



Прежде чем мы приступим к обсуждению сегоднешней темы, я бы рекомендовал обратиться к статье «Элементы математической статистики, проверка гипотез» электронного учебника — нам понадобятся сегодня такие понятия, как несмещённость, эффективность и состоятельность. Здесь их лишний раз обсуждать нехочется.
Кроме того, многое, что мы рассмотрим сегодня, уже описано в главах «Простые методы оценки параметров моделей» и «Продвинутые методы оценки параметров моделей». Поэтому теортическую часть мы обсуждать не будем, а лучше сконцентрируемся на том, как это сделать в R.
Методы оценки на основе одношаговых прогнозов
Начнём с того, что выберем временной ряд, с которым будем работать. Например, вот такой:
x <- ts(c(M3$N1823$x,M3$N1823$xx),frequency=frequency(M3$N1823$x))
Выглядит он вот так:
plot(x)
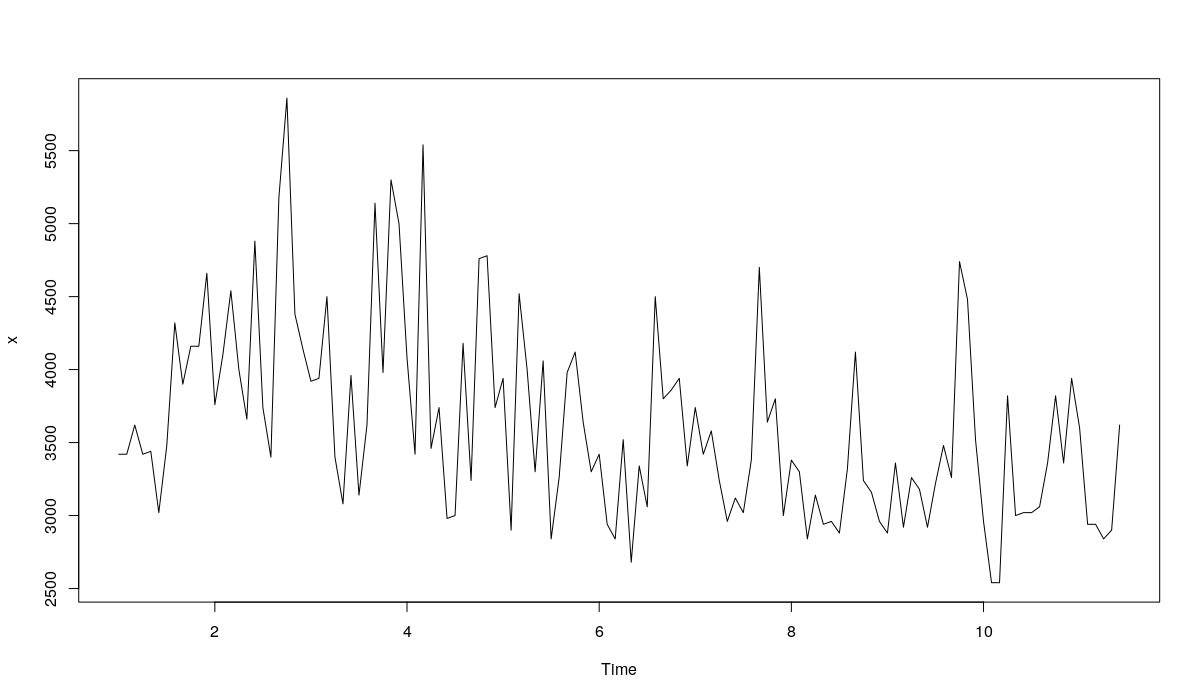
Ряд N1823
Похоже, что в ряде имеется небольшая мультипликативная сезонность, но её тяжело распознать. Для простоты в нашем примере мы будем использовать простую модель ETS(A,A,N) с аддитивной ошибкой и аддитивным трендом. Как это водится в данных M3, для проверочной выборки мы будем использовать последние 18 наблюдений.
Начнём с модели, оценённой путём минимизации MSE.
- MSE.
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T)
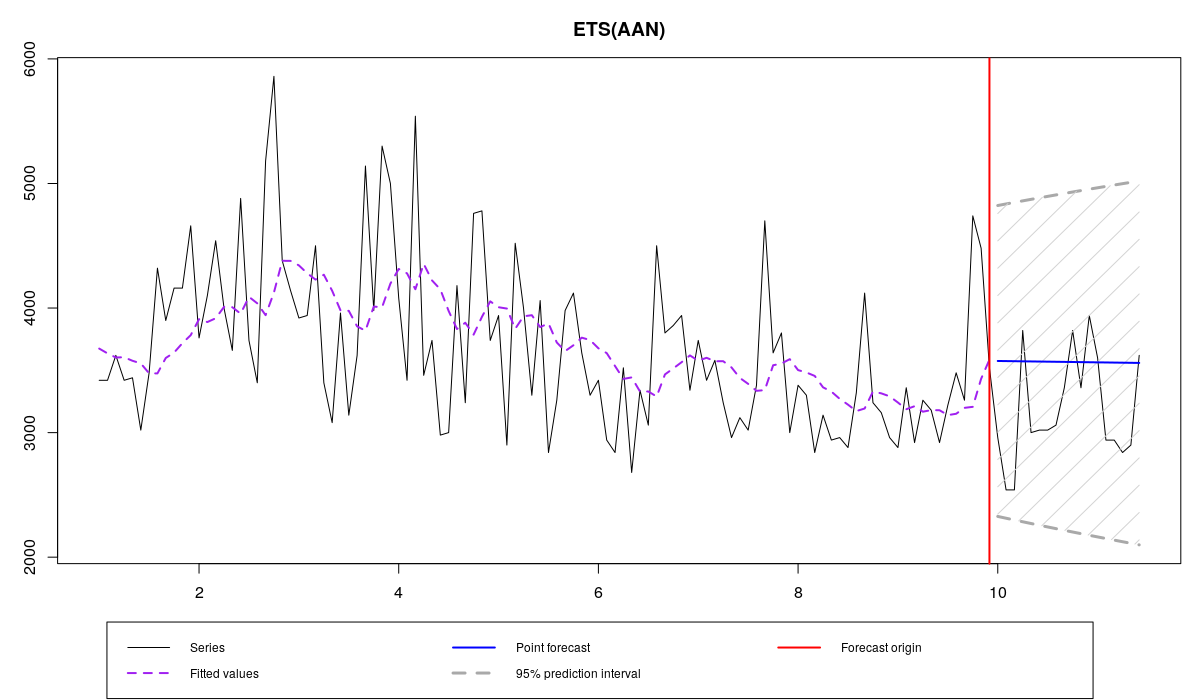
N1823 и модель ETS(A,A,N) с MSE
Вот информация о полученной модели:
Time elapsed: 0.08 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0.147 0.000
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 629.249
Cost function type: MSE; Cost function value: 377623.069
Information criteria:
AIC AICc BIC
1703.389 1703.977 1716.800
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -14%; Bias: -74.1%; MAPE: 16.8%; SMAPE: 15.1%
MASE: 0.855; sMAE: 13.4%; RelMAE: 1.047; sMSE: 2.4%
Тут сложно прийти к каким-нибудь конкретным заключениям, но, судя по всему, в прогнозе наблюдается небольшое систематическое завышение (это показывает MPE). При этом относительная MAE (RelMAE) оказалась больше единицы, что говорит о том, что метод Naive лучше справляется с задачей прогнозирования этого ряда, чем ETS(A,A,N). Посмотрим на остатки модели:
qqnorm(resid(ourModel)) qqline(resid(ourModel))
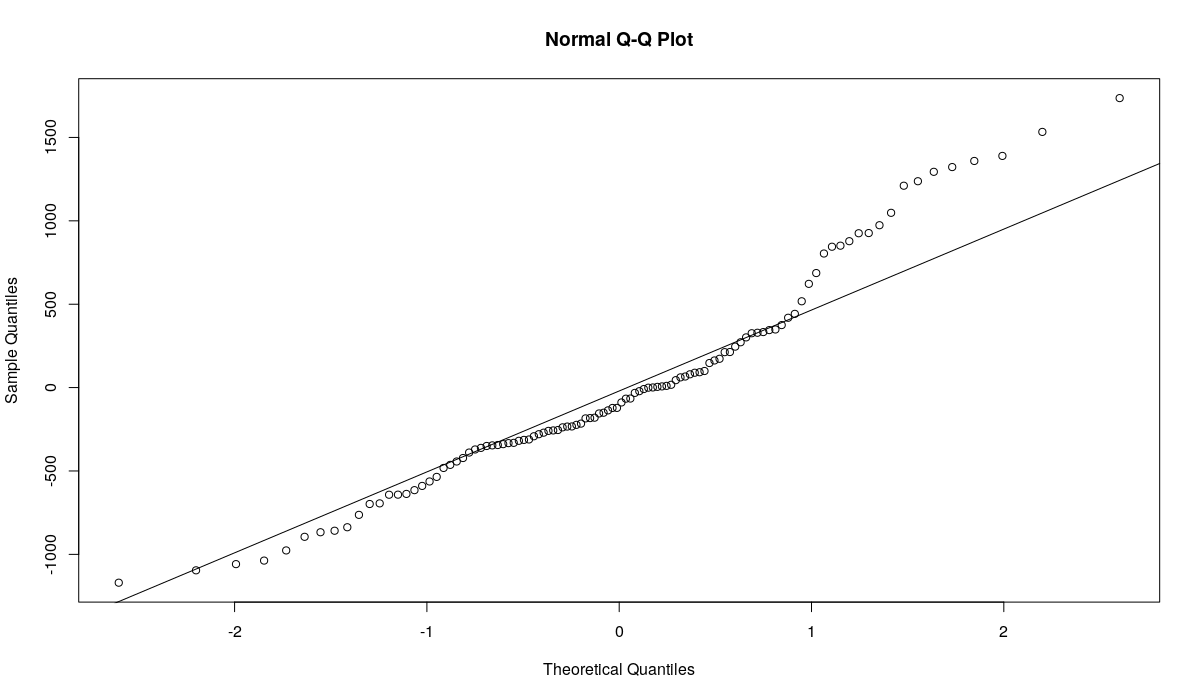
График Квантиль-квантиль по остаткам модели ETS(A,A,N), оценённой MSE
Остатки выглядят ненормально - много эмпирических квантилей оказались расположены далеко от теоретических значений. Тест на нормальность Шапиро-Уилка отвергает гипотезу о нормальности распределения остатков на 5% уровне:
shapiro.test(resid(ourModel)) > p-value = 0.001223
Это может указывать на то, что другие методы оценки могут справиться с оценкой параметров лучше. И в функциях пакета smooth есть специальный волшебный параметра для этого - loss. Попробуем оценить ту же модель с помощью других методов.
- MAE.
Минимум MAE находится с помощью команды:
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T,loss="MAE")
и даёт следующие результаты:
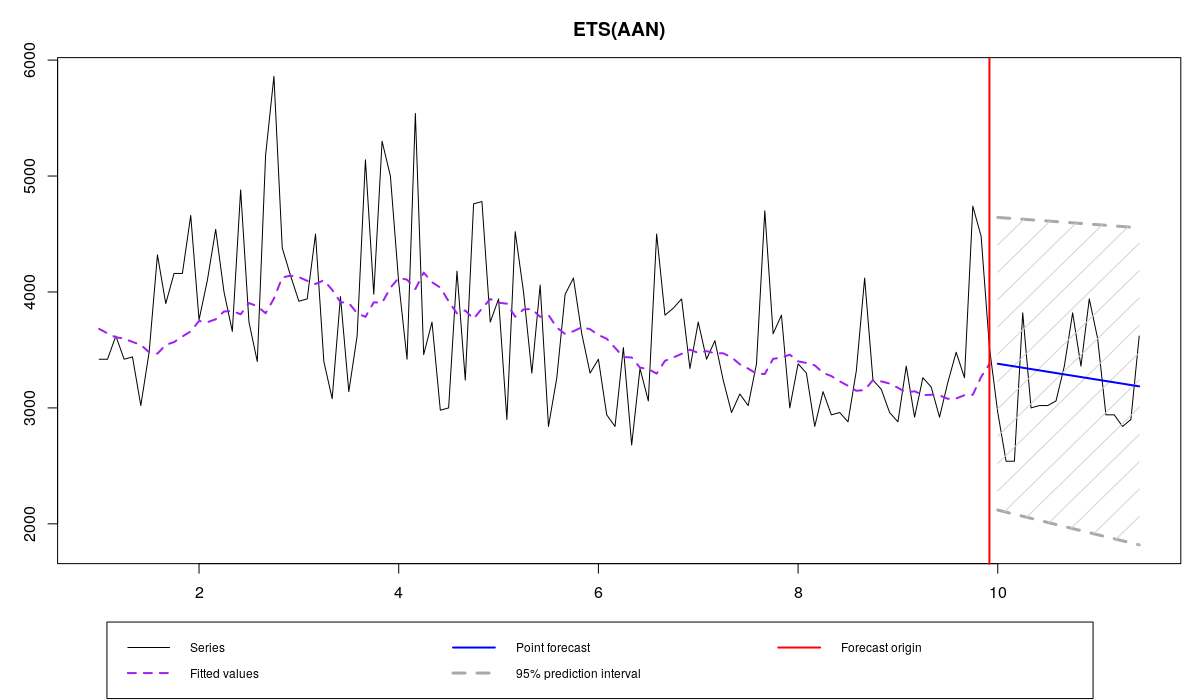
N1823 и ETS(A,A,N), оценённой с помощью MAE
Time elapsed: 0.09 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0.101 0.000
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 636.546
Cost function type: MAE; Cost function value: 462.675
Information criteria:
AIC AICc BIC
1705.879 1706.468 1719.290
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -5.1%; Bias: -32.1%; MAPE: 12.9%; SMAPE: 12.4%
MASE: 0.688; sMAE: 10.7%; RelMAE: 0.842; sMSE: 1.5%
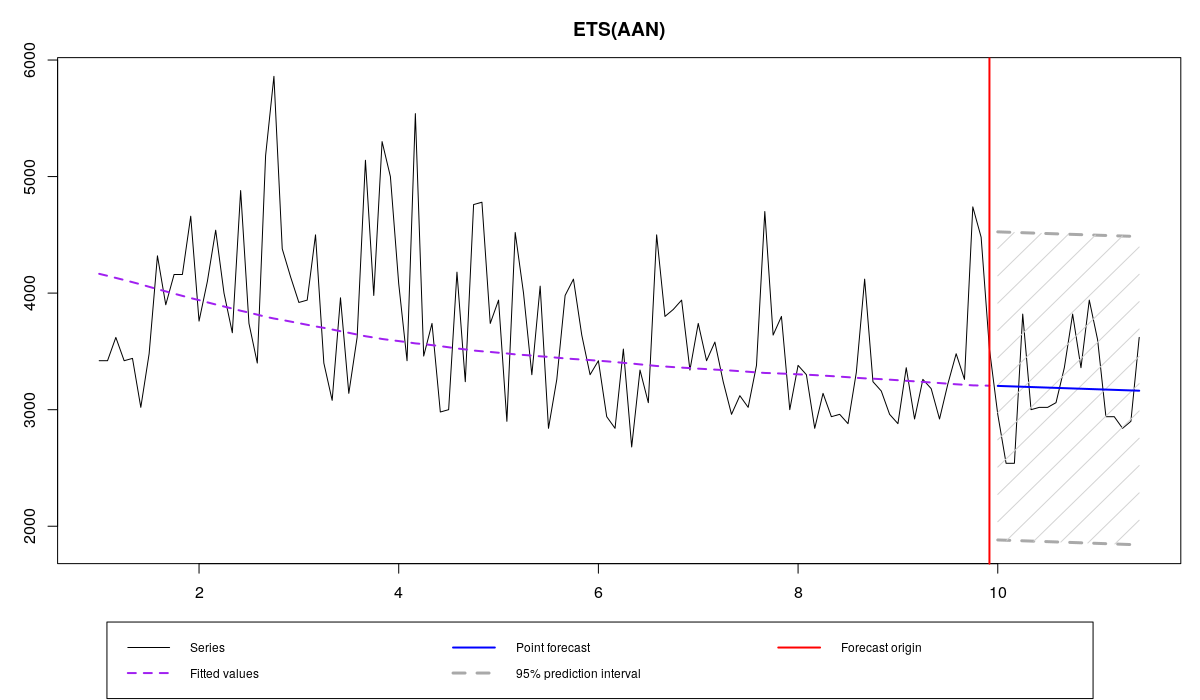
Что же получилось? Во-первых, постоянная сглаживания альфа оказалась меньше, чем в предыдущей модели, что говорит о том, что полученная модель менее чувствительна к выбросам и более консервативна. Во-вторых, RelMAE оказалась меньше нуля, что говорит о том, что данная модель лучше справляется с прогнозированием, чем Naive и чем предыдущая. Это, возможно, как раз вызвано робастностью данного метода оценки. В-третьих, по графику видно, что полученный прогноз проходит где-то между наблюдениями в проверочной выборке, что является желаемым поведением прогнозной модели. Остатки всё ещё распределены ненормально, но это вполне ожидаемо, так как другой метод оценки не делает их нормальными, а просто позволяет получить значения, менее чувствительные к выбросам:
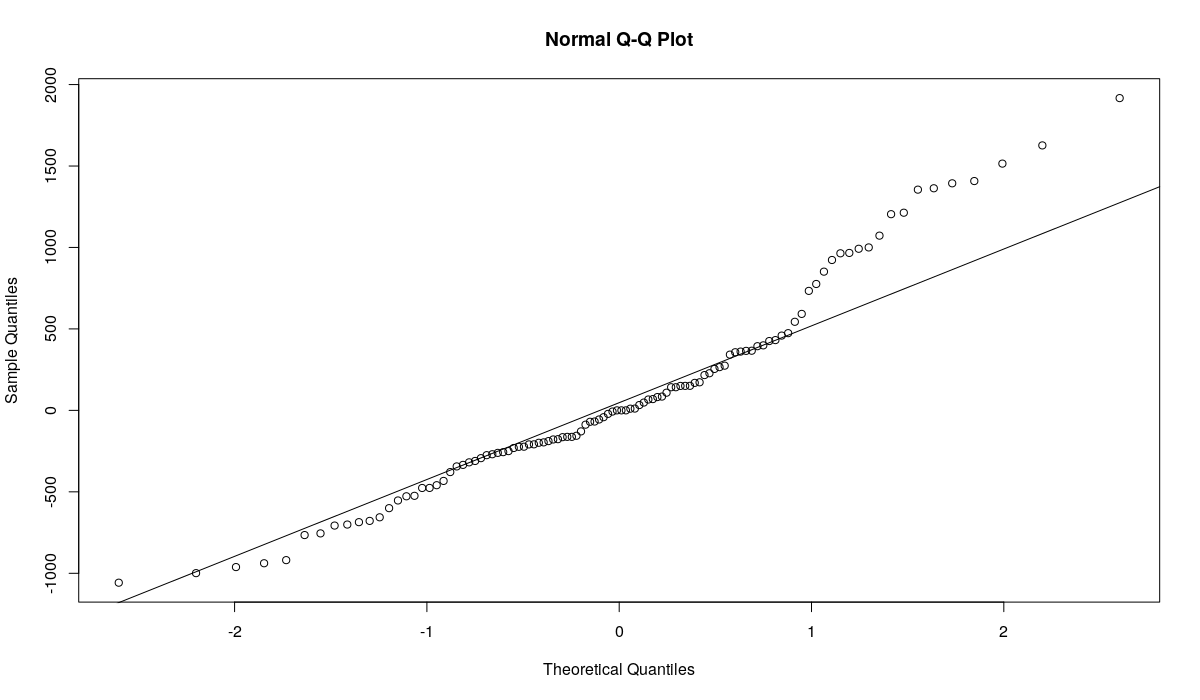
График Квантиль-квантиль по остаткам модели ETS(A,A,N), оценённой MAE
- HAM – Half Absolute Moment.
Здесь стоит немного остановиться, так как этот метод оценки мы ещё не рассматривали в учебнике. Формула его выглядит так:
\begin{equation} \label{eq:HAM}
\text{HAM} = \frac{1}{T} \sum_{t=1}^T \sqrt{|e_{t+1}|}
\end{equation}
Особенность данного метода оценки заключается в том, что масштаб ошибок уменьшается за счёт взятия корня. В результате этого модель, оценённая HAM оказывается ещё более устойчивой к выбросам, чем MAE. Более того, для модели становятся важны более мелкие и часто встречающиеся отклонения, нежели крупные и редкие. Минимум этой функции на целочисленных данных соответствует моде. В случае с непрерывными - чему-то между модой и медианой. На эту тему я с коллегами сейчас провожу исследование. Этот метод оценки даёт состоятельные, но менее эффективные оценки параметров, чем MSE и MAE.
Посмотрим, что получится:
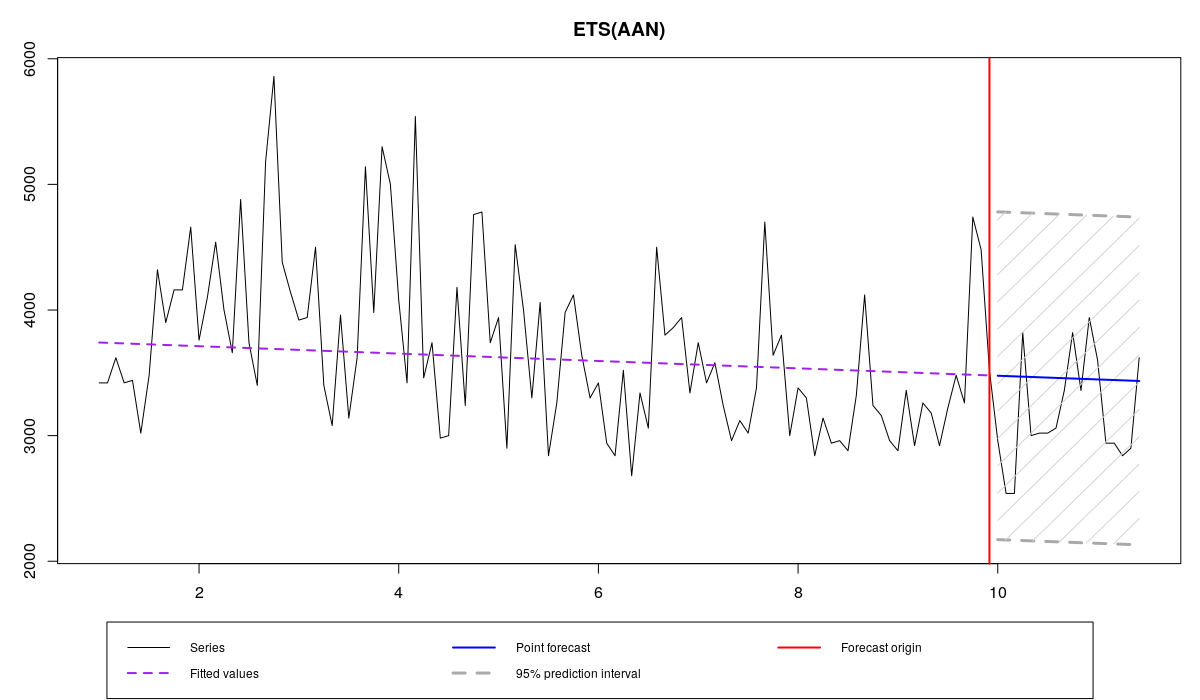
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T,loss="HAM")
N1823 и ETS(A,A,N) с HAM
Time elapsed: 0.06 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0.001 0.001
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 666.439
Cost function type: HAM; Cost function value: 19.67
Information criteria:
AIC AICc BIC
1715.792 1716.381 1729.203
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -1.7%; Bias: -14.1%; MAPE: 11.4%; SMAPE: 11.4%
MASE: 0.63; sMAE: 9.8%; RelMAE: 0.772; sMSE: 1.3%
Судя по прогнозным ошибкам и графику, эта модель дала ещё более точные прогнозы, чем модель, оценённая с помощью MAE. Правда сделала она это приблизив обе постоянные сглаживания к нулю. Обратите внимание, что стандартное отклонение в этом случае оказалось выше, чем в случае с MAE, которое в свою очередь выше, чем MSE. Это означает, что одношаговые прогнозные интервалы будут шире у HAM, чем у MAE, чем у MSE. Однако, учитывая величину постоянных сглаживания в нашем примере, многошаговые интервалы у модель с HAM, скорее всего, будут уже остальных.
Кроме того, стоит заметить, что оптимизация моделей с использованием разных методов оценки происходит с разной скоростью. MSE - самый медленный метод оценки, в то время как HAM - самый быстрый. Вызвано это формой математической функции (в случае с MSE - парабола, с MAE - линейная, с HAM - корень) и тем, как работают эвристические методы оптимизации. Разница в скорости может быть существенной, особенно, если вы работаете с большими выборками. Так что, если вы спешите, а какие-нибудь оценки нужно получить быстро, попробуйте HAM. Только не забывайте, что информационные критерии в этом случае могут давать неточные результаты.
Методы оценки на основе многошаговых прогнозов
Следующие три метода используют идею, рассмотренную нами в главе "Продвинутые методы оценки параметров». Эти методы дают состоятельные, но не эффективны, а зачастую ещё и смещённые оценки параметров. Возникает вопрос, зачем ими тогда пользоваться? А всё дело в том, что эти методы "сжимают" параметры моделей, делая сами модели более "консервативными", ближе к детерминистическим и минимизируя влияние шумов на прогноз. Это оказывается особенно полезно в случаях с высокочастотными данными, когда асимптотические свойства начинают работать, а эффективность оценок растёт.
- MSE\(_h\) - Mean Squared Error для прогноза на h шагов вперёд:
Посмотрим, что получится, если использовать его для оценки нашей модели:
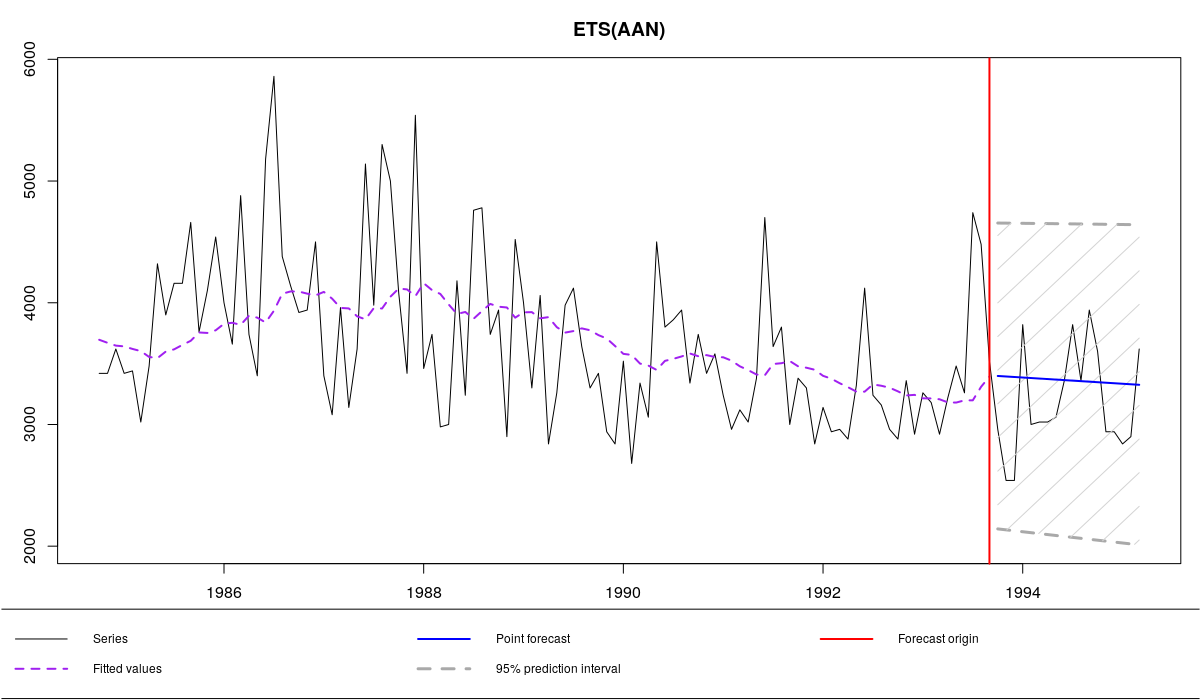
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T,loss="MSEh")
N1823 и ETS(A,A,N) с MSEh
Time elapsed: 0.24 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0 0
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 657.781
Cost function type: MSEh; Cost function value: 550179.34
Information criteria:
AIC AICc BIC
30393.86 30404.45 30635.25
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -10.4%; Bias: -62%; MAPE: 14.9%; SMAPE: 13.8%
MASE: 0.772; sMAE: 12.1%; RelMAE: 0.945; sMSE: 1.8%
Как видим, обе постоянные сглаживания оказались равными нулю, в результате чего мы получили прямую линию, проходящую через все наблюдения. Если бы в нашем распоряжении было 1008, а не 108 наблюдений, тогда параметры были бы отличны от нуля, так как модель вынуждена была бы адаптироваться к изменениям в данных. Но мы получили, что получили...
- TMSE – Trace Mean Squared Error:
Опять же, на наших данных:
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T,loss="TMSE")
N1823 and ETS(A,N,N) with TMSE
Time elapsed: 0.2 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0.075 0.000
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 633.48
Cost function type: TMSE; Cost function value: 7477097.717
Information criteria:
AIC AICc BIC
30394.36 30404.94 30635.75
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -7.5%; Bias: -48.9%; MAPE: 13.4%; SMAPE: 12.6%
MASE: 0.704; sMAE: 11%; RelMAE: 0.862; sMSE: 1.5%
Сравнивая эту модель с моделью с MSE и MSE\(_h\), можно заметить, что в случае с TMSE постоянная сглаживания для уровня ряда лежит где-то между постоянными сглаживания предыдущих моделей. Это демонстрирует тот самый, эффект, который мы обсуждали в учебнике: многошаговые прогнозы тянут параметры к нулю, в то время как одношаговые их немного поднимают вверх. Тем не менее, я бы рекомендовал использовать TMSE на больших выборках, где оценки параметров становятся более эффективными и менее смещёнными.
- GTMSE – Geometric Trace Mean Squared Error:
Этот метод оценки мы тоже уже обсуждали в учебнике.
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T,loss="GTMSE")
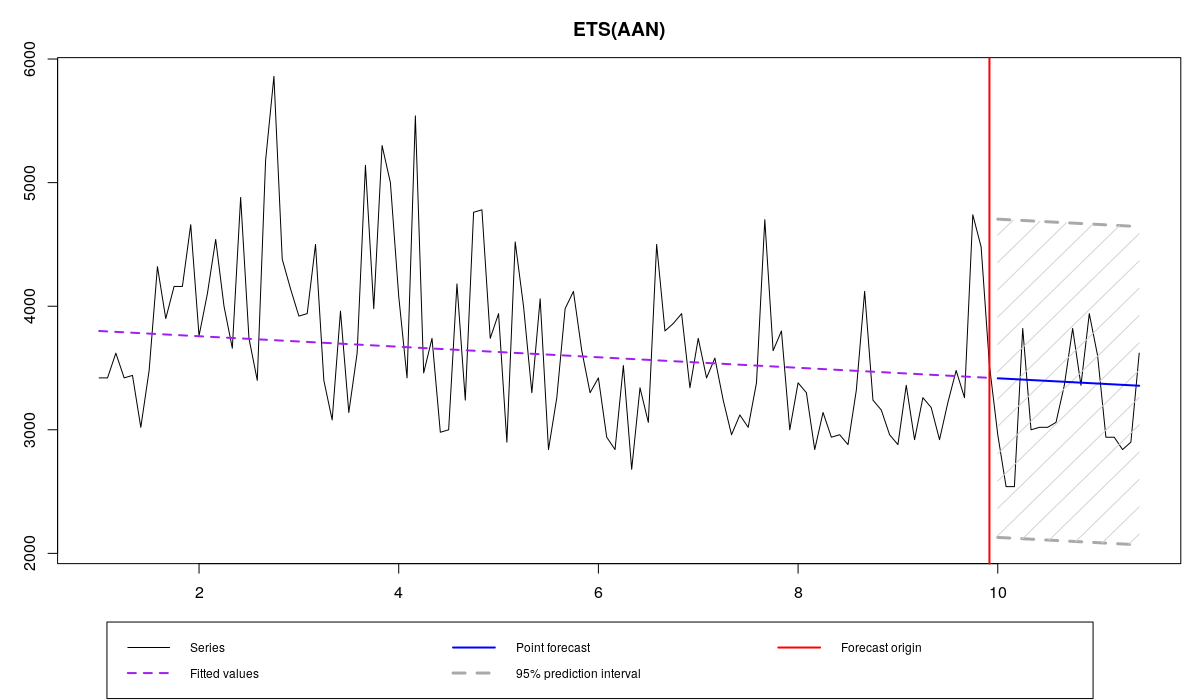
N1823 and ETS(A,A,N) with GTMSE
Time elapsed: 0.18 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0 0
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 649.253
Cost function type: GTMSE; Cost function value: 232.419
Information criteria:
AIC AICc BIC
30402.77 30413.36 30644.16
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -8.2%; Bias: -53.8%; MAPE: 13.8%; SMAPE: 12.9%
MASE: 0.72; sMAE: 11.3%; RelMAE: 0.882; sMSE: 1.6%
В нашем примере этот метод оценки также сжал параметры к нулю, сделав модель детерминистической, что соответствует результатам, полученным с помощью MSE\(_h\). Однако, стартовые значения у методы получились немного другими, что привело к другим прогнозам.
Имейте в виду, что все эти методы оценки значительно более требовательны к расчётном времени, потому что для каждого из них нужно сделать прогноз на h шагов вперёд из каждого наблюдения в обучающей выборке.
- Аналитические многошаговые методы оценки.
В функциях пакета smooth есть ещё одна полезная, незадокументированная функция (доступная пока только для чистых аддитивных моделей) – использование аналитических аналогов многошаговых методов оценки. Вызываются такие методы путём добавления буквы "a" перед названием желаемого метода оценки: aMSEh, aTMSE, aGTMSE. В этом случае одношаговые ошибки и параметры модели будут использоваться для реконструирования многошаговых методов оценки. Эта опция полезна в том случае, когда вам нужно использовать какой-то метод оценки на малых выборках. Также эти методы могут быть полезны, если вы работаете с большими выборками, но хотите, чтобы модель была построена относительно быстро.
Эти методы оценки имеют свойства схожие со свойствами их эмпирических аналогов, но работают быстрее и используют асимптотические свойства.
Вот пример использования аналитичекого MSE\(_h\):
ourModel <- es(x,"AAN",silent=F,interval="p",h=18,holdout=T,cfType="aMSEh")
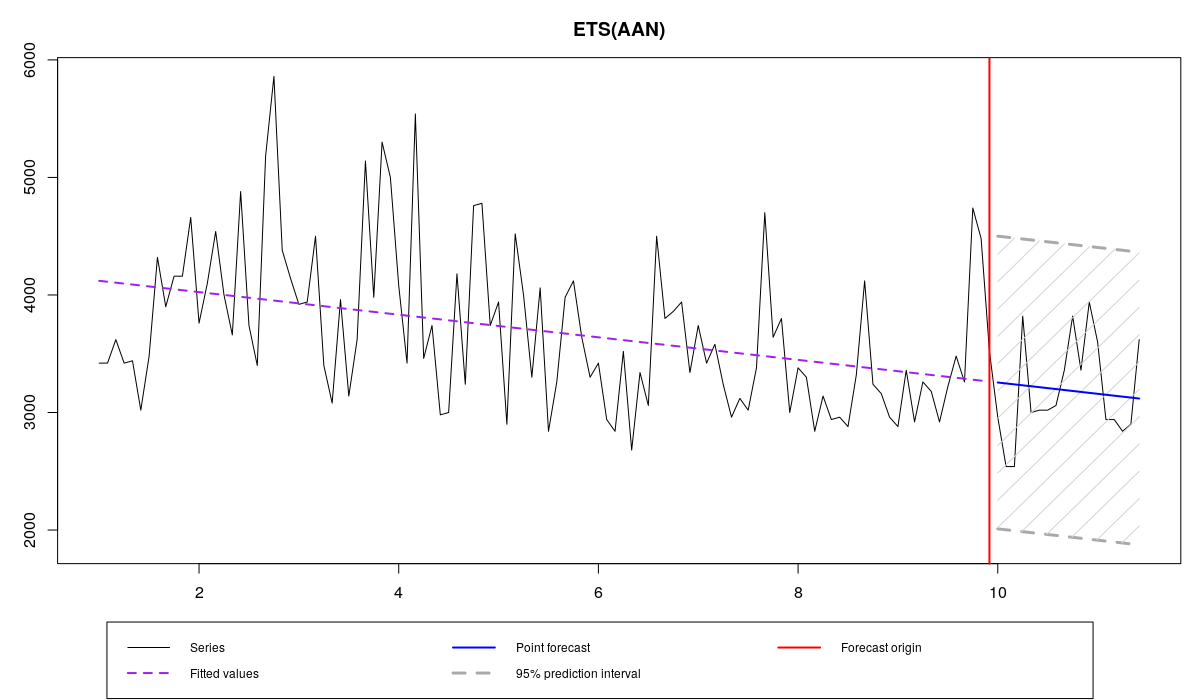
N1823 и ETS(A,A,N) с aMSEh
Time elapsed: 0.11 seconds
Model estimated: ETS(AAN)
Persistence vector g:
alpha beta
0 0
Initial values were optimised.
5 parameters were estimated in the process
Residuals standard deviation: 627.818
Cost function type: aMSEh; Cost function value: 375907.976
Information criteria:
AIC AICc BIC
30652.15 30662.74 30893.55
95% parametric prediction intervals were constructed
100% of values are in the prediction interval
Forecast errors:
MPE: -1.9%; Bias: -14.6%; MAPE: 11.7%; SMAPE: 11.6%
MASE: 0.643; sMAE: 10%; RelMAE: 0.787; sMSE: 1.3%
Итоговые постоянные сглаживания получились равными нулю, аналогично тому, что мы наблюдали в MSE\(_h\). Стартовые значения модели при этом получились немного другие, поэтому и прогноз оказался другим (по сравнению с MSE\(_h\)). На себя так же обращает внимание то, что модель была оценена и сконструирована за 0.11 секунд, а не за 0.24, как в случае с MSE\(_h\).
- Аналогично тому, как это было с MSE, в функциях smooth реализованы и многошаговые MAE и HAM (типа MAE\(_h\) и THAM). Правда, они там просто потому что я смог их сделать, а не потому что они имеют какой-то особый смысл. К их изучению я ещё даже не думал приступать.
Заключение
Теперь, когда мы обсудили все возможные методы оценки функций пакета smooth, у вас может возникнуть закономерный вопрос: "Что же использовать?". Честно говоря, у меня пока нет однозначного ответа на этот вопрос, так как это направление ещё не до конца изучено. Но у меня есть некоторые советы, которые хотелось бы здесь привести:
Во-первых, Никос Курентзес и Хуан Рамон Траперо выяснили, что в случае с высокочастотными данными использование MSE\(_h\) и TMSE приводит к увеличению точности прогнозов по сравнению с MSE. Однако, если в случае с MSE\(_h\) для этого нужно построить h моделей, TMSE позволяет построить одну, что в разы уменьшает время расчётов. Точность прогнозов при использовании TMSE и MSE\(_h\) оказывается сопостовимой.
Во-вторых, если вы сталкиваетесь с асимметричным распределением остатков при оценке с помощью MSE, попробуйте использовать MAE и HAM – они могут улучшить прогнозную точность моделей.
В-третьих, аналитические версии многошаговых методов я бы рекомендовал использовать на больших выборках, когда скорость вычислений важна, а свойства этих методов хочется использовать. Ну, или в ситуации, когда выборка наоборот маленькая, а свойства хочется использовать (эмпирические значения получить в этом случае затруднительно).
Наконец, не стоит спользовать MSE\(_h\), TMSE и GTMSE если вас интересуют параметры моделей (а не точность прогнозов) – они скорее всего будут неэффективными и смещёнными. Это применимо как к ETS, так и к ARIMA, которые в этом случае становятся близкими к детерминистическим моделям. Используйте MSE и не выпендривайтесь!