



The ISF2019 took place in Thessaloniki, Greece. This time I presented a spin-off of my research on intermittent demand in retail, entitled as “What about those sweet melons? Using mixture models for demand forecasting in retail”. The idea is quite trivial and simple: use mixture distribution regressions (e.g. logistic and log-normal distributions) in order to predict the seasonally-intermittent sales in retail. The model is quite simple and easy to implement in practice. The main problem that I’ve faced so far is the absence of the proper data. I only had 24 series of weekly sales of tomatoes provided by a small company, but I need more in order to see, which of the approaches works best. For this research, I need the data like this:
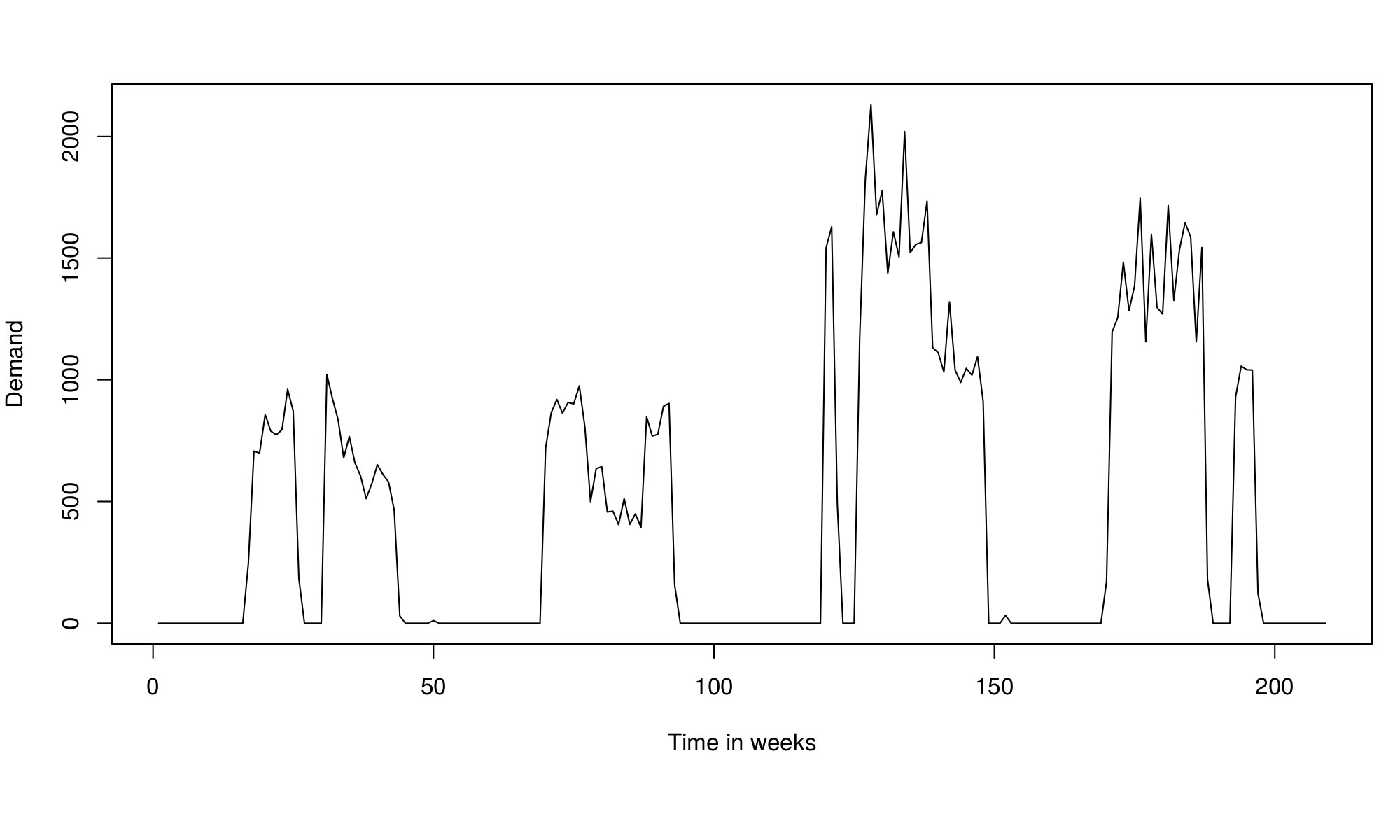
Retail sales of tomatoes
Anyway, here are the slides if anyone wants to have a look.
On slide 27 you used the AvgRelMSE measure proposed in this Ph.D. thesis (p. 63):
https://www.researchgate.net/publication/338885739_Integration_of_judgmental_and_statistical_approaches_for_demand_forecasting_Models_and_methods
If you are using this evaluation, scheme, I think you need to make proper references. It’s always nice to make acknowledgements of other people’s work if you use it in your presentation.
Dear Andrey Davydenko,
Thank you for the reference! I was not aware of this.
However, please, notice that I use relative RMSE, not relative MSE and I don’t use geometric means for the aggregation. So this is a different error measure than the one you have proposed. I’m not claiming that I have invented something new here – anyone can come up with similar measures.
Kind regards,
Ivan Svetunkov
Thank you for your reply.
Is it right that you used the arithmetic mean to average performances across series (slides 27, 31, and 37)?
The problem is that you wrote you recommend the geometric mean (however, without noting that the geometric mean for relative performances is used in the scheme proposed in Davydenko and Fildes, 2013).
I saw this phrase “As mentioned in the previous post, if you want to aggregate the relative error measures, it makes sense to use geometric means instead of arithmetic ones.” in this post
https://openforecast.org/en/2019/08/25/are-you-sure-youre-precise-measuring-accuracy-of-point-forecasts/
Your slide did not contain any indication of type of the mean that was used.
If you use the arithmetic mean (or the median) then this can potentially lead to biased estimates, as described in (Davydenko and Fildes, 2013, p. 517):
https://www.researchgate.net/publication/257026708_Measuring_Forecasting_Accuracy_The_Case_Of_Judgmental_Adjustments_To_Sku-Level_Demand_Forecasts
“As a result of using the arithmetic mean of MAE ratios, introduces a bias towards overrating the accuracy of a benchmark forecasting method. In other words, the penalty for bad forecasting becomes larger than the reward for good forecasting. … For example, suppose that the performance of some forecasting method is compared with the performance of the naive method across two series (m = 2) which contain equal numbers of forecasts and observations. For the first series, the MAE ratio is r1 = 1/2, and for the
second series, the MAE ratio is the opposite: r2 = 2/1. The improvement in accuracy for the first series obtained using the forecasting method is the same as the reduction for the second series. However, averaging the ratios gives MASE = 1/2(r1 + r2) = 1.25, which indicates that the benchmark method is better. While this is a well-known point, its implications for error measures, with the potential for misleading conclusions, are widely ignored.”
The same example can be found in this Ph.D. thesis (Davydenko, 2012) on page 60:
https://www.researchgate.net/publication/338885739_Integration_of_judgmental_and_statistical_approaches_for_demand_forecasting_Models_and_methods
If you use the arithmetic mean, you, of course, there’s no need to cite any additional works.
But if you use the geometric mean for relative performances (as you are doing in your latest posts), you need to cite the original work (either (Davydenko, 2012) or (Davydenko and Fildes, 2013)). Otherwise you will be using a method proposed by another person without giving proper references to the original work. Let me note that the use of others’ works including ideas and findings without giving proper references is plagiarism and it is against scientific ethics.
References:
Davydenko, A. (2012). Integration of judgmental and statistical approaches for demand forecasting: Models and methods (doctoral dissertation). Lancaster University, UK.
https://www.researchgate.net/publication/338885739_Integration_of_judgmental_and_statistical_approaches_for_demand_forecasting_Models_and_methods
Andrey Davydenko, Robert Fildes, Measuring forecasting accuracy: The case of judgmental adjustments to SKU-level demand forecasts, International Journal of Forecasting, Volume 29, Issue 3, 2013, Pages 510-522,
https://www.researchgate.net/publication/257026708_Measuring_Forecasting_Accuracy_The_Case_Of_Judgmental_Adjustments_To_Sku-Level_Demand_Forecasts
Dear Andrey,
First of all, yes I have used arithmetic means and not geometric ones. I am quite aware of your research and your papers, I have read those resources several times. The reason for using arithmetic ones is because we always deal with a distribution of measures, no matter what measure we use. So I was interested in looking at specific statistics of distributions. I understand your idea of using geometric means for relative values, but you might also know that using geometric means in cases of distributions that are symmetric in logarithms is equivalent to taking medians. So it does not give any additional useful information. As a result I have decided to use arithmetic one instead of the geometric one. In fact, if the distribution is well behaved, then arithmetic mean will be close to both the geometric one and to the median, and in the opposite case the arithmetic mean will be much lower than the median. This gives you an additional information about the distribution of error measures and the performance of forecasting methods.
Second, I am quite aware of the bias issue, but I am more interested in comparing distributions of measures instead of looking just at one number. So I don’t find the usage of geometric mean in this context useful anymore.
Third, if you blame me for being unethical, you should accuse yourself of being unethical as well. Have you invented the geometric means? I am pretty sure that you haven’t. But still, you have never ever referred to the author who first came up with the idea of geometric means in your paper. Yet you claim everywhere that using geometric means in this context is your invention. So, according to your criteria, you have stolen someone else’s idea. Furthermore, have you invented boxplots? No. But you have never referred to the person who proposed them, when you used them in your paper. And do you also claim that by using boxplots of the logarithms of relative measures you have invented something new? If you want to be consistent in your claims, then you should accuse of plagiarism all the people who do similar plots and do not refer to Davydenko & Fildes (2013) paper. If you don’t do that then you should have referred in your paper to the first person who proposed to use boxplots of the logarithms of relative measures. As you might notice, if we start looking into these details, your ethics can also be questioned in the same way you question mine. Don’t you see an issue here?
Fourth, I refer to your paper every time I discuss geometric mean relative MAE or RMSE (although formally you have not proposed the latter). I will not refer to the paper every time I mention the measures in the same post or in the same presentation. One time per post / presentation is enough. In fact, people already know that this is a measure proposed by Davydenko & Fildes (2013), and you don’t need to show them the reference every time the words “geometric mean relative MAE” come up. Furthermore, whenever I discuss the measures I refer to the previous posts that contain the necessary references, so it is actually not necessary to refer to your paper in every post (but I still do).
Finally, you have made the idea of using geometric mean for relative measures toxic, by accusing other people of plagiarism, without any reasonable grounds for this. While I have no intention of stealing your work and have never ever claimed that I came up with the idea, you have bullied me about this continuously, despite the number of references to your paper I have made over the years. So, from now on I will try avoiding this measure as formulated in your paper, so that I don’t need to deal with you and your wild accusations.
Have a nice day,
Ivan
Ivan, thank you for your reply, explanations, and also for your questions. I’ll try to answer them.
1) “Have you invented the geometric means?”
No, I have not invented the geometric mean. But I invested a lot of time and efforts into the development of the error measure that has the improved statistical features compared to the alternatives. And I developed the measure that at present has the best features compared to what had been proposed before. I described the advantages of using the geometric mean for averaging relative performances across time series. Of course, I tried to cite the works that were relevant to the use of the geometric mean. This was one of the contributions of my Ph.D. thesis (I cited the works that I thought were related to the use of the geometric mean).
I think that this was a sufficient contribution for making proper references.
A small remark about the history of this measure. It is funny that when I first presented the general metric that averages performances across series (it was in the year 2010, see the link below), it received a heavy criticism from some members of Lancaster University because they thought the measure was uninterpretable. So I spent a lot of efforts in order to defend this scheme and to explain its advantages. Now, when the advantages of this approach are well understood, it is often used without making any references to the original work, that’s why I am trying to prevent such cases in future.
I have the right to protect my intellectual property and I will be doing so.
Link to the poster:
https://www.researchgate.net/publication/338884013_How_to_measure_the_quality_of_demand_forecasts_efficiently_A_new_class_of_forecasting_performance_metrics
2) “Have you invented boxplots?”
No, I have not. But I used boxplots to explore the behavior of log-transformed relative performances. If you know any publication where it was done before my works, please let me know. I tried to find similar analyses, but I only found the following publication:
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0174202
On Fig. 7 the authors show the Box-and-whisker plot of log(RelMAE). And yes, they do explicitly make a reference when referring to the he box-and-whisker plots: “To show the error distributions in a similar manner to that in [24], we use the errors produced by the forecasting method ForecastPro as an example. “. [24] is (Davydenko and Fildes, 2013).
So, this paper, “A new accuracy measure based on bounded relative error for time series forecasting” by C. Chen, J. Twycross, M. Garibaldi is an example of how you can reference others’ work correctly (see the description of Fig. 7). It is an example of how your respect others’ work.
I hope my explanations will help. The purpose of my work and my publication was the development of new methods that could be used by other researchers. So I also hope you will still be able to use the measures as they were originally formulated.