



В прошлый раз мы рассмотрели основы по работе с экзогенными переменными в функциях пакета smooth. Сегодня мы поговорим о более продвинутых вещах. Но прежде чем перейти к ним, нам нужно поговорить о вспомогательных функциях, которые реализованы в пакете greybox и используются в smooth. Первая из них называется xregExpander() и позволяет генерировать лаговые переменные на основе предоставленного вектора или матрицы. В качестве примера возьмём ряд BJsales.lead, который мы обсуждали в прошлом посте. Предположим, что влияние переменной на продажи носит более сложный характер, чем мы предполагали до того: BJsales.lead влияет на BJsales с лагом и 0, 5 и 10 дней. Это означает, что нам нужно учесть этот лаговый эффект, и это как раз то, что позволяет нам делать функция xregExpander():
newXreg <- xregExpander(BJsales.lead, lags=c(-5,-10))
Переменная newXreg представляет собой матрицу, которая содержит оригинальную переменную, а так же её же с лагами 5 и 10. Заметим, что, если бы мы просто сдвинули переменную во времени, то у нас образовались бы пропущенные значения (NAs). Поэтому xregExpander() заполняет пропущенные значения их прогнозами либо с помощью функции es(), либо с помощью iss() (в зависимости от типа переменной). Это так же означает, что, если вы пытаетесь сделать лаговой бинарную переменную, то пропущенные значения будут заменены средним значением (например, 0.7812). Так что будьте внимательны с тем, что получаете на выходе. Возможно, в вашем случае будет правильней заменить эти значения на нули или единицы...
Иногда так же бывают нужны и ведущие переменные (с положительными лагами) - переменные, значение которых в будущем определяет значение некоторой переменной сегодня. Подобные эффекты могут наблюдаться, например, в моделировании эффектов от акций в супермаркетах, когда покупатели ожидают снижения цены на товар через какое-то время. Это всё регулирует по средствам добавления положительных значений в xregExpander():
newXreg <- xregExpander(BJsales.lead, lags=c(7,-5,-10))
Значения в этом случае так же сдвигаются, но уже в другую сторону, а недостающие наблюдения заменяются их прогнозными значениями.
После того, как мы трансформировали переменные, мы можем из использовать в функциях пакета smooth для прогнозирования. Всё, что мы обсуждали в прошлом посте, применимо и здесь:
es(BJsales, "XXN", xreg=newXreg, h=10, holdout=TRUE)
Но что нам делать, если в нашем распоряжении несколько переменных, и мы не уверены в том, какие лаги включать? У этой задачи есть много решений, одно из них реализовано в функциях пакета smooth. Стоит заметить, что это решение не обязательно гарантирует точные прогнозы, но это хоть какое-то решение. Основано оно на работе функции stepwise() из пакета greybox, которая осуществляет пошаговый отбор на основе информационных критериев и частной корреляции. Для работы данной функции, нужно, чтобы выходная переменная была в первом столбце матрицы. Идея функции проста, и весь алгоритм сводится к следующему:
- Строится базовая модель первой переменной от константы (что соответствует простой средней по ряду). Рассчитывается информационный критерий;
- Рассчитываются корреляции остатков модели с имеющимися экзогенными переменными;
- Строится регрессионная модель выходной переменной от всех уже включённых переменных, плюс той, которая сильнее всего коррелирует с остатками. Для этого используется функция lm();
- Рассчитывается информационный критерий новой модели, и сравнивается с предыдущим значением. Если новое значение меньше, то происходит переход к шагу (2). Иначе процесс прекращается и выбирается предыдущая модель.
Таким образом мы не проводим поиск переменных "вслепую", но осуществляем своеобразный поиск хорошей модели по некоторой траектории: если какая-то значимая часть переменной ещё осталась необъяснённой, то корреляция по остаткам покажет её, а значит и соответствующая переменная будет включена в модель. Использование корреляций позволяет включать только "осмысленные" переменные, а использование информационных критериев позволяет обойти проблему неопределённости статистических гипотез. В целом, функция позволяет найти модель с одним из наименьших информационных критериев в сжатые временные сроки. Это, конечно же, не гарантирует наиболее точные прогнозы, но для этого эволюция как раз и наградила людей мозгом: статистика - это хорошо, но не стоит забывать о здравом смысле!
Взглянем на работу функции на примере с 10 лаговыми и 10 ведущими переменными:
newXreg <- as.data.frame(xregExpander(BJsales.lead,lags=c(-10:10))) newXreg <- cbind(as.matrix(BJsales),newXreg) colnames(newXreg)[1] <- "y"
Код выше гарантирует, что в нашем распоряжении будет data frame с красивыми именами, а не какой-нибудь трэш. Замети ещё раз, что для функции stepwise() важно, чтобы выходная переменная была в первом столбце матрицы.
ourModel <- stepwise(newXreg)
И вот, что у нас получилось в итоге:
Call:
lm(formula = y ~ xLag4 + xLag9 + xLag3 + xLag10 + xLag5 + xLag6 +
xLead9 + xLag7 + xLag8, data = newXreg)
Coefficients:
(Intercept) xLag4 xLag9 xLag3 xLag10 xLag5 xLag6
17.6448 3.3712 1.3724 4.6781 1.5412 2.3213 1.7075
xLead9 xLag7 xLag8
0.3767 1.4025 1.3370
Переменные в функции перечислены по мере включения их в модель. Функция работает достаточно быстро, так как ей не приходится проходить через все возможные комбинации моделей.
Вы спросите: ну и что? А вот что! Эти две функции можно использовать вместе с функциями пакета smooth: в es(), ssarima(), ces() и ges() реализован механизм выбора переменных на основе stepwise(), регулируемый с помощью параметра xregDo, которые по умолчанию задан как "use" (использовать все переменные), но может быть так же принимать значение "select" (выбрать наилучшую модель). В этом случае функция stepwise() будет применена к остаткам модели, и, когда подходящие переменные будут найдены, итоговая модель будет переоценена для избавления от потенциального смещения в оценках параметров.
Посмотрим, как это работает на том же примере. Для начала просто построим модель со всеми переменными (я уберу от греха подальше первую переменную из уже имеющегося data frame, которая является выходной переменной):
newXreg <- newXreg[,-1] ourModelUse <- es(BJsales, "XXN", xreg=newXreg, h=10, holdout=TRUE, silent=FALSE, xregDo="use", intervals="sp")
Time elapsed: 1.13 seconds
Model estimated: ETSX(ANN)
Persistence vector g:
alpha
0.922
Initial values were optimised.
24 parameters were estimated in the process
Residuals standard deviation: 0.287
Xreg coefficients were estimated in a normal style
Cost function type: MSE; Cost function value: 0.068
Information criteria:
AIC AICc BIC
69.23731 79.67209 139.83673
95% semiparametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: 0%; Bias: 55.7%; MAPE: 0.1%; SMAPE: 0.1%
MASE: 0.166; sMAE: 0.1%; RelMAE: 0.055; sMSE: 0%
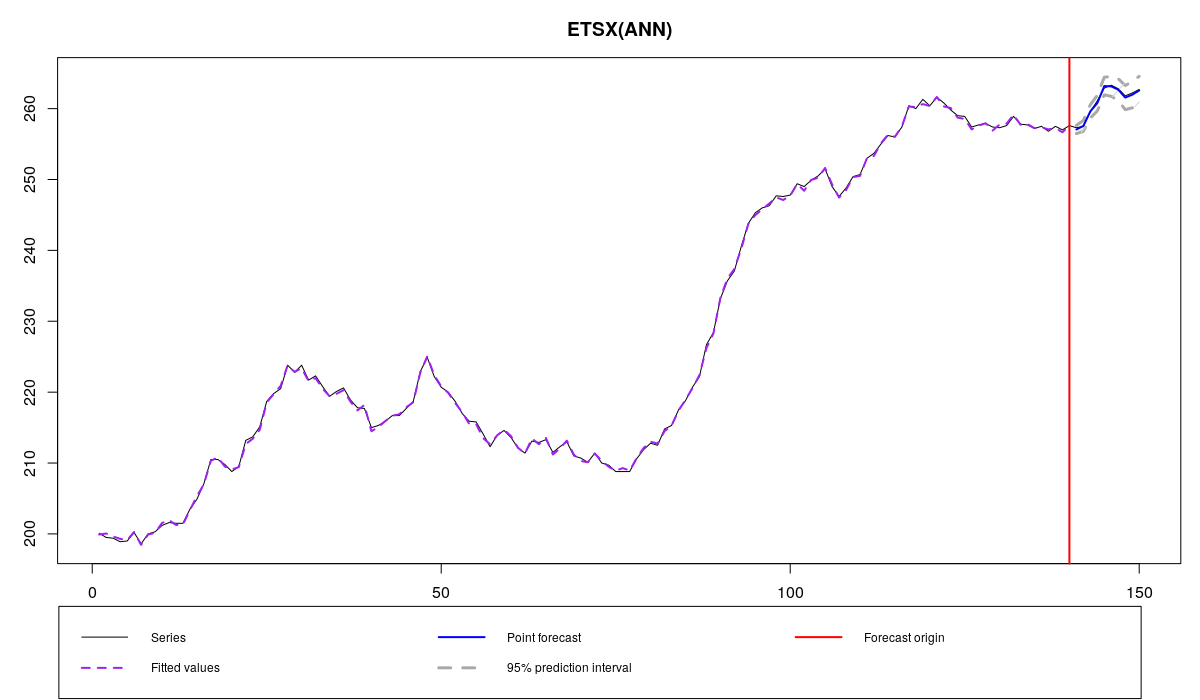
Ряд BJsales и модель ETSX со всеми переменными
Как видим, прогноз стало более точным, чем он был в прошлой статье, в которой мы не использовали лаги. Это означает, что в ряде данных действительно наблюдается влияние лаговых эффектов на продажи. Впрочем, из-за того, что мы включили всё подряд, полученная модель, возможно, стала слишком сильно аппроксимировать ряд, что может плохо сказаться на точности прогнозов. Хорошо бы выкинуть все лишние переменные...
ourModelSelect <- es(BJsales, "XXN", xreg=newXreg, h=10, holdout=TRUE, silent=FALSE, xregDo="select", intervals="sp")
Time elapsed: 0.98 seconds
Model estimated: ETSX(ANN)
Persistence vector g:
alpha
1
Initial values were optimised.
11 parameters were estimated in the process
Residuals standard deviation: 0.283
Xreg coefficients were estimated in a normal style
Cost function type: MSE; Cost function value: 0.074
Information criteria:
AIC AICc BIC
54.55463 56.61713 86.91270
95% semiparametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: 0%; Bias: 61.4%; MAPE: 0.1%; SMAPE: 0.1%
MASE: 0.159; sMAE: 0.1%; RelMAE: 0.052; sMSE: 0%
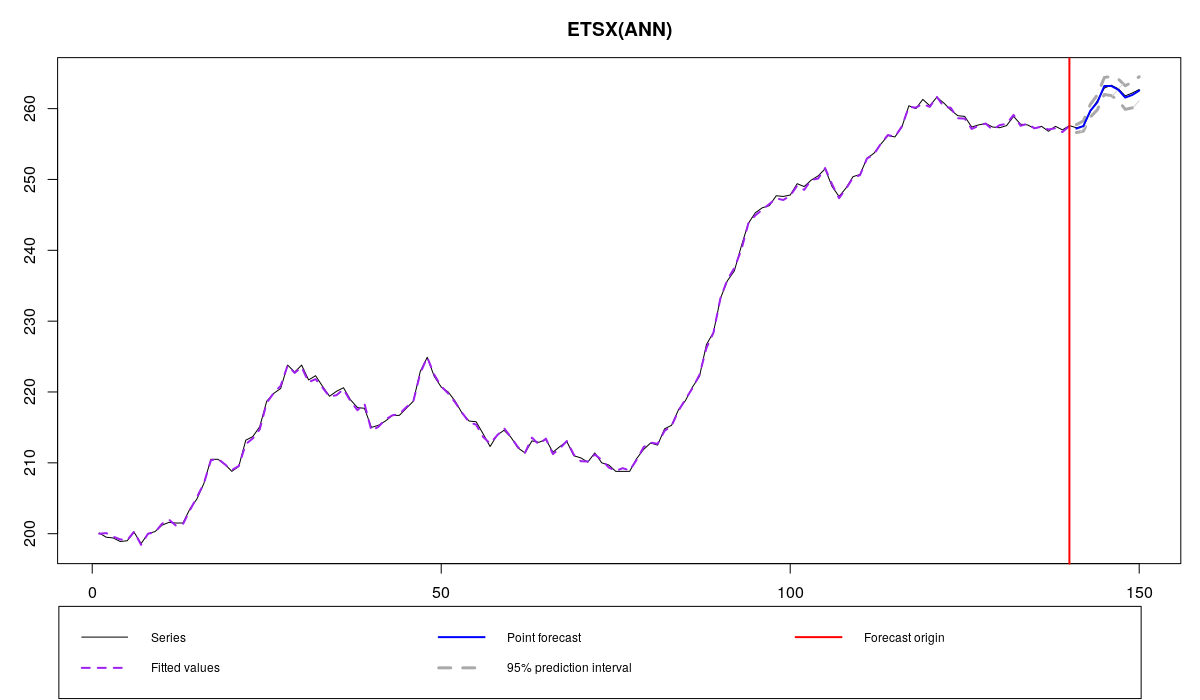
Ряд BJsales и модель ETSX с выбранными переменными
Несмотря на то, что по графику тяжело сказать, улучшился ли прогноз или нет, по ошибкам улучшение таки заметно: MASE уменьшилась с 0.166 до 0.159. AICc также уменьшился с 79.67209 до 56.61713. Это из-за того, что вторая модель включает только 8 переменных (вместо 21):
ncol(ourModelUse$xreg) ncol(ourModelSelect$xreg)
Выбор переменных работает даже в случае с комбинированием прогнозов. Так экзогенные переменные выбираются для каждой модели отдельно, после чего производятся прогнозы, которые затем и комбинируются на основе весов IC. Пример:
ourModelCombine <- es(BJsales, c("ANN","AAN","AAdN","CCN"), xreg=newXreg, h=10, holdout=TRUE, silent=FALSE, xregDo="s", intervals="sp")
Time elapsed: 1.46 seconds
Model estimated: ETSX(CCN)
Initial values were optimised.
Residuals standard deviation: 0.272
Xreg coefficients were estimated in a normal style
Cost function type: MSE
Information criteria:
(combined values)
AIC AICc BIC
54.55463 56.61713 86.91270
95% semiparametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: 0%; Bias: 61.4%; MAPE: 0.1%; SMAPE: 0.1%
MASE: 0.159; sMAE: 0.1%; RelMAE: 0.052; sMSE: 0%
Учитывая то, что модель ETSX(A,N,N) оказалась значительно лучше других моделей с точки зрения AICc, вес этой модели оказался наибольшим. Поэтому прогнозы ourModelSelect и ourModelCombine фактически идентичны. Начиная с версии v2.3.2, функция es() возвращает матрицу с информационными критериями для моделей, которые были оценены в процессе, так что мы можем посмотреть на AICc разных моделей:
ourModelCombine$ICs
AIC AICc BIC ANN 54.55463 56.61713 86.9127 AAN 120.85273 122.91523 153.2108 AAdN 107.76905 110.22575 143.0688 Combined 54.55463 56.61713 86.9127
Как видим, информационные критерии модели ETS(A,N,N) действительно оказались значительно ниже критериев других моделей, что привело к её превалированию в финальной комбинации.
Обратим внимание, что комбинация прогнозов - это не то же самое, что и комбинации моделей. Эта функция пока не доступна в функциях пакета smooth, и я не уверен, что она когда-нибудь появится.
В заключении заметим, что метод выбора в пакете ставит на первое место динамическую часть модель (в нашем примере - это ETS), нежели часть с экзогенными переменными. Это соответствует подходу прогнозистов к моделированию: мы используем экзогенные переменные как инструмент для объяснения тех характеристик временного ряда, которые обычная модель не смогла выловить. Классический подход эконометристов обычно подразумевает обратное: построение регрессии с последующим включением динамических компонент (например, авторегрессии). У такого подхода другая цель, поэтому и результаты будут другими.