл обратиться к другим важным факторам, таким как простота методов или время, требуемое на построение прогнозов. Как видим, статистические тесты могут помочь нам в принятии более взвешенное решение относительно того, какому прогнозному методу отдать предпочтение.
Иван, доброго времени года.
Планируете ли вы написать статью по итогам соревнования на кагле в рамках M5?
Здравствуйте,
Пока не планирую. Думаю, там и без меня будет полно информации и статей. В IJF (https://www.journals.elsevier.com/international-journal-of-forecasting) будет специальный выпуск на эту тему. Скорее всего, его сделают доступным для всех читателей.