



Данная статья многим может показаться совершенно непонятной. Оно и не удивительно, к моделям экспоненциального сглаживания мы ещё в учебнике не подобрались, а вот программу для них уже обсуждаем… Что же поделаешь?! Жизнь жестока!
Итак, в R для построения моделей экспоненциального сглаживания существует прекрасная функция ets() из пакета forecast, которым занимается Rob J.Hyndman. Пакет находится в общих репозиториях и легко устанавливается командой в R:
install.packages("forecast")
Однако у этой функции с моей точки зрения есть несколько недостатков, среди которых можно выделить следующие:
- Отсутствие некоторых моделей экспоненциального сглаживания;
- Отсутствие возможности задавать произвольные значения компонент;
- Невозможность включения экзогенных (внешних) переменных;
- Ограниченность критериев в целевой функции
- Отсутствие возможности разбиения выборки на тестовую и проверочную.
В книге «Forecasting with Exponential Smoothing» Роб с соавторами предлагают таксономию, в соответствии с которой существует всего 30 моделей экспоненциального сглаживания, однако функция ets() позволяет строить только 19 из них, опуская сложные в оценке модели (включая оригинальную модель Хольта-Уинтерса).
Для инициализации любой модели экспоненциального сглаживания нужно задать самое первое расчётное значение либо первые значения компонент уровня ряда, тренда и сезонной составляющей. В ets() они подбираются во время оптимизации, но иногда стартовые значения имеет смысл задать вручную. Именно этой возможности в ets() и нет.
В той же книге обсуждается, что в модель пространства состояний, в виде которой авторы представляют любое экспоненциальное сглаживание, можно легко включить произвольное количество экзогенных переменных, которые объяснили бы поведение нашего показателя в некоторые моменты времени. Однако возможность включения переменных в функции ets() отсутствует. Пока она отсутствует и в моей функции «es», но в списке приоритетов она не на последнем месте.
ets() позволяет оценивать модели, используя либо простую сумму квадратов отклонений, либо функцию правдоподобия, либо среднюю абсолютную ошибку… Но траекторных критериев в функции нет. Под траекторными понимаются такие критерии, которые учитывают прогнозную траекторию модели и минимизируют ошибку не на один шаг вперёд, а на несколько.
Иногда нам нужно просто проверить, как себя поведёт та или иная функция на выбранном ряде данных. Для того, чтобы сопоставить фактические значения с прогнозными с помощью функции ets() нужно сделать много лишних движений.
Этих недостатков мне показалось достаточно для того, чтобы написать свою функцию, но главной проблемой моей функции всё это время была скорость работы. Недавно я переписал главные куски кода в C++, и теперь скорость выросла в разы (порядка 30 раз). Теперь мне за свою функцию не стыдно и можно о ней немного рассказать.
Установить функцию можно легко если в вашем R есть пакет «devtools» (мы это уже кратко обсуждали в статье про CES). Однако при сборке под Windows вам может понадобиться программа под названием «Rtools». Скачать её можно отсюда, устанавливать лучше в корневой каталог. Так же для сборки понадобятся пакеты Rcpp и RcppArmadillo:
install.packages("Rcpp")
install.packages("RcppArmadillo")
В случае возникновения проблем, рекомендую просмотреть статью про основы R.
После этого установка пакета с функцией es() (от английского «Exponential Smoothing») выполняется следующей командой:
devtools::install_github("trnnick/TStools")
В этот репозиторий я загружаю уже протестированные функции, а всё самое весёлое и потенциально плохо работающее я загружаю в свой пакет «prognosis». Если вы смелый, ловкий, умелый, то милости прошу установить пакет «prognosis».
После установки подключим пакет в R:
library("TStools")
А теперь посмотрим, что нам даёт эта функция es(). Возьмём для примера какой-нибудь ряд из базы M3. Например, N1234. Для того, чтобы сравнить прогнозные и фактические значения на проверочной выборке, предварительно объединим тестовую и проверочную части в одну переменную \( y \):
y <- ts(c(M3$N1234$x,M3$N1234$xx),frequency=frequency(M3$N1234$x),start=start(M3$N1234$x))
И для начала попросим функцию самостоятельно выбрать наилучшую модель экспоненциального сглаживания и дать прогноз на 8 наблюдений вперёд.
es(y,h=8,holdout=TRUE)->test
В результате этого получим следующий график:
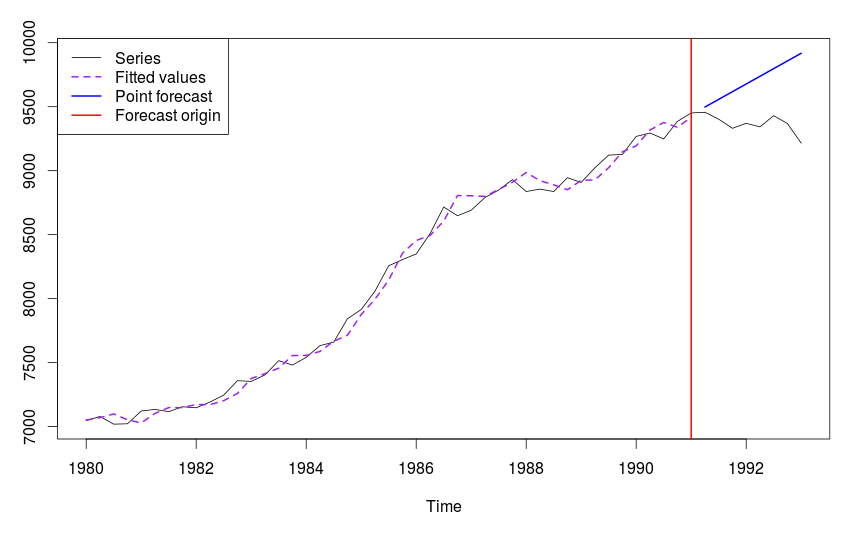
График ряда N1234 и модели ETS(A,A,N), построенной по нему.
и вывод в консоль:
Building model: ANN AAN AAdN AMN AMdN ANA AAA AAdA AMA AMdA ANM AAM AAdM AMM AMdM MNN MAN MAdN MMN MMdN MNA MAA MAdA MMA MMdA MNM MAM MAdM MMM MMdM ... Done! "Time elapsed: 4.04 seconds" "Model constructed: MAN" "Persistence vector: 0.672, 0.233" "Initial components: 7036.588, 7.801" "Residuals sigma: 0.008" "CF type: one step ahead; CF value is: 4677" "Biased log-likelihood: -258" "AIC: 515.97 AICc: 516.97" "MASE: 4.82" "MASALE: 3.72%"
Разберём построчно, что же мы тут получили.
В первой строке перечислены все опробованные модели, и слова в ней добавляются по мере построения модели.
В строке [2] показано время, потраченное на работу программы. Эта информация позволяет нам прикинуть, сколько может занять работа программы по массиву похожих временных рядов. 8 секунд - это, конечно, немало. Надеюсь, в будущем я смогу ещё оптимизировать код и довести этот показатель до 2 - 3 секунд.
Строка [3] показывает выбранную функцией модель. Это модель с аддитивной ошибкой, аддитивным трендом, без сезонности. Этой модели соответствует метод Хольта.
Строкой [4] перечислены оптимальные постоянные сглаживания, которые функция es получила в ходе расчётов.
[5] - это стартовые значения компонент уровня и тренда в модели Хольта. [6] - это стандартное отклонение остатков полученной модели.В строке [7] написано, какой критерий использовался при оценке. "One step ahead" соответствует минимизации средней квадратической одношаговой прогнозной ошибки. Подробней о критериях скоро можно будет прочитать в готовящейся к публикации статье "Методы оценки параметров моделей" в разделе Инструментарий прогнозиста.
CF value в той же строе [7] - это значение полученной целевой функции. Особо полезной информации не несёт, но позволяет проводить элементарное сравнение между моделями, построенными по одному и тому же ряду данных.
[8] Biased log-likelihood - смещённое значение логарифмированной функции правдоподобия. Техническая деталь, не несущая особой пользы человечеству. Будет убрана в следующем релизе.Информационные критерии AIC и AICc в строке [9] позволяют проводить более корректно сравнение между моделями. Общий принцип - чем меньше значение, тем ближе модель к некой "истинной", лежащий где-то там, в основе мироздания. Для модели ETS(M,A,N), как видим, получились такие вот значения. Для сравнения, для сезонной модели ETS(A,A,A), построенной по этому же ряду, у меня получились такие значения: "AIC: 526.862 AICc: 532.005". Это говорит о том, что модель ETS(M,A,N) ближе к истине, чем ETS(A,A,A), что неудивительно - в нашем ряде данных сезонности нет. Информационные критерии мы ещё обсудим в будущем параграфе "Выбор прогнозной модели" раздела "Инструментарий прогнозиста".
Пунктами [10] и [11] показаны ошибки прогноза. Первая - это "Mean Absolute Scale Error", а вторая - такая же, отличающаяся лишь знаменателем в формуле. Чем меньше значение, тем точнее оказался прогноз. Подробней о них мы поговорим во всё том же разделе "Инструментарий прогнозиста". Но не сегодня.
Но и это ещё не всё. Переменная test, в которую мы сохранили результаты работы нашей функции, содержит в себе кучу всего интересного (вызываемого командой вида test$var, где var - это имя переменной):
- persistence - вектор постоянных сглаживания. Может содержать от 1 до 3-х следующих элементов: \(\alpha, \beta, \gamma \).
- phi - значение коэффициента демпфирования. Имеет смысл только в случае, если построена модель с демпфированным трендом.
- states - матрица, содержащая компоненты экспоненциального сглаживания. В случае с нашей моделью ETS(A,A,N) содержит 2 столбца: уровень и тренд. Её можно так же представить графически следующим образом:
plot(test$states)
Должен получиться вот такой график:
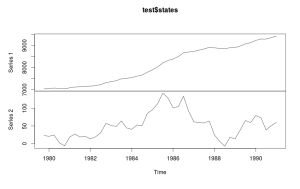
Компоненты модели ETS(M,A,N) по ряду N1234 в динамике
- fitted - расчётные значения в тестовой выборке.
- forecast - прогноз по модели (соответствующий проверочной выборке).
- residuals - остатки модели, соответствующие одношаговым ошибками, полученным по тестовой выборке.
- errors - матрица ошибок модели. В случае, если использовался стандартный критерий "One step ahead" совпадает с остатками residuals. В случае с другими критериями содержит итоговую матрицу многошаговых ошибок.
- x - исходный ряд данных (весь ряд, отправленные функции).
- ICs - информационные критерии AIC и AICc, рассчитанные для модели.
- CF - значение целевой функции.
- FI - матрица "информация Фишера". Получается из функции правдоподобия и нужна для расчёта дисперсий коэффициентов. В R ковариационную матрицу коэффииентов на основе неё можно легко получить с помощью следующей команды:
solve(-test$FI)
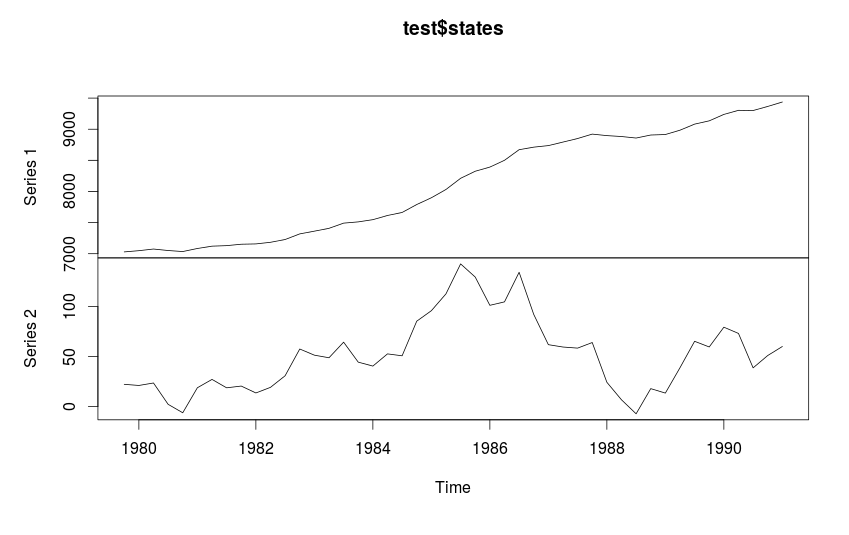
Мы можем попросить es() построить нам какую-нибудь конкретную модель экспоненциального сглаживания, а не выбранную автоматически. Для этого надо передать функции название модели. Например, для модели демпфированного тренда ETS(A,Ad,N) нужно ввести:
es(y,model="AAdN",h=8,holdout=TRUE)->test
Вывод в консоль будет аналогичным предыдущему, а график получится такой:
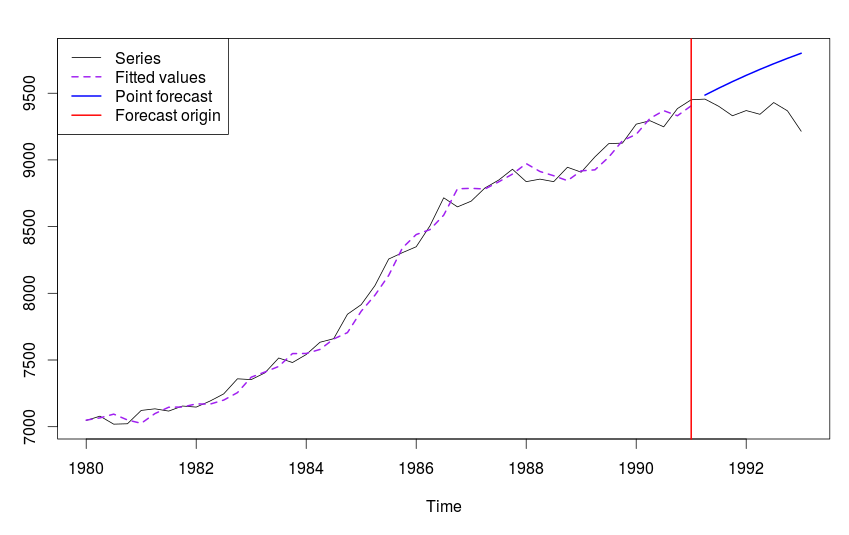
График ряда N1234 и модели ETS(A,Ad,N), построенной по нему.
es() может построить и всякие "запрещённые" в ets() модели. Например, по ряду N2568 самой близкой к "идеальной" будет модель ETS(A,Ad,M), которая соответствует методу Хольта-Уинтерса и в ets() недоступна. Выглядит это графически вот так:
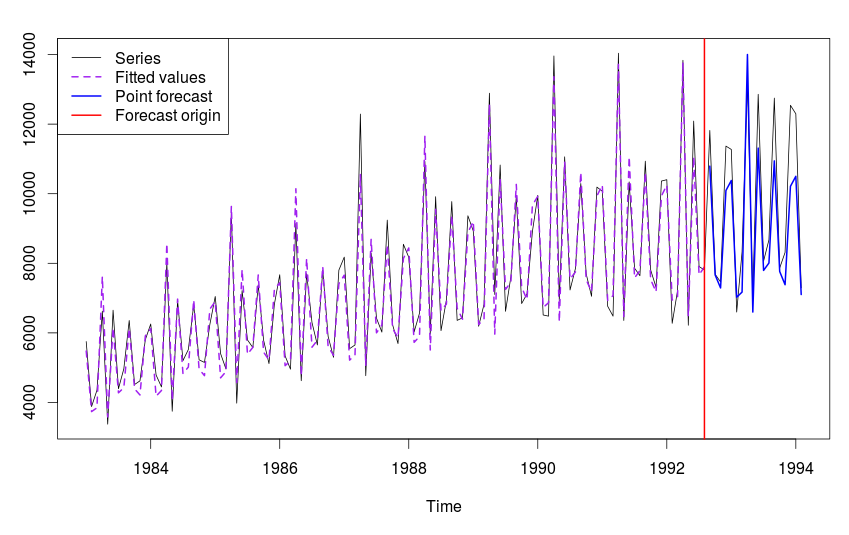
Ряд N2568 и прогноз по модели ETS(A,Ad,M).
es() так же может находить параметры из классических и из расширенных границ для постоянных сглаживания. Я лично считаю, что только расширенные границы и нужно использовать при оценке моделей экспоненциального сглаживания, но некоторые прогнозисты со мной не согласны (но мы их со временем переубедим. На нашей стороне правда и Keith Ord). По умолчанию в функции используются классические границы, но расширенные включаются достаточно легко:
y <- ts(c(M3$N2568$x,M3$N2568$xx),frequency=frequency(M3$N2568$x),start=start(M3$N2568$x)) es(y,h=18,holdout=TRUE,bounds="admissible")->test
Вместо слова "admissible" можно ввести и просто первую букву - "a".
Из-за того, что расширенные границы больше классических, во время оптимизации могут получаться другие оптимальные значения параметров. Для нашего сезонного ряда N2568 оптимальной моделью теперь будет ETS(M,A,M), которая позволяет построить более точный прогноз по ряду. Графически это выглядит так:
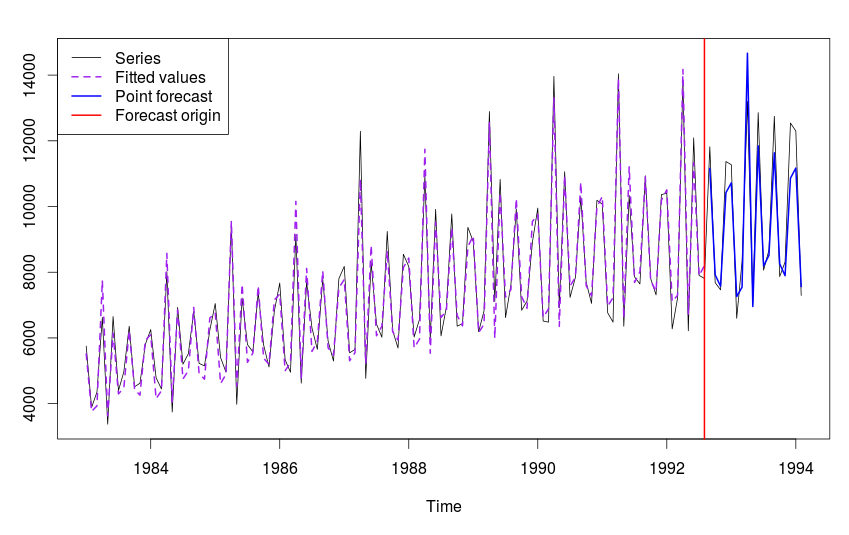
Ряд 2568 и модель ETS(M,A,M)
И вот мы подобрались к самому интересному. Достаточно важной особенностью функции es() является возможность использовать тракеторные целевые функции. По умолчанию используется нечто под названием "TLV" - Total Logarithmic Variation. Суть метода заключается в том, что вместо одношаговой ошибки на каждом наблюдении производится многошаговая (от 1 до h, где h - срок прогнозирования). Затем по этим ошибкам рассчитываются дисперсии, которые логарифмируются, суммируются и минимизируются. На сайте на эту тему есть статья. Напомним, что использование "TLV" позволяет увеличивать точность долгосрочных прогнозов при незначительном уменьшении точности краткосрочных. Помимо TLV есть ещё "GV" - generalised variance, "TV" - Total Variation и "hsteps" - ошибка прогноза на h шагов вперёд. При использовании TLV и GV можно так же легко использовать процедуру выбора наилучшей модели. А вот использование этой процедуры в случаях с TV и hsteps ничем теоретически не обосновано.
Посмотрим, что получится, если использовать траекторную целевую функцию для того же сезонного ряда N2568:
es(y,h=18,holdout=TRUE,trace=TRUE)->test
Оптимальной остаётся всё та же функция ETS(M,A,M), параметры отличаются незначительно, но точность прогноза вырасла - ошибка уменьшилась с 8,71% до 6,37%. А всё из-за того, что во втором случае лучше выявлены долгосрочные тенденции.
Про методы оценки моделей можно почитать здесь, а можно - и просто посмотреть презентацию, которую я делал в Глазгоу - там вкратце описана идея траекторных целевых функций.
Пока по es() всё. Функция всё ещё разрабатывается и дорабатывается. Следите за обновлениями!
Иван, спасибо огромное за замечательный пакет для R! Производительность в принципе приемлемая (если не использовать trace=TRUE), но большую часть времени занимает перебор моделей. Нельзя ли как-то уменьшить множество моделей для перебора, например используя MAPAx?
А MAPAx — это, случайно, не модель MAPA (Kourentzes et al.), расширенная для каких-нибудь типов данных?
Насколько помню, оригинальная MAPA использовала разные ETS на разных уровнях, после чего их агрегировала. Если тут так же, то уменьшить число моделей для перебора не получится — MAPA на нижних временных уровнях всё так же использует все возможные виды модели.
Я точно знаю, что процесс перебора можно ускорить, если сделать следующее:
1. Перенести остатки кода (отвечающие за перебор) в C++.
2. Сделать перебор параллельным.
Первый пункт я собираюсь сделать. Пока просто руки до него не дошли.
Надо ли делать второй, пока не уверен. Как справлюсь с первым, посмотрим.
MAPAx это MAPA с регрессорами. Kourentzes сказал что собирается использовать ваш TStools и матрицу states.
Что касается скорости, то я имел ввиду, что начав тестировать модели с трендом (от простых к сложным) и видя, что показатели улучшаются, можно опустить перебор моделей без тренда. Или агрегировать, глянуть на наличие тренда и сезонности на более высоких уровнях и таким образом уменьшить список моделей для перебора на более низком уровне темпоральной агрегации.
У меня есть порядка 1500 временных рядов, мне их нужно перебрать в цикле и для каждого запомнить оптимальную модельку. Потом выключить cross-validation и произвести прогнозирование используя ранее выбранную модель. Первичный перебор с CV не должен занимать слишком много времени.
Мне понравилось как в xgboost есть возможность написать свою функцию расчета ошибки и передать ее в качестве параметра. Вы сделали MAPE, MASE, MASALE, но охватить все возможные варианты все равно не представляется реальным, поэтому можно было бы наверное вывести интерфейс, который по умолчанию равен NULL, куда можно было бы передать указатель своей функции, при условии что соблюден интерфейс. Я подозреваю, что эта часть алгоритма не написана на C++ поэтому особенного замедления работы быть не должно (либо пользователь должен пенять на себя).
Или может ARIMA без регрессоров быстренько прогнать и исходя из этого сузить круг поиска оптимальной модели… Перебор всех 38 вариантов это слишком
Да, можно попробовать сделать более интеллектуальный выбор модели. Но тут тоже есть свои подводные камни. Например, некоторые ряды, сгенерированные с помощью ETS(A,N,N), с постоянной сглаживания близкой к 1, выглядят иногда как ряды с трендами. Если их агрегировать, то точно получится тренд. Но AIC обычно такие ряды вылавливает достаточно хорошо и позволяет выбрать подходящую модель без тренда… В общем, тут не всё так однозначно. Но я ещё подумаю на эту тему и попробую какое-нибудь решение предложить :).
MAPE и пр. действительно реализованы сейчас как функции в R и выводятся просто для удобства как доп. информация. На xgboost посмотрю, спасибо за наводку.
В принципе, ничто не мешает получить из той же функции es() $forecast и $actuals и рассчитать любой желаемый коэффициент. Могу для удобства разбить $actuals на in-sample и holdout, если хотите :).
Наверное было бы удобно иметь holdout actuals под рукой для расчета ошибки в два действия. Я в действительности имел ввиду интерфейс функции ошибки для перебора моделей. Вы предполагаете что AIC — единственно верный способ поиска идеальной модели (и в теории так оно наверное и есть), но есть ситуации где минимизация holdout error и является единственным что интересует пользователя.
Я на самом деле так не полагаю :). Я знаю, что Cross Validation нередко даёт результаты лучше, чем AIC. В конце концов, AIC — это достаточно абстрактная идея о приближении к какой-то там несуществующей генерирующей модели. Просто работать с ним значительно проще + он статистически обоснован. Ну, и цель функции es() изначально была — реализовать ETS в альтернативном виде, но следуя общим принципам, описанным в Hyndman et al., 2008. Если сейчас заморачиваться с другими методами выбора модели, то функция растянется ещё больше и станет мало подъёмной.
А вот интерфейс для выбора модели — это, конечно, задача… Не уверен, что смогу это реализовать внутри es() на данном этапе своих знаний по программированию…
Иван,
два коротких вопроса сегодня: 1) Как достать значение «Model constructed: MAN» из объекта es(). Такое впечатление, что объект не содержит в себе типа модели
2) Ошибки рассчитываются по holdout или по всей выборке? Есть смысл я думаю репортить отдельно in-sample (соответствует объекту fitted), holdout (соответствует объекту forecast) и общий (соответствует объекту AIC).
DP
1. Упущение, да. Добавлю.
2. Ошибки рассчитываются по holdout. in-sample даёт не так много нужной информации, да и могут легко быть рассчитаны по $actuals и $fitted, поэтому я предпочёл их убрать.
Bug report:
Я считаю какой-то достаточно сложный случай — перебор порекомендовал метод AMdM. Все посчиталось нормально, но график прервал выполнение команды и выдал ошибку
>Error in plot.window(xlim, ylim, log, …) : need finite ‘ylim’ values
Проверив вектор $forecast я вижу что он пустой. Можно, пожалуйста, наполнять переменные до того, как начнете рисовать?
Картинка тут: http://i68.tinypic.com/nphnbo.png
Любопытно. А можете скинуть данные, чтобы я мог посмотреть подробней на то, что там происходит?
Просто, по идеи, данные по прогнозу записываются в отдельную переменную практически сразу после оценки модели.
И, если не затруднит, скиньте команду, которой вызывали функцию.
P.S. Вообще github для целей bug report хорошо подходит ;)
Иван, отзываю свой Bug Report. The fault is fully mine. У меня в xreg были missing values (в команде shift забыл указать fill=0), причем только в holdout части (то есть модель тренируется хорошо, но заваливается при прогнозе на последних нескольких значениях). Что можно было бы сделать для того чтоб защититься от таких глупостей пользователя это быстренько проверить is.na(xreg) и сказать, мол, «я за себя не отвечаю, сэр, тут у вас missing values в xreg».
О другом. Я все таки считаю что нужно дать пользователю возможность производить оптимизацию чего-то другого кроме AIC при поиске модели. На ряде, который я вам прислал в twitter, es() порекомендовала AAdN. Как вы видите, fit не очень — потому что происходит смена тренда прямо перед началом holdout периода. Я «угадал» MNN — вдвое меньше MAPE и отличный fit. Так что AIC — не панацея, особенно с регрессорами. Thank you, again, for the wonderful product!!
PS- Мне кажется я понимаю почему NA в регрессорах завалила график. В es.R вы устанавливаете xlim и ylim исходя из max и min. Вы не предполагаете что в векторе могут быть NA — вот ylim и сходит с ума
Хорошая идея! Буду проверять на na и выдавать сообщение. Так же сделаю проверку перед выводом графика. Это больше информации даст.
Спасибо за помощь! :)
А по поводу AIC… Конечно, не панацея. Но выбор модели — это вообще отдельная серьёзная проблема. Почему бы, например, не выбирать модели самостоятельно, а не автоматически? Petropoulos & Kourentzes (http://kourentzes.com/forecasting/2015/07/24/diy-forecasting-judgment-models-and-judgmental-model-selection/), например, показали, что это вполне себе неплохой метод…
В любом случае, другие методы, конечно же, можно реализовать в функции, но навряд ли я ими займусь в ближайшее время :). Можно, впринципе, внести это в github в функции для будущего (enhancement) — чтобы не забыть.
Автоматический перебор моделей — офигенная помощь. У меня 1115 магазинов в цикле перебираются — руками я буду до следующего года сортировать. Мне нужно сказать — вот моя целевая функция, подберите мне модель которая ее минимизирует. Все. Можно AIC в default поставить. Ответственность за правильность подобранной модели несет пользователь. Следующий шаг — организовать наиболее эффективный перебор. То есть какой-то greedy method перебора с целью минимизировать количество шагов и достичь good’nuff модели (возможно некий локальный но приемлемый минимум целевой функции).
Можете, пожалуйста, опубликовать код, который рисует графики, подобные вашим?
Здравствуйте, Леонид!
Эти графики рисует функция graphmaker() из пакета greybox. В документации к функции написано, какие именно параметры она принимает.