



Одно из преимуществ функций пакета smooth — это возможность использовать экзогенные переменные (регрессоры). Это потенциально может привести к росту точности прогнозов, в случае, если у вас в распоряжении есть хорошие оценки будущих значений включённых переменных. Например, в случае с ритейлом в качестве экзогенной переменной может выступать наличие акции в магазине («купите один шампунь, получите ящик пива в подарок»). Эту информацию мы можем знать заранее, причём со 100% точностью, если мы планируем проводить похожие акции в будущем. И, конечно же, использование этой информации должно повысить точность прогнозов по нашей модели.
Для подобных целей в R уже есть функция arima() из пакета stats, но, к сожалению, любимая практикующими прогнозистами модель экспоненциального сглаживания (ets() из пакета forecast) не поддерживает экзогенные переменные. Это была одна из причин, почему я взялся за разработку функций пакета smooth. Теперь все функции в пакете (кроме sma()) предоставляют возможность по включению экзогенных переменных.
В smooth реализовано две модели для работы с экзогенными переменными: модель с аддитивными и с мультипликативными ошибками. Первая формулируется следующим образом:
\begin{equation} \label{eq:additive}
y_t = w’ v_{t-l} + a_1 x_{1,t} + a_2 x_{2,t} + … + a_k x_{k,t} + \epsilon_t ,
\end{equation}
где \(a_1, a_2, …, a_k\) — параметры соответствующих регрессоров \(x_{1,t}, x_{2,t}, …, x_{t,k}\). Все остальные переменные мы уже обсуждали в предыдущих статьях.
Вторая модель выглядит немного по-другому, так как она основана на мультипликативной ETS:
\begin{equation} \label{eq:multiplicative}
\log y_t = w’ \log(v_{t-1}) + a_1 x_{1,t} + a_2 x_{2,t} + … + a_k x_{k,t} + \log(1 + \epsilon_t) ,
\end{equation}
Она может быть так же представлена в следующем виде:
\begin{equation} \label{eq:multiplicativeAlternative}
y_t =\exp \left({w’ \log(v_{t-1})} \right) \exp(a_1 x_{1,t}) \exp(a_2 x_{2,t}) \dots \exp(a_k x_{k,t}) (1 + \epsilon_t).
\end{equation}
Эта модель соответствует лог-линейной. Такая форма принята для того, чтобы в качестве экзогенных можно было бы использовать фиктивные переменные. Если вам нужна лог-лог модель, то для этого достаточно всего лишь прологарифмировать экзогенную переменную перед использованием её в функции.
Важно отметить, что смешанные модели могут вызвать проблемы, так как в таком случае некоторые компоненты складываются, а другие — перемножаются. Поэтому я бы рекомендовал использовать либо чистые аддитивные, либо чистые мультипликативные ETSX (в статье про выбор моделей описано, как можно осуществить выбор на основе чистых моделей).
Итак, для того, чтобы построить модель с заданными регрессорами, достаточно просто передать в функцию вектор, матрицу либо data.frame:
ourModel <- es(BJsales, "XXN", xreg=BJsales.lead, h=10, holdout=TRUE, silent=FALSE)
Estimation progress: 100%... Done!
Time elapsed: 0.27 seconds
Model estimated: ETSX(AAdN)
Persistence vector g:
alpha beta
0.939 0.301
Damping parameter: 0.877
Initial values were optimised.
7 parameters were estimated in the process
Residuals standard deviation: 1.381
Xreg coefficients were estimated in a normal style
Cost function type: MSE; Cost function value: 1.811
Information criteria:
AIC AICc BIC
494.4490 495.2975 515.0405
Forecast errors:
MPE: 1.2%; Bias: 91.3%; MAPE: 1.3%; SMAPE: 1.3%
MASE: 2.794; sMAE: 1.5%; RelMAE: 0.917; sMSE: 0%
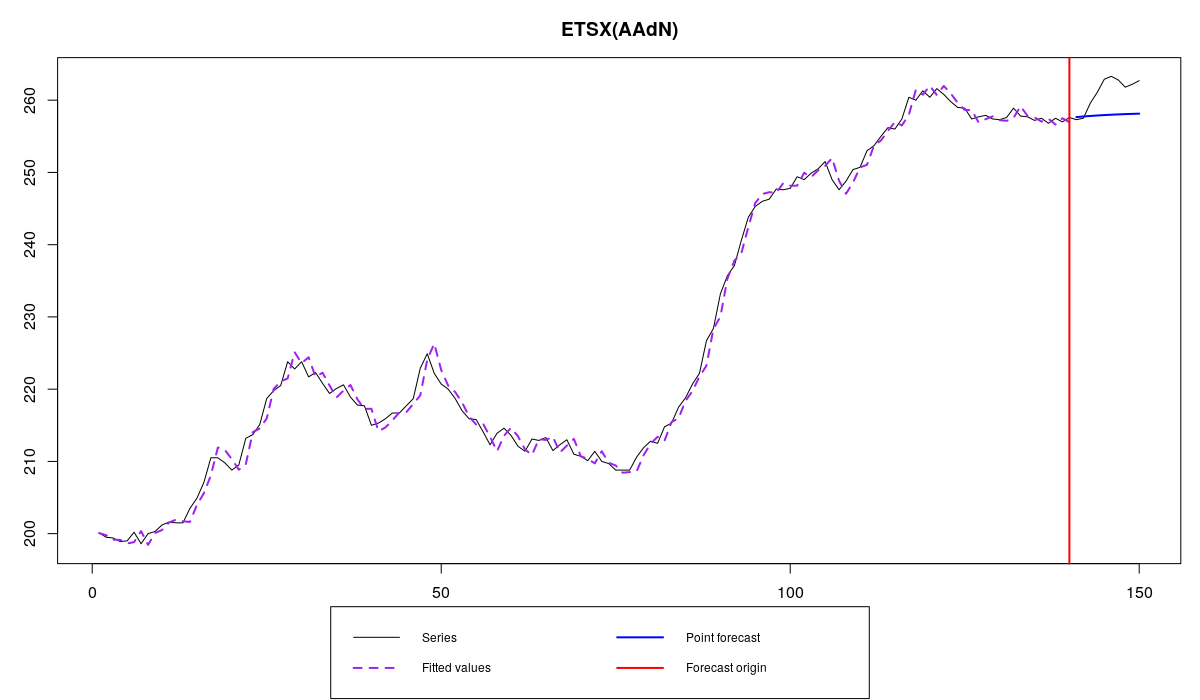
BJsales series and ETSX with a leading indicator
В этом примере мы используем данные о продажах из книги Box & Jenkins (1976). Я попросил функцию использовать провести процедуру ретропрогноза и сделать прогноз на 10 шагов вперёд, так что последние 10 наблюдений переменной BJsales.lead используются для построения прогнозов. Функция построила модель и доложила нам, что параметры были оценены обычным методом (7 parameters were estimated in the process). Это значит, что мы предполагаем, что коэффициенты при регрессорах не меняются во времени. Альтернативный этому подход будет рассмотрен когда-нибудь в будущем.
Судя по всему, выбранная модель ETS(A,Ad,N) дала не самые точные, да ещё и смещённые прогнозы (систематическое отклонение от фактических значений в проверочной выборке). Пока что особых улучшений от включения переменной не видно...
Если в какой-то момент времени вы, вдруг, забудете о том, какая именно модель перед вами, вы можете воспользоваться функцией formula(), которая в случае с функциями smooth носит чисто описательный характер:
formula(ourModel)
"y[t] = l[t-1] + b[t-1] + a1 * x[t] + e[t]"
Функция рассказала нам, что уровень l[t-1], тренд b[t-1], экзогенная переменная "x[t]" и ошибка в нашей модели складываются. Если бы мы передали матрицу с экзогенными переменными или же построили модель с динамически меняющимися параметрами, то это было бы отражено в формуле. Использовать эту формулу так же, как и это сделается в lm(), к сожалению, нельзя.
Для сравнения построим следующую смешанную модель и посмотрим на её формулу:
ourModel <- es(BJsales, "MAN", xreg=BJsales.lead, h=10, holdout=TRUE) formula(ourModel)
"y[t] = (l[t-1] + b[t-1]) * exp(a1 * x[t]) * e[t]"
Как видим, вначале тренд и уровень складываются, а потом это всё умножается на экспоненту нашей переменной. Если по какой-то причине тренд будет негативным, а уровень окажется близок к нулю, то экзогенная переменная будет умножена на отрицательное число. В результате получится бессмысленный прогноз. Это одна из причин, почему я не люблю смешанные модели и говорю, что использовать их надо с осторожностью.
Однако, вернёмся к нашим баранам. Если в нашем распоряжении нет значений экзогенной переменной для проверочной части выборки, то функции пакета smooth автоматически построят прогнозы для каждой из экзогенных переменных с помощью es() или iss() в зависимости от того, имеем мы дело с обычной или же с бинарной переменной. В последнем случае в качестве прогноза будет получена условная средняя, поэтому не удивляйтесь, если для вашей фиктивной переменной прогнозом будет что-нибудь типа 0,784. Так что не стоит использовать функцию вслепую, когда holdout=FALSE, будьте осторожны. Вот как функция работает в этом случае:
es(BJsales, "XXN", xreg=BJsales.lead, h=10, holdout=FALSE, silent=FALSE)
Нам должны сообщить о том, что функция сделала для нас (построила прогнозы экзогенных переменных):
Warning message: xreg did not contain values for the holdout, so we had to predict missing values.
Если ваши переменные по размеру превышают выходную переменную, то функция удалит последние лишние наблюдения:
ourModel <- es(BJsales[1:140], "XXN", xreg=BJsales.lead, h=10, holdout=TRUE)
и сообщит нам об этом:
Warning message: xreg contained too many observations, so we had to cut off some of them.
Как видите, функцию можно использовать напрямую, но, если вам хочется работать с forecast() (что совершенно необязательно), то это можно сделать так:
forecast(ourModel, h=10, xreg=BJsales.lead)
Из-за того, как реализовано использование экзогенных переменных в функциях пакета smooth, переменная xreg должна содержать все значения, а не только те, которые соответствуют проверочной выборке. Если вы вместо xreg передадите значения из проверочной выборки, то функция решит, что у вас мало наблюдений и построит прогнозы.
Я бы рекомендовал плюнуть на функцию forecast() и использовать es(), ssarima() и другие функции пакета smooth напрямую. Так вы сможете подготовить свои переменные и использовать их напрямую без дополнительных строк кода.
Аналогично тому, как это обсуждалось в прошлой статье, вы можете попросить функцию построить прогнозные интервалы. Только имейте в виду, что параметрические интервалы на данный момент не очень точны, так как не берут в расчёт возможный корреляции между экзогенными переменными и компонентами ETS. Сделать это сложно, поэтому эта функция и не реализована. Поэтому я бы рекомендовал в случае с ETSX, ARIMAX и пр. строить полупараметрические и непараметрические интервалы.
Наконец, вы всегда можете задать параметры для экзогенных переменных вручную, через переменную initialX:
ourModel <- es(BJsales, "XXN", xreg=BJsales.lead, h=10, holdout=T, initialX=c(-1))
Помимо всего этого, функции достаточно умны, чтобы определить, коррелируют ли переданные регрессоры друг с другом и есть ли в них дисперсия. Если что-то из переданного функции не так, она выкинет те переменные, которые вызывают проблемы:
es(BJsales, "XXN", xreg=cbind(BJsales.lead,BJsales.lead), h=10, holdout=TRUE)
Warning message: Some exogenous variables were perfectly correlated. We've dropped them out.
Из-за того, что мы включили BJsales.lead дважды, регрессор вызвал совершенную мультиколлинеарность, поэтому функция выкинула один из них.
es(BJsales, "XXN", xreg=cbind(BJsales.lead,rep(100,150)), h=10, holdout=TRUE)
Warning message: Some exogenous variables do not have any variability. Dropping them out.
А тут функция заметила, что вторая переменная постоянна, а значит и не может быть использована для моделирования, и, опять же, выкинула её.
Если вы случайно включите выходную переменную (в нашем примере это BJsales) в число регрессоров, то функция так же выкинет её:
es(BJsales, "XXN", xreg=cbind(BJsales,BJsales.lead), h=10, holdout=TRUE)
Warning message: One of exogenous variables and the forecasted data are exactly the same. We have dropped it.
На этом основы заканчиваются. Далее мы перейдём к более продвинутым и интересным аспектам по использованию экзогенных переменных в функциях пакета smooth.
Иван, здравствуйте.
В ходе попытки спрогнозировать временной ряд с экзогенной переменной возникли следующие вопросы.
1. Вектор с экзогенной переменной должен быть той же длины, что и горизонт прогнозирования?
2. Когда мы передаём временной ряд в модель мы также должны сделать его такой же длины, что и вектор с экзогенной переменной, а вместо пропущенных значений поставить нули?
Вектор с экзогенными переменными должен быть по длине либо равен обучающей выборке, либо обучающей + горизонту прогнозирования.
Прогнозирование тут осуществляется с помощью функции es(), то есть forecast() ненужна. В этой статье приводятся примеры того, как разная длина экзогенной переменной влияет на прогнозы.
Что касается пропущенных значений, функция сама заменит их на нули. Вопрос только в том, насколько это подходит к вашей ситуации…
Возможен ли также вариант реализовать возможность как в фукнции lm() писать свою модель с экзогенной переменной. Т.е. сделать вариант типа «ХХХ» -,+, /, *, ^ экзогенная переменная /, *, ^ (коэффициент экзогенной переменной) ?
Такой возможности пока не предусмотрено и мне кажется, что она того не стоит. Любые преобразования экзогенных меременных можно сделать до включения в модель. Если же нужны конкретные коэффициенты, то их можно задавать с помощью параметра initialX.
Иван, здравствуйте.
Скажите может быть в модели более одной экзогенной переменной?