



ОБНОВЛЕНИЕ: Начиная с версии smooth v 2.5.0, модели и соответствующие функции были изменены. Теперь вместо intermittent и iss() в пакете существуют occurrence и oes(). Пожалуйста, используйте новые функции и новые параметры. Старый функционал будет удален в следующей версии пакета. Этот статья была обновлена 25 апреля 2019 года.
Одно из преимуществ функций пакета smooth заключается во встроенной возможности работать с прерывистыми данными и с данными с периодически возникающими нулями.
Прерывистый спрос — это такой спрос на продукцию, который происходит нерегулярно (Svetuknov and Boylan, 2017). Например, продажи зелёной губной помады имеют такой характер: её редко, кто покупает, но это всё-таки происходит время от времени. Данные по продажам такой продукции будут содержать много нулей, и предсказать, когда именно произойдёт продажа такого товара — крайне затруднительно. Может показаться, что я беру в пример какой-то экзотический товар, а значит и проблема прерывистого спроса надумана. Но вообще-то это не так. Если обратиться к тому, что происходит сейчас в сфере ритейла, то на себя обращает внимание увеличение частоты измерений данных. Раньше была возможность только сохранять количество проданных каких-нибудь хлопьев в неделю, сейчас же можно измерять продажи хоть раз в минуту (можно и чаще, но надо ли?). А как предсказать, когда купят хлопья в магазине, когда данные измеряются в такой частоте? В общем, проблема есть, и она вполне реальна.
Другая типичная проблема — это продукты, продающиеся сезонно. Например, продажи арбузов летом будут носить вполне себе непрерывный характер, а вот в остальное время года — не факт: в какие-то сезоны их не будет физически (естественные нули), а в другие спрос на них будет нестабилен.
В общем, со всеми этими интересными особенностями как раз и призваны справиться функции пакета smooth. Для этого в нём реализованы так называемые модели со смешанными распределениями.
В данной статье мы обсудим самую простую, можно сказать, базовую модель, реализованную в пакете.
Здесь мы будем делать акцент на прерывистый спрос, но вообще-то функции хорошо работают и в других случаях, в которых возникают нули в данных.
Модель
Во-первых, стоит заметить, что всё, что мы будем далее обсуждать основано на идее разделения ряда прерывистого спроса на две части (Croston, 1972):
- Появление спроса, которая представлена бинарной переменной (0 — спроса нет, 1 — спрос есть);
- Размер спроса, которая отражает, сколько единиц продукции было куплено, если спрос появился.
Математически это всё представляется вот так вот:
\begin{equation} \label{eq:iSS}
y_t = o_t z_t ,
\end{equation}
где \(o_t\) — это бинарная переменная появления, \(z_t\) — это объём спроса и \(y_t\) — это финальная величина, которую мы измеряем. Это уравнение было предложено в Croston, (1972), хотя Кростон ограничился лишь разработкой прогнозного метода, и не занимался стохастической моделью.
В литературе встречается несколько методов для прогнозирования прерывистого спроса: Кростон (Croston, 1972), SBA (Syntetos & Boylan, 2000 — SBA — Syntetos-Boylan Approximation) и TSB (Teunter et al., 2011 — по фамилиям авторов метода). Это всё хорошие методы, которые себя хорошо зарекомендовали. Единственное ограничение — это то, что они «методы», а не «стохастические модели». Модель позволяет достаточно легко включать дополнительные компоненты и переменные, конструировать прогнозные интервалы и возможность осуществлять выбор наилучшей модели среди некоторого пула. Не имея модель, всё это сделать затруднительно. Мы с Джоном Бойланом (John Boylan) разработали модель, которая лежит в основе этих методов (Svetunkov & Boylan, 2017), с помощью \eqref{eq:iSS}. Учитывая то, что все эти методы основаны на простом экспоненциальном сглаживании, мы назвали свою модель «iETS» — «intermittent ETS» — «прерывистая ETS». В статье, которая сейчас находится на стадии рецензирования в International Journal for Forecasting, мы рассматривали частный случай этой модели — iETS(M,N,N), то есть модель с мультипликативной ошибкой, без тренда и сезонности, так как именно эта модель лежит в основе простого экспоненциального сглаживания. Одно из ключевых предположений в нашей модели — это независимость появления спроса от размера спроса. Это, конечно, явное упрощение, которой мы получили по наследству от метода Кростона, но даже с ним модель работает хорошо в большинстве случаев.
Модель iETS(M,N,N) формулируется следующим образом:
\begin{equation} \label{eq:iETS}
\begin{matrix}
y_t = o_t z_t \\
z_t = l_{z,t-1} \left(1 + \epsilon_t \right) \\
l_{z,t} = l_{z,t-1}( 1 + \alpha_z \epsilon_t) \\
o_t \sim \text{Bernoulli}(p_t)
\end{matrix} ,
\end{equation}
где \(z_t\) — это модель ETS(M,N,N), \(l_{z,t}\) это уровень ненулевого спроса, \(\alpha_z\) — постоянная сглаживания, а \(\epsilon_t\) — ошибка модели. Важное допущение в модели — это то, что \(\left(1 + \epsilon_t \right) \sim \text{log}\mathcal{N}(0, \sigma_\epsilon^2) \) — нечто, что мы уже как-то обсуждали. Это допущение важно, так как ограничивает область значений только положительными значениями. Впрочем, если в вашем контексте возможны так же и отрицательные значения, то никто не мешает вместо мультипликативных моделей использовать аддитивные.
Прелесть модели \eqref{eq:iETS} заключается в том, что она может быть легко расширена (в неё можно добавить тренд, сезонность, экзогенные переменные), и то, что все её параметры могут быть оценены путём максимизации функции правдоподобия.
Для моделирования части, отвечающей за появление спроса, мы предложили следующие три модели:
- iETS\(_F\) — модель предполагает, что вероятность появления спроса фиксирована (\(p_t = p\)).
- iETS\(_O\) — «Odds Ratio», модель отношения шансов, которая использует логистическую кривую для обновления вероятности появления значения. В этом случае модель сфокусирована именно на вероятности появления спроса.
- iETS\(_I\) — «Inverse Odds Ratio», модель обратного отношения шансов, которая использует похожие принципы, как и iETS\(_O\), однако прогнозы её сфокусированы на вероятности не появления спроса. Эта модель даёт статистическое объяснение для метода Croston (1972), но использует несколько другой принцип обновления вероятности: вместо того, чтобы обновлять вероятность, когда происходит продажа, она это делает на каждом наблюдении.
- iETS\(_D\) — «Direct probability», модель непосредственной вероятности, которая использует принцип, предложенный Teunter et al., (2011). В этом случае вероятность обновляется на прямую с помощью простого экспоненциального сглаживания.
- iETS\(_G\) — «General», обобщённая модель, которая фактически включает в себя все предыдущие. Она состоит из двух под-моделей для вероятности, фактически учитывая как вероятности возникновения, так и вероятность не возникновения продаж.
В случае (1) модель для вероятности значительно упрощается, её можно оценить с помощью функции правдоподобия и использовать для прогноза. В остальных случаях мы предлагаем использовать ещё одну модель ETS(M,N,N) для каждой из частей процессов. Так что в каждом из этих случаев прогноз представляет собой прямую линию. Финальный прогноз для всех этих моделей считается по формуле:
\begin{equation} \label{eq:iSSForecast}
\hat{y}_{t+h} = \hat{p}_{t+h} \hat{z}_{t+h} ,
\end{equation}
где \(\hat{p}_{t+h}\) — это прогнозируемая вероятность, \(\hat{z}_t\) — это прогнозируемый объём спроса, а \(\hat{y}_t\) — это финальный прогноз для прерывистого спроса. Фактически на выходе мы получает некую оценку того, сколько будет продано в среднем за единицу времени.
Для того, чтобы разделить общую модель \eqref{eq:iETS} с её частью для объёмов спроса и для появления спроса, мы предлагаем использовать разные названия. Например, iETS\(_G\)(M,N,N) обозначает полную модель \eqref{eq:iETS} (\(y_t\)), oETS\(_G\)(M,N,N) обозначает модель для появления спроса (\(o_t\)), а ETS(M,N,N) используется для обозначения модели для объёмов спроса (\(z_t\)). Во всех этих трёх случаях часть «(M,N,N)» показывает, что мы используем модель экспоненциального сглаживания с мультипликативной ошибкой, без тренда и сезонности. Более продвинутые обозначения для модели будут обсуждены в следующих статьях на сайте. Пока же мы будем ориентироваться на простую модель экспоненциального сглаживания.
Обобщая преимущества нашей модели:
- Она расширяема. Это означает, что в неё можно добавлять любые компоненты, которые вы пожелаете. Такая возможность уже существует в пакете smooth. К слову, базовая модель \eqref{eq:iSS} позволяет использовать всё, что угодно для объёма спроса и множество разных моделей для появления спроса;
- Модель позволяет выбирать между теми самыми пятью случаями (iETS\(_F\), iETS\(_O\), iETS\(_I\), iETS\(_D\) и iETS\(_G\)) с помощью информационных критериев. Этот механизм работает хорошо на больших выборках, но не всегда показывает такие же хорошие результаты на малых;
- Модель позволяет конструировать параметрические прогнозные интервалы на несколько шагов вперёд;
- Оценка моделей осуществляется с помощью функции правдоподобия, которая даёт эффективные и состоятельные оценки;
- Хотя модель и предполагает непрерывную случайную величину для объёма спроса, мы показали в своей статье, что она часто работает лучше, чем модели целочисленных случайных величин (типа Пуассона или Биномиального распределения).
Что же, посмотрим, как это работает…
Появление спроса
В пакете smooth есть функция oes() (Occurrence Exponential Smoothing), которая отвечает за модель появления спроса. Так же, в каждой прогнозной функции пакета есть параметр occurrence, который может быть: «none» (никакой модели), «fixed» (oETS\(_F\)), «odds-ratio» (oETS\(_O\)), «inverse-odds-ratio» (oETS\(_I\)), «direct» (oETS\(_D\)), «general» (oETS\(_G\)) и «auto» (автоматический выбор). Автоматическую опцию мы пока не рассматриваем, обсудим те самые пять моделей. Рассмотрим их на условном примере:
x <- c(rpois(25,5),rpois(25,1),rpois(25,0.5),rpois(25,0.1))
В этом искусственном временном ряду вероятность и размер спроса меняются ступенчато каждые 25 наблюдений. Сгенерированные данные отражают нечто под названием "вымирающий спрос" или "устаревающий спрос". Построим наши три модели:
oesFixed <- oes(x, occurrence="f", h=25)
Occurrence state space model estimated: Fixed probability
Underlying ETS model: oETS[F](MNN)
Smoothing parameters:
level
0
Vector of initials:
level
0.55
Information criteria:
AIC AICc BIC BICc
139.6278 139.6686 142.2329 142.3269
oesOdds <- oes(x, occurrence="o", h=25)
Occurrence state space model estimated: Odds ratio
Underlying ETS model: oETS[O](MNN)
Smoothing parameters:
level
0.828
Vector of initials:
level
14.442
Information criteria:
AIC AICc BIC BICc
116.3124 116.4361 121.5227 121.8076
oesInverse <- oes(x, occurrence="i", h=25)
Occurrence state space model estimated: Inverse odds ratio
Underlying ETS model: oETS[I](MNN)
Smoothing parameters:
level
0.116
Vector of initials:
level
0.039
Information criteria:
AIC AICc BIC BICc
98.5508 98.6745 103.7611 104.0460
oesDirect <- oes(x, occurrence="d", h=25)
Occurrence state space model estimated: Direct probability
Underlying ETS model: oETS[D](MNN)
Smoothing parameters:
level
0.115
Vector of initials:
level
0.884
Information criteria:
AIC AICc BIC BICc
106.5982 106.7219 111.8086 112.0934
oesGeneral <- oes(x, occurrence="g", h=25)
Occurrence state space model estimated: General
Underlying ETS model: oETS[G](MNN)(MNN)
Information criteria:
AIC AICc BIC BICc
102.5508 102.9718 112.9715 113.9410
Анализируя результаты, можно заметить, что модель oETS\(_I\) показала себя лучше на этих данных - её информационные критерии ниже, чем у других моделей. Это всё потому что данный тип модели хорошо подходит под ряды с угасающим спросом из-за того, что модель сфокусирована на вероятности исчезновения. Обратите внимание, что постоянная сглаживания в модели oETS\(_O\) достаточно высока. Это потому что модель сфокусирована на вероятности возникновения спроса, а он у нас угасает. Если бы динамика была противоположной (частота спроса возрастала), то и ситуация была бы другой: постоянная сглаживания в oETS\(_O\) была бы ниже, чем постоянная сглаживания в oETS\(_I\). Так же можно заметить, что стартовый уровень в модели oETS\(_I\) равен 0.116, что соответствует вероятности возникновения в \(\frac{1}{1+0.116} \approx 0.89\).
На себя так же обращает внимание модель oETS\(_G\), которая не спешит делиться деталями о моделях внутри неё. Это потому что в ней две модели (которые называются modelA и modelB в R), каждая из которых имеет свои параметры. Вот они:
oesGeneral$modelA oesGeneral$modelB
Occurrence state space model estimated: General
Underlying ETS model: oETS(MNN)_A
Smoothing parameters:
level
0
Vector of initials:
level
16
Information criteria:
AIC AICc BIC BICc
98.5508 98.6745 103.7611 104.0460
Occurrence state space model estimated: General
Underlying ETS model: oETS(MNN)_B
Smoothing parameters:
level
0.116
Vector of initials:
level
0.628
Information criteria:
AIC AICc BIC BICc
98.5508 98.6745 103.7611 104.0460
oETS\(_G\) и обе подмодели A и B имеют одно и то же значение функции правдоподобия, так как они являются частями единого целого. Однако информационные критерии у них различаются, так как у них разное число оценённых параметров: в моделях A и B их по двое, в то время как в целой модели их, соответственно, 4. Заметьте, что оптимальная постоянная сглаживания в модели A оказалась равной нулю, что означает, что компоненты её не обновляются во времени. Мы ещё вернёмся к этому наблюдению чуть позже.
Мы так же можем построить линейные графики по этим моделям, чтобы увидеть, как именно они работают:
plot(oesFixed)
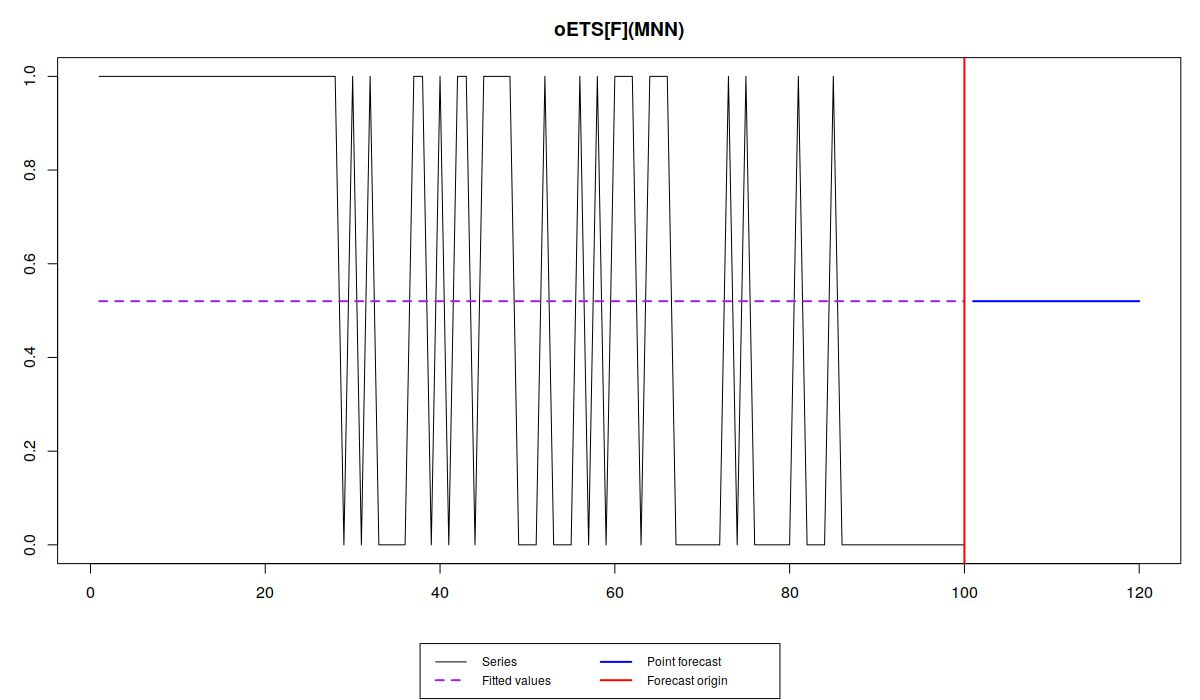
plot(oesOdds)
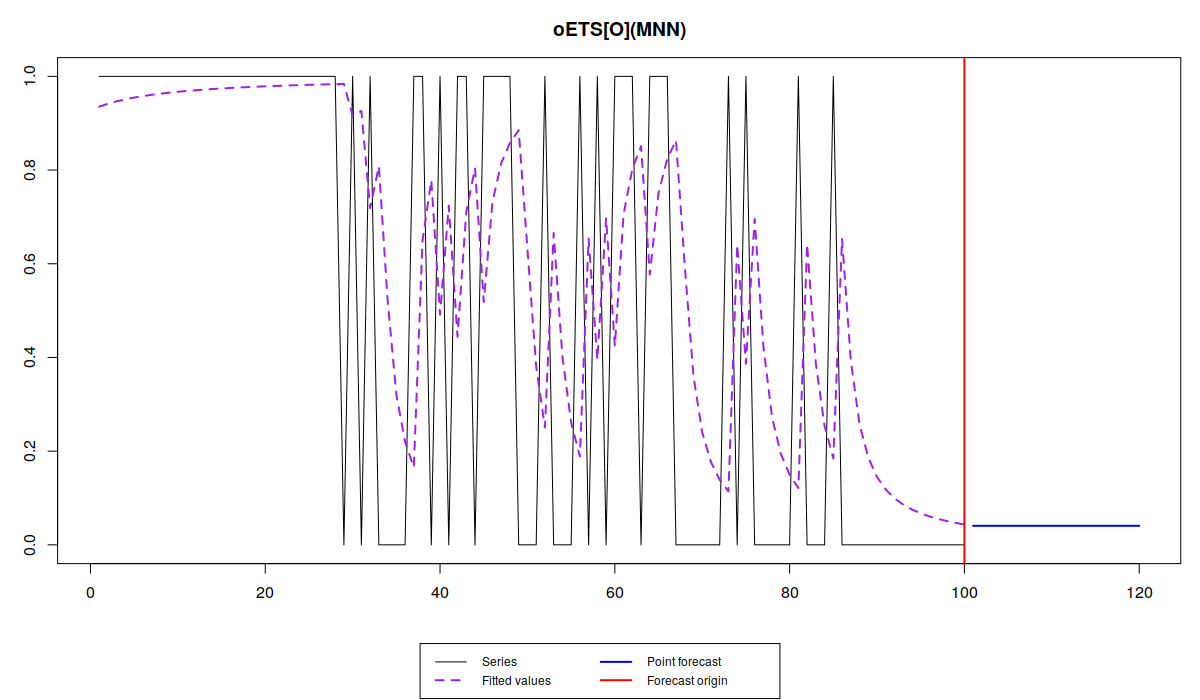
plot(oesInverse)
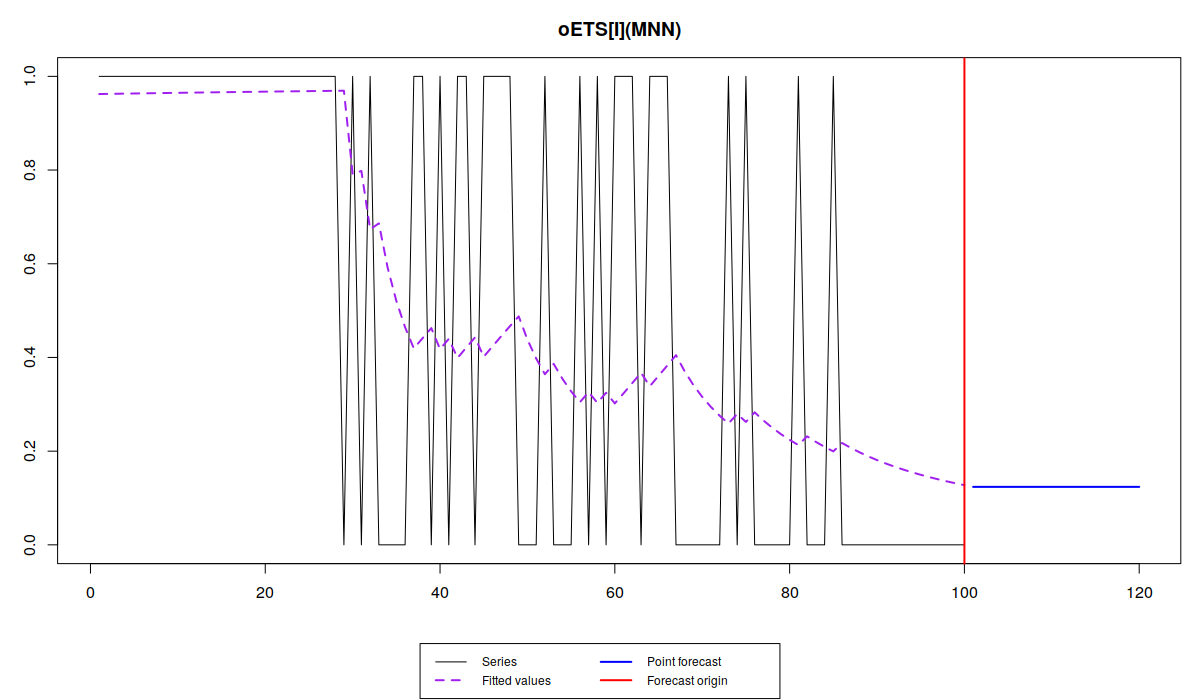
plot(oesDirect)
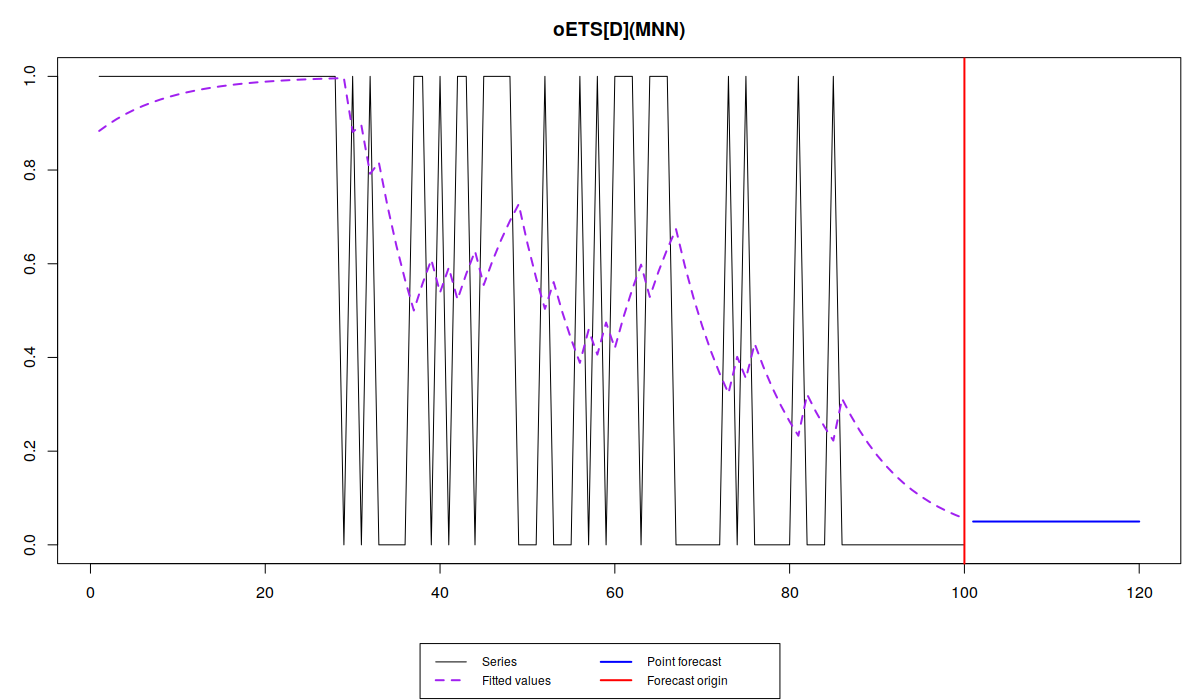
plot(oesGeneral)
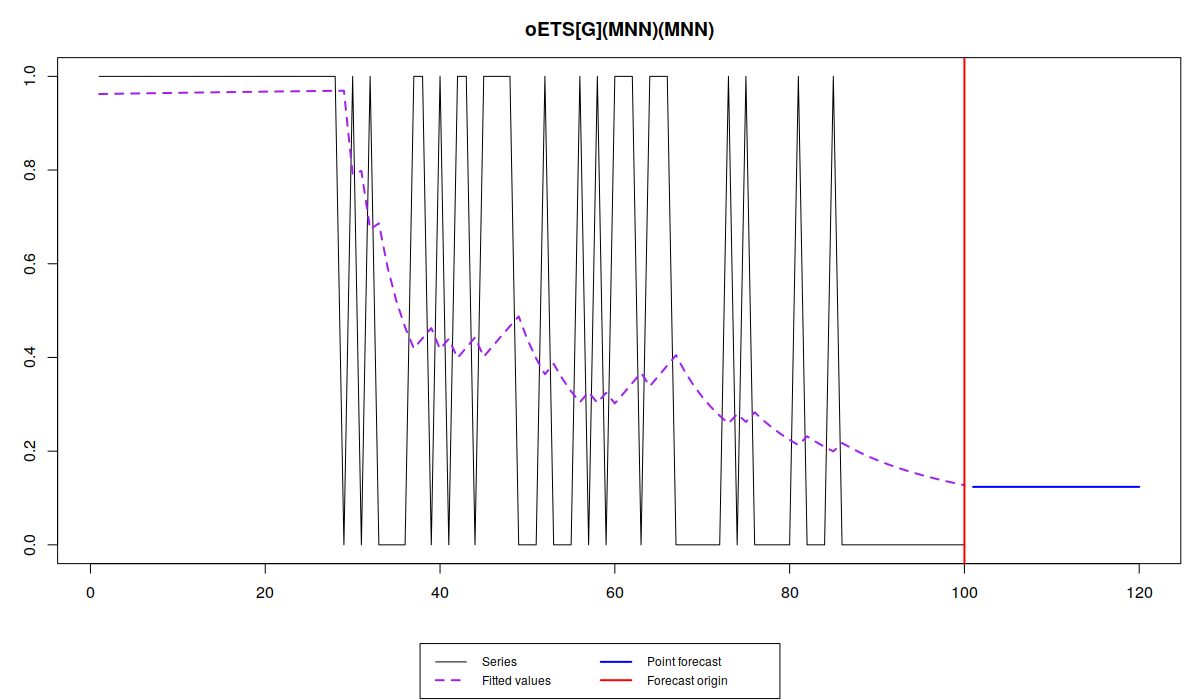
Обратите внимание, что разные модели улавливают динамику вероятности по-разному: в то время как iETS\(_F\) всё усредняет, остальные модели реагируют на изменения вероятности, но не одинаково.
Так oETS\(_O\) более живо реагирует на динамику появления спроса, пытаясь угнаться за меняющейся вероятностью. Модель oETS\(_I\) при этом ведёт себя спокойней, воспроизводя более гладкую линию. oETS\(_D\) оказалась реактивней предыдущей модель, но не такой резкой, как модель отношения шансов. Ну, и модель oETS\(_G\) скопировала динамику модели oETS\(_I\). Это всё из-за того, что оптимальная постоянная сглаживания в модели A в oETS\(_G\) оказалась равной нулю, что привело к тому, что модель oETS\(_G\) выродилась в oETS\(_I\). Тем не менее, все эти модели спрогнозировали, что вероятность спроса будет достаточно низкой, что соответствует динамики сгенерированного ряда.
Что же, перейдём к полной модели...
Полная модель
Для того, чтобы дать финальный прогноз для прерывистого спроса, мы можем использовать любую прогнозную функцию из пакета: es(), ssarima(), ces(), gum() - во всех них есть соответствующий параметр occurrence, который по умолчанию равен "none". Для простоты пока будем использовать модель ETS. И для простоты мы будем использовать iETS\(_I\), так как она хорошо себя проявила на этом ряде:
es(x, "MNN", occurrence="i", silent=FALSE, h=25)
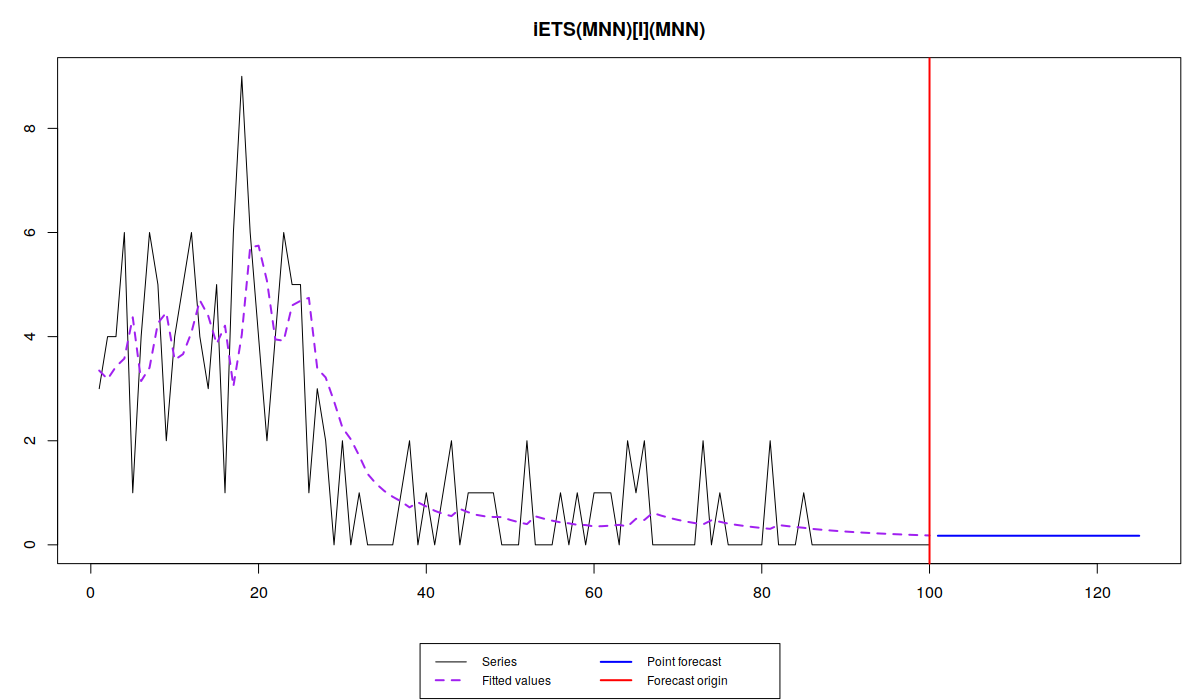
Прогноз этой модели - прямая линия, близкая к нулю, что вызвано снижением значений как в объёме спроса, так и в вероятности появления. Однако, зная, что спрос снижается, мы можем использовать модель с трендом для объёма спроса, ETS(M,M,N):
es(x, "MMN", occurrence="i", silent=FALSE, h=25)
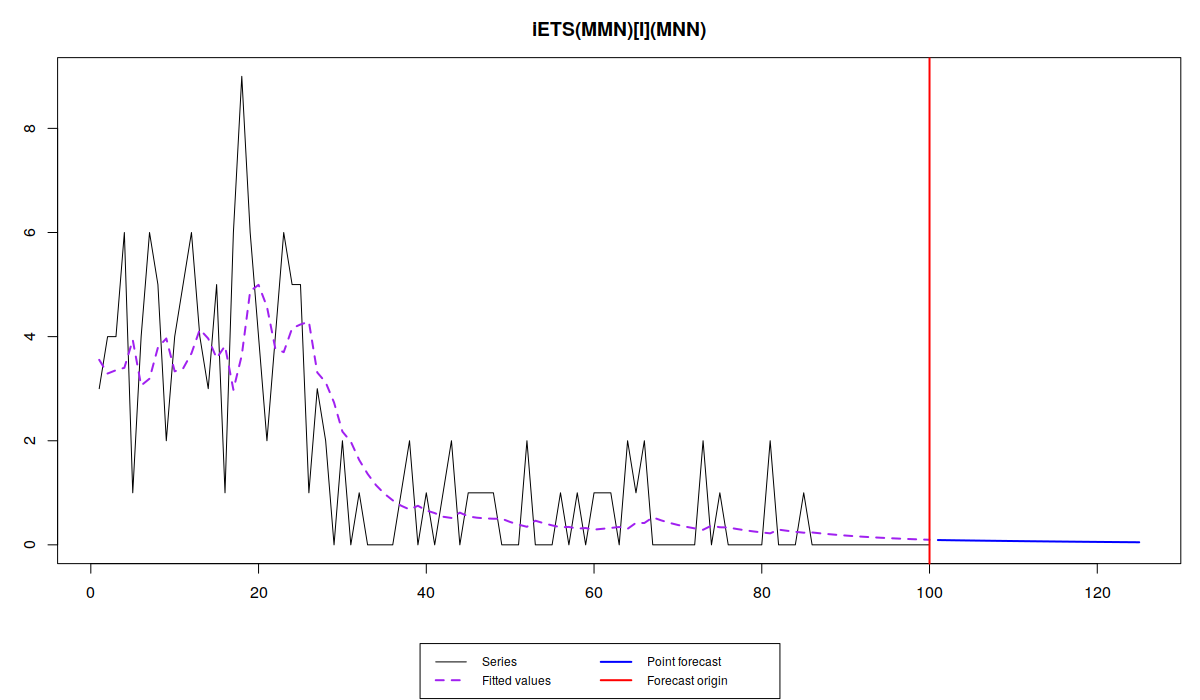
Прогноз в этом случае оказывается ближе к нулю, а уж асимптотически он точно будет нуль... Это означает, что мы имеем дело с угосающим спросом.
Мы можем так же построить прогнозные интервалы и использовать модель с автоматическим выбором компонент для объёма спроса. Если мы знаем, что данные не могут быть отрицательными (например, какие-нибудь продажи помидоров), то я бы рекомендовал обратиться к чистым мультипликативным моделям:
es(x, "YYN", occurrence="i", silent=FALSE, h=25, intervals=TRUE)
Forming the pool of models based on... MNN, MMN, Estimation progress: 100%... Done!
Time elapsed: 1.02 seconds
Model estimated: iETS(MMN)
Occurrence model type: Inverse odds ratio
Persistence vector g:
alpha beta
0.268 0.000
Initial values were optimised.
7 parameters were estimated in the process
Residuals standard deviation: 0.386
Cost function type: MSE; Cost function value: 0.149
Information criteria:
AIC AICc BIC BICc
333.4377 334.0760 348.5648 339.9301
95% parametric prediction intervals were constructed
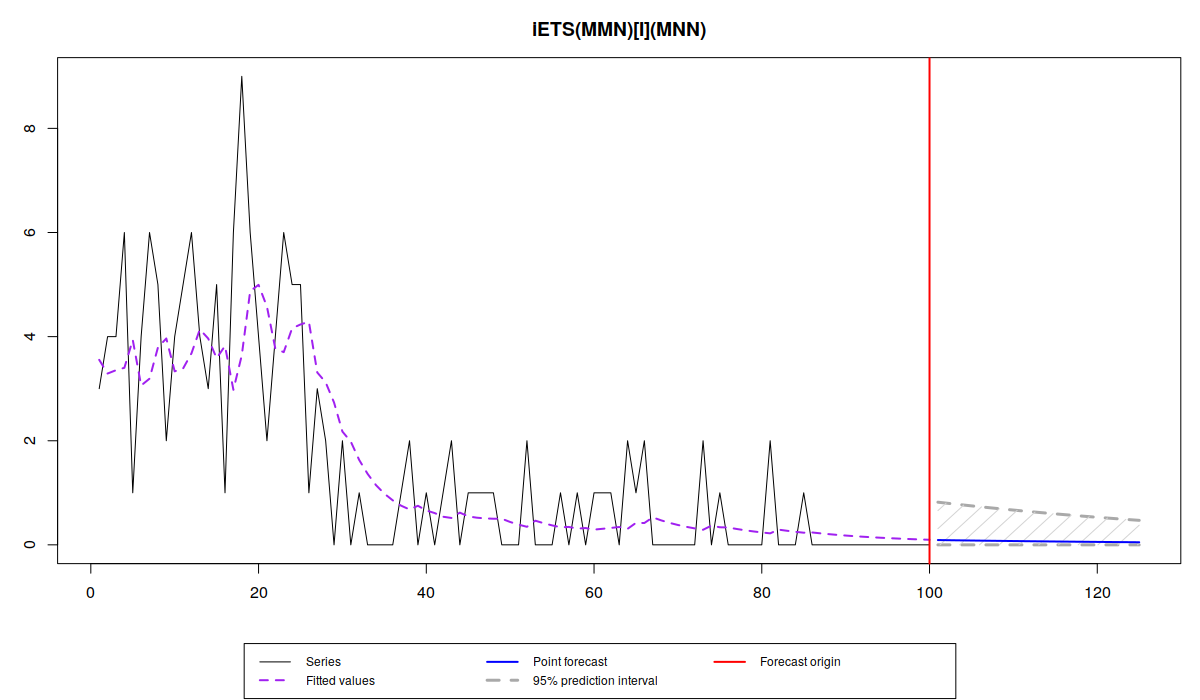
Как видим, в данном случае наиболее подходящей оказалась модель с мультипликативным трендом. Прогнозные интервалы в этом случае сужаются, так как уровень спроса приближается к нулю. Сравните этот график с графиком чистой аддитивной модели:
es(x, "XXN", occurrence="i", silent=FALSE, h=25, intervals=TRUE)
Forming the pool of models based on... ANN, AAN, Estimation progress: ... Done!
Time elapsed: 0.23 seconds
Model estimated: iETS(ANN)
Occurrence model type: Inverse odds ratio
Persistence vector g:
alpha
0.251
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 1.125
Cost function type: MSE; Cost function value: 1.265
Information criteria:
AIC AICc BIC BICc
459.8706 460.1206 472.8964 464.2617
95% parametric prediction intervals were constructed
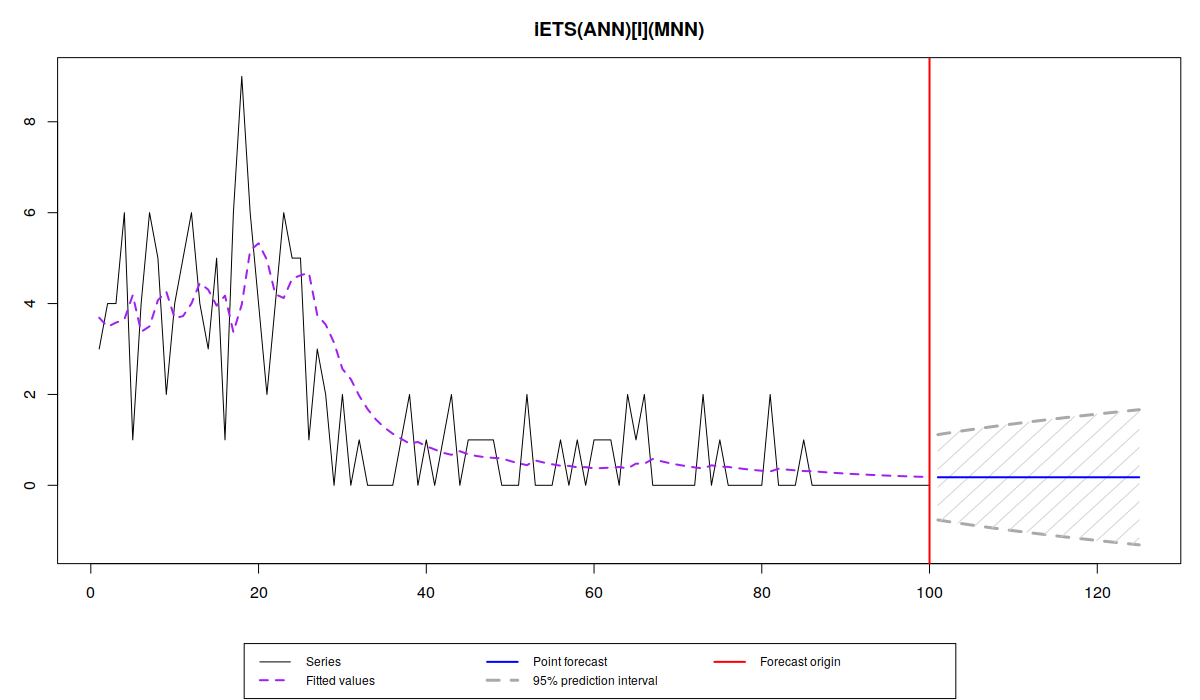
В последнем случае нижняя граница интервала оказывается отрицательной, что в некоторых случаях не имеет смысла. Обратите внимание так же, что информационные критерии для чистой мультипликативной модели оказались ниже. Это из-за того, что мы имеем дело с гетероскедастичностью: дисперсия спроса меняется каждый 25 наблюдений, вместе с изменением уровня ряда.
Здесь нужно сделать важную ремарку. Несмотря на то, что я бы рекомендовал использовать чистые мультипликативные модели, модель ETS(M,M,N) с положительным трендом взрывоопасна. Фактически мы имеем дело с экспонентой, а значит и прогноз может быть в форме взрывного спроса. Пока что решения этой проблемы нет, так что я бы рекомендовал вручную выбирать между ETS(M,N,N) и ETS(M,Md,N) (модель с демпфированным трендом). Я не рекомендую модели с аддитивным трендом, так как в случае с низким уровнем ряда и негативным трендом может получаться всякий бред (отрицательные значения и лош-нормальное распределение - это что-то странное).
Как видим, теперь в нашем распоряжении оказалось на пять моделей экспоненциального сглаживания больше, что может усложнить жизнь практикующему прогнозисту. Теперь надо понять, как выбрать наиболее подходящую модель из этих пяти, как выбрать модель экспоненциального сглаживания для oETS (не останавливаться же на простом экспоненциальном сглаживании при прогнозировании вероятности возникновения) и как включать объясняющие переменные в модель. Если бы мы могли всё это сделать, то это расширило бы инструментарий для прогнозирования в разы, не так ли? Всё это, на самом деле, уже доступно в пакете smooth, и мы перейдём к этим деталям в следующей статье. До новых встреч!