



One of the features of the functions in smooth package is the ability to use exogenous (aka “external”) variables. This potentially leads to the increase in the forecasting accuracy (given that you have a good estimate of the future exogenous variable). For example, in retail this can be a binary variable for promotions and we may know when the next promotion will happen. Or we may have an idea about the temperature for the next day and include it as an exogenous variable in the model.
While arima() function from stats package allows inserting exogenous variables, ets() function from forecast package does not. That was one of the original motivations of developing an alternative function for ETS. It is worth noting that all the forecasting functions in smooth package (except for sma()) allow using exogenous variables, so this feature is not restricted with es() only.
There are two types of models with exogenous variables implemented in smooth functions: additive error model and multiplicative error model. They are slightly different. The former one is formulated as:
\begin{equation} \label{eq:additive}
y_t = w’ v_{t-l} + a_1 x_{1,t} + a_2 x_{2,t} + … + a_k x_{k,t} + \epsilon_t ,
\end{equation}
where \(a_1, a_2, …, a_k\) are parameters for the respective exogenous variables \(x_{1,t}, x_{2,t}, …, x_{t,k}\). All the other variables have been discussed earlier in the previous posts.
The second model is formulated differently, because it is driven by the multiplication of the ETS components by error term:
\begin{equation} \label{eq:multiplicative}
\log y_t = w’ \log(v_{t-1}) + a_1 x_{1,t} + a_2 x_{2,t} + … + a_k x_{k,t} + \log(1 + \epsilon_t) ,
\end{equation}
so this model can be reformlated as:
\begin{equation} \label{eq:multiplicativeAlternative}
y_t =\exp \left({w’ \log(v_{t-1})} \right) \exp(a_1 x_{1,t}) \exp(a_2 x_{2,t}) \dots \exp(a_k x_{k,t}) (1 + \epsilon_t).
\end{equation}
This corresponds to log-linear model. This formulation is adopted because the exponents of exogenous variables allow using dummy variables, which would not be possible in log-log model. This also means that if you want to have a log-log model, you need to take logarithms of the exogenous variables before using them in the functions.
The important thing to note is that the mixed ETS models may cause problems, because some components are added, while the others are multiplied and you may end up with weird cocktail leading to meaningless or unstable forecasts. So in cases of ETSX I would advice sticking with either pure additive or pure multiplicative models, ignoring their combinations (see the model selection post on how to select between the pure models).
In order to construct the model with a set of preselected exogenous variables, all you need to do is to specify the vector, matrix or data.frame with these variables in columns the following way:
ourModel <- es(BJsales, "XXN", xreg=BJsales.lead, h=10, holdout=TRUE, silent=FALSE)
Estimation progress: 100%... Done!
Time elapsed: 0.27 seconds
Model estimated: ETSX(AAdN)
Persistence vector g:
alpha beta
0.939 0.301
Damping parameter: 0.877
Initial values were optimised.
7 parameters were estimated in the process
Residuals standard deviation: 1.381
Xreg coefficients were estimated in a normal style
Cost function type: MSE; Cost function value: 1.811
Information criteria:
AIC AICc BIC
494.4490 495.2975 515.0405
Forecast errors:
MPE: 1.2%; Bias: 91.3%; MAPE: 1.3%; SMAPE: 1.3%
MASE: 2.794; sMAE: 1.5%; RelMAE: 0.917; sMSE: 0%
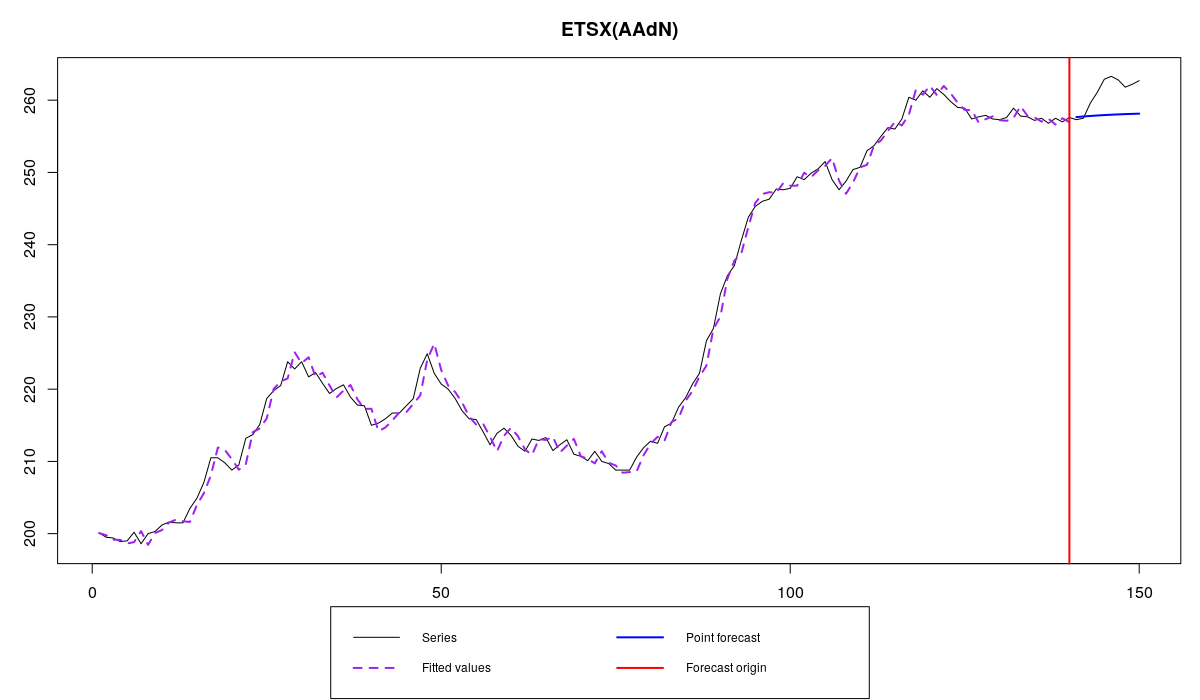
BJsales series and ETSX with a leading indicator
In this example we use sales data from Box & Jenkins (1976) book with a leading indicator. I’ve asked for 10-steps ahead forecast and for the holdout. This means that we don’t need to do anything with the leading indicator, the last 10 actual observations of BJsales.lead will be taken for the forecasting purposes. The function tells us that ETSX model was estimated and points out that the parameters for exogenous variables were "estimated in a normal style", meaning that they are assumed to be constant for all the observations. The option with dynamic parameters will be discussed later.
As we see the selected model is ETS(A,Ad,N), but the produced forecast is not really accurate and seems to be biased.
If you ever get lost and stop understanding what model you have created, you can use formula() function, which in case of smooth functions gives purely descriptive information – the output of that function cannot be used directly in any model. Let’s see what is the formula of our model:
formula(ourModel)
"y[t] = l[t-1] + b[t-1] + a1 * x[t] + e[t]"
This thing tells us that we have level l[t-1], trend b[t-1], one exogenous variable that is called "x[t]" in our case (because we provided a vector) and the error term. If we had a matrix with exogenous variables or a model with dynamic parameters for exogenous variables, this would be reflected in the formula. Just remember, that this is purely descriptive thing. You cannot use this information directly in any other model (as you may usually do with lm() function).
Just for fun, let’s specify a weird mixed model and see its formula:
ourModel <- es(BJsales, "MAN", xreg=BJsales.lead, h=10, holdout=TRUE) formula(ourModel)
"y[t] = (l[t-1] + b[t-1]) * exp(a1 * x[t]) * e[t]"
As it can be seen, we firstly add the trend component to the level and then multiply it by the exponent of our exogenous variable. If for some reason trend is negative and level is low, we will end up with a very weird thing, because the exogenous variable will be multiplied by a negative number. That’s why I say that the mixed models are not safe.
Now, if we do not have the values for the holdout, then the smooth functions will automatically produce forecasts using es() for each of the variables and then use those values in the final forecast of the variable of interest. Beware, that if you use dummy variables, then the forecast will correspond to some sort of conditional mean value (this is then produced by iss() function). This means that you will end up having something like 0.784 as a forecast. So be careful when blindly using the function for the cases of holdout=FALSE. Here’s how it works:
es(BJsales, "XXN", xreg=BJsales.lead, h=10, holdout=FALSE, silent=FALSE)
We should get the following warning:
Warning message: xreg did not contain values for the holdout, so we had to predict missing values.
If your exogenous variable is longer than the variable of interest, then smooth functions will cut off the redundant end of data. For example:
ourModel <- es(BJsales[1:140], "XXN", xreg=BJsales.lead, h=10, holdout=TRUE)
This produces a warning:
Warning message: xreg contained too many observations, so we had to cut off some of them.
This is because xreg contained too many observations, and the function used only the first 140 of them, removing the last ten.
As you see, the function works on its quite well, but if you are kin in using forecast() function together with smooth functions (which is not necessary at all), you can do it the following way:
forecast(ourModel, h=10, xreg=BJsales.lead)
Due to the implementation of exogenous variables in smooth, you need to provide the whole xreg (as much as you have) to the forecast() function. If you provide the values for the holdout only, the function will think that your xreg series is too short and produce forecasts for it. If you provide the values for the in-sample only, the function will once again produce forecasts for each variable in xreg using es() (as discussed above).
Personally, I would advise using es(), ssarima() and other smooth functions directly, ignoring forecast(). This way you can prepare your xreg, and then use it directly without additional lines of code.
Similarly to how it was discussed in the previous post, you can always ask for the prediction intervals and you will have them. But keep in mind that parametric intervals are pretty complicated in case of dynamic models with exogenous variables, because the covariances between the parameters and ETS components are hard to derive. Although the function will produce you anything you ask for it, the parametric intervals may be inaccurate. So I would advise using semiparametric or nonparametric intervals in case of xreg.
Finally, you can always pre-specify the values of xreg parameters if you don’t want them to be estimated. This is controlled using initialX parameter:
ourModel <- es(BJsales, "XXN", xreg=BJsales.lead, h=10, holdout=T, initialX=c(-1))
The function is also smart enough to detect if a provided variable does not have any variability or if some of the variables are highly correlated (correlation or multiple correlations are higher than 0.999). In both of these cases, it will drop some variables and tell us about that:
es(BJsales, "XXN", xreg=cbind(BJsales.lead,BJsales.lead), h=10, holdout=TRUE)
Warning message: Some exogenous variables were perfectly correlated. We've dropped them out.
es(BJsales, "XXN", xreg=cbind(BJsales.lead,rep(100,150)), h=10, holdout=TRUE)
Warning message: Some exogenous variables do not have any variability. Dropping them out.
If you accidentally provide the response variable in xreg, the function will also drop it:
es(BJsales, "XXN", xreg=cbind(BJsales,BJsales.lead), h=10, holdout=TRUE)
Warning message: One of exogenous variables and the forecasted data are exactly the same. We have dropped it.
That’s it for the basic exogenous variables functionality in smooth functions. Next time we will continue with more advanced, more fascinating stuff.