



If you are interested in forecasting, you might have heard of M-competitions. They played a pivotal role in developing forecasting principles, yet also sparked controversy. In this short post, I’ll briefly explain their historical significance and discuss their main findings.
Before M-competitions, only few papers properly evaluated forecasting approaches. Statisticians assumed that if a model had solid theoretical backing, it should perform well. One of the first papers to conduct a proper evaluation was Newbold & Granger (1974), who compared exponential smoothing (ES), ARIMA, and stepwise AR on 106 economic time series. Their conclusions were:
1. ES performed well on short time series;
2. Stepwise AR did well on the series with more than 30 observations;
3. Box-Jenkins methodology was recommended for series longer than 50 observations.
Statistical community received the results favourably, as they aligned with their expectations.
In 1979, Makridakis & Hibon conducted a similar analysis on 111 time series, including various ES methods and ARIMA. However, they found that “simpler methods perform well in comparison to the more complex and statistically sophisticated ARMA models”. This is because ARIMA performed slightly worse than ES, which contradicted the findings of Newbold & Granger. Furthermore, their paper faced heavy criticism, with some claiming that Makridakis did not correctly utilize Box-Jenkins methodology.
So, in 1982, Makridakis et al. organized a competition on 1001 time series, inviting external participants to submit their forecasts. It was won by… the ARARMA model by Emmanuel Parzen. This model used information criteria for ARMA order selection instead of Box-Jenkins methodology. The main conclusion drawn from this competition was that “Statistically sophisticated or complex methods do not necessarily provide more accurate forecasts than simpler ones.” Note that this does not mean that simple methods are always better, because that was not even the case in the first competition: it was won by a quite complicated statistical model based on ARMA. This only means that the complexity does not necessarily translate into accuracy.
The M2 competition focused on judgmental forecasting, and is not discussed here.
We then arrive to M3 competition with 3003 time series and, once again, open submission for anyone. The results widely confirmed the previous findings, with Theta by Vasilious Assimakopoulos and Kostas Nikolopoulos outperforming all the other methods. Note that ARIMA with order selection based on Box-Jenkins methodology performed fine, but could not beat its competitors.
Finally, we arrive to M4 competition, which had 100,000 time series and was open to even wider audience. While I have my reservations about the competition itself, there were several curious findings, including the fact that ARIMA implemented by Hyndman & Khandakar (2008) performed on average better than ETS (Theta outperformed both of them), and that the more complex methods won the competition.
It was also the first paper to show that the accuracy tends to increase on average with the increase of the computational time spent for training. This means that if you want to have more accurate forecasts, you need to spend more resources. The only catch is that this happens with the decreasing return effect. So, the improvements become smaller and smaller the more time you spend on training.
The competition was followed by M5 and M6, and now they plan to have another one. I don’t want to discuss all of them – they are beyond the scope of this short post (see details on the website of the competitions). But I personally find the first competitions very impactful and useful.
And here are my personal takeaways from these competitions:
1. Simple forecasting methods perform well and should be included as benchmarks in experiments;
2. Complex methods can outperform simple ones, especially if used intelligently, but you might need to spend more resources to gain in accuracy;
3. ARIMA is effective, but Box-Jenkins methodology may not be practical. Using information criteria for order selection is a better approach (as evidenced from ARARMA example and Hydnman & Khandakar implementation).
Finally, I like the following quote from Rob J. Hyndman about the competitions that gives some additional perspective: “The “M” competitions organized by Spyros Makridakis have had an enormous influence on the field of forecasting. They focused attention on what models produced good forecasts, rather than on the mathematical properties of those models”.
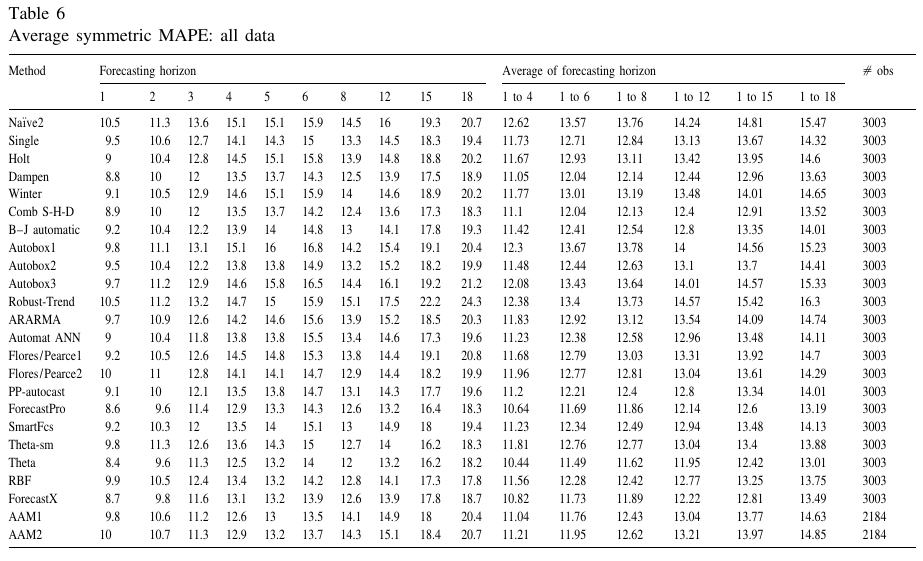
Table with the results of the M3 competition