



Authors: Ivan Svetunkov, Nikos Kourentzes, Rebecca Killick
Journal: Computational Statistics
Abstract: Many modern statistical models are used for both insight and prediction when applied to data. When models are used for prediction one should optimise parameters through a prediction error loss function. Estimation methods based on multiple steps ahead forecast errors have been shown to lead to more robust and less biased estimates of parameters. However, a plausible explanation of why this is the case is lacking. In this paper, we provide this explanation, showing that the main benefit of these estimators is in a shrinkage effect, happening in univariate models naturally. However, this can introduce a series of limitations, due to overly aggressive shrinkage. We discuss the predictive likelihoods related to the multistep estimators and demonstrate what their usage implies to time series models. To overcome the limitations of the existing multiple steps estimators, we propose the Geometric Trace Mean Squared Error, demonstrating its advantages. We conduct a simulation experiment showing how the estimators behave with different sample sizes and forecast horizons. Finally, we carry out an empirical evaluation on real data, demonstrating the performance and advantages of the estimators. Given that the underlying process to be modelled is often unknown, we conclude that the shrinkage achieved by the GTMSE is a competitive alternative to conventional ones.
DOI: 10.1007/s00180-023-01377-x.
About the paper
DISCLAIMER 1: To better understand what I am talking about in this section, I would recommend you to have a look at the ADAM monograph, and specifically at the Chapter 11. In fact, Section 11.3 is based on this paper.
DISCLAIMER 2: All the discussions in the paper only apply to pure additive models. If you are interested in multiplicative or mixed ETS models, you’ll have to wait another seven years for another paper on this topic to get written and published.
Introduction
There are lots of ways how dynamic models can be estimated. Some analysts prefer likelihood, some would stick with Least Squares (i.e. minimising MSE), while others would use advanced estimators like Huber’s loss or M-estimators. And sometimes, statisticians or machine learning experts would use multiple steps ahead estimators. For example, they would use a so-called “direct forecast” by fitting a model to the data, producing h-steps ahead in-sample point forecasts from the very first to the very last observation, then calculating the respective h-steps ahead forecast errors and (based on them) Mean Squared Error. Mathematically, this can be written as:
\begin{equation} \label{eq:hstepsMSE}
\mathrm{MSE}_h = \frac{1}{T-h} \sum_{t=1}^{T-h} e_{t+h|t}^2 ,
\end{equation}
where \(e_{t+h|t}\) is the h-steps ahead error for the point forecast produced from the observation \(t\), and \(T\) is the sample size.
In my final year of PhD, I have decided to analyse how different multistep loss functions work, to understand what happens with dynamic models, when these losses are minimised, and how this can help in efficient model estimation. Doing the literature review, I noticed that the claims about the multistep estimators are sometimes contradictory: some authors say that they are more efficient (i.e. estimates of parameters have lower variances) than the conventional estimators, some say that they are less efficient; some claim that they improve accuracy, while the others do not find any substantial improvements. Finally, I could not find a proper explanation of what happens with the dynamic models when the estimators are used. So, I’ve started my own investigation, together with Nikos Kourentzes and Rebecca Killick (who was my internal examiner and joined our team after my graduation).
Our investigation started with the single source of error model, then led us to predictive likelihoods and, after that – to the development of a couple of non-conventional estimators. As a result, the paper grew and became less focused than initially intended. In the end, it became 42 pages long and discussed several aspects of models estimation (making it a bit of a hodgepodge):
- How multistep estimators regularise parameters of dynamic models;
- That multistep forecast errors are always correlated when the models’ parameters are not zero;
- What predictive likelihoods align with the multistep estimators (this is useful for a discussion of their statistical properties);
- How General Predictive Likelihood encompasses all popular multistep estimators;
- And that there is another estimator (namely GTMSE – Geometric Trace Mean Squared Error), which has good properties and has not been discussed in the literature before.
Because of the size of the paper and the spread of the topics throughout it, many reviewers ignored (1) – (4), focusing on (5) and thus rejecting the paper on the grounds that we propose a new estimator, but instead spend too much time discussing irrelevant topics. These types of comments were given to us by the editor of the Journal of the Royal Statistical Society: B and reviewers of Computational Statistics and Data Analysis. While we tried addressing this issue several times, given the size of the paper, we failed to fix it fully. The paper was rejected from both of these journals and ended up in Computational Statistics, where the editor gave us a chance to respond to the comments. We explained what the paper was really about and changed its focus to satisfy the reviewers, after which the paper was accepted.
So, what are the main findings of this paper?
How multistep estimators regularise parameters of dynamic models
Given that any dynamic model (such as ETS or ARIMA) can be represented in the Single Source of Error state space form, we showed that the application of multistep estimators leads to the inclusion of parameters of models in the loss function, leading to the regularisation. In ETS, this means that the smoothing parameters are shrunk to zero, with the shrinkage becoming stronger with the increase of the forecasting horizon relative to the sample size. This makes the models less stochastic and more conservative. Mathematically this becomes apparent if we express the conditional multistep variance in terms of smoothing parameters and one-step-ahead error variance. For example, for ETS(A,N,N) we have:
\begin{equation} \label{eq:hstepsMSEVariance}
\mathrm{MSE}_h \propto \hat{\sigma}_1^2 \left(1 +(h-1) \hat{\alpha} \right),
\end{equation}
where \( \hat{\alpha} \) is the smoothing parameter and \(\hat{\sigma}_1^2 \) is the one-step-ahead error variance. From the formula \eqref{eq:hstepsMSEVariance}, it becomes apparent that when we minimise MSE\(_h\), the estimated variance and the smoothing parameters will be minimised as well. This is how the shrinkage effect appears: we force \( \hat{\alpha} \) to become as close to zero as possible, and the strength of shrinkage is regulated by the forecasting horizon \( h \).
In the paper itself, we discuss this effect for several multistep estimators (the specific effect would be different between them) and several ETS and ARIMA models. While for ETS, it is easy to show how shrinkage works, for ARIMA, the situation is more complicated because the direction of shrinkage would change with the ARIMA orders. Still, what can be said clearly for any dynamic model is that the multistep estimators make them less stochastic and more conservative.
Multistep forecast errors are always correlated
This is a small finding, done in bypassing. It means that, for example, the forecast error two steps ahead is always correlated with the three steps ahead one. This does not depend on the autocorrelation of residuals or any violation of assumptions of the model but rather only on whether the parameters of the model are zero or not. This effect arises from the model rather than from the data. The only situation when the forecast errors will not be correlated is when the model is deterministic (e.g. linear trend). This has important practical implications because some forecasting techniques make explicit and unrealistic assumptions that these correlations are zero, which would impact the final forecasts.
Predictive likelihoods aligning with the multistep estimators
We showed that if a model assumes the Normal distribution, in the case of MSEh and MSCE (Mean Squared Cumulative Error), the distribution of the future values follows Normal as well. This means that there are predictive likelihood functions for these models, the maximum of which is achieved with the same set of parameters as the minimum of the multistep estimators. This has two implications:
- These multistep estimators should be consistent and efficient, especially when the smoothing parameters are close to zero;
- The predictive likelihoods can be used in the model selection via information criteria.
The first point also explains the contradiction in the literature: if the smoothing parameter in the population is close to zero, then the multistep estimators will give more efficient estimates than the conventional estimators; in the other case, it might be less efficient. We have not used the second point above, but it would be useful when the best model needs to be selected for the data, and an analyst wants to use information criteria. This is one of the potential ways for future research.
How General Predictive Likelihood (GPL) encompasses all popular multistep estimators
GPL arises when the joint distribution of 1 to h steps ahead forecast errors is considered. It will be Multivariate Normal if the model assumes normality. In the paper, we showed that the maximum of GPL coincides with the minimum of the so-called “Generalised Variance” – the determinant of the covariance matrix of forecast errors. This minimisation reduces variances for all the forecast errors (from 1 to h) and increases the covariances between them, making the multistep forecast errors look more similar. In the perfect case, when the model is correctly specified (no omitted or redundant variables, homoscedastic residuals etc), the maximum of GPL will coincide with the maximum of the conventional likelihood of the Normal distribution (see Section 11.1 of the ADAM monograph).
Accidentally, it can be shown that the existing estimators are just special cases of the GPL, but with some restrictions on the covariance matrix. I do not intend to show it here, the reader is encouraged to either read the paper or see the brief discussion in Subsection 11.3.5 of the ADAM monograph.
GTMSE – Geometric Trace Mean Squared Error
Finally, looking at the special cases of GPL, we have noticed that there is one which has not been discussed in the literature. We called it Geometric Trace Mean Squared Error (GTMSE) because of the logarithms in the formula:
\begin{equation} \label{eq:GTMSE}
\mathrm{GTMSE} = \sum_{j=1}^h \log \frac{1}{T-j} \sum_{t=1}^{T-j} e_{t+j|t}^2 .
\end{equation}
GTMSE imposes shrinkage on parameters similar to other estimators but does it more mildly because of the logarithms in the formula. In fact, what the logarithms do is make variances of all forecast errors similar to each other. As a result, when used, GTMSE does not focus on the larger variances as other methods do but minimises all of them simultaneously similarly.
Examples in R
The estimators discussed in the paper are all implemented in the functions of the smooth package in R, including adam(), es(), ssarima(), msarima() and ces(). In the example below, we will see how the shrinkage works for the ETS on the example of Box-Jenkins sales data (this is the example taken from ADAM, Subsection 11.3.7):
library(smooth)
adamETSAANBJ <- vector("list",6)
names(adamETSAANBJ) <- c("MSE","MSEh","TMSE","GTMSE","MSCE","GPL")
for(i in 1:length(adamETSAANBJ)){
adamETSAANBJ[[i]] <- adam(BJsales, "AAN", h=10, holdout=TRUE,
loss=names(adamETSAANBJ)[i])
}
The ETS(A,A,N) model, applied to this data, has different estimates of smoothing parameters:
sapply(adamETSAANBJ,"[[","persistence") |> round(5)
MSE MSEh TMSE GTMSE MSCE GPL alpha 1.00000 1 1 1.00000 1 1 beta 0.23915 0 0 0.14617 0 0
We can see how shrinkage shows itself in the case of the smoothing parameter \(\beta\), which is shrunk to zero by MSEh, TMSE, MSCE and GPL but left intact by MSE and shrunk a little bit in the case of GTMSE. These different estimates of parameters lead to different forecasting trajectories and prediction intervals, as can be shown visually:
par(mfcol=c(3,2), mar=c(2,2,4,1))
# Produce forecasts
lapply(adamETSAANBJ, forecast, h=10, interval="prediction") |>
# Plot forecasts
lapply(function(x, ...) plot(x, ylim=c(200,280), main=x$model$loss))
This should result in the following plots:
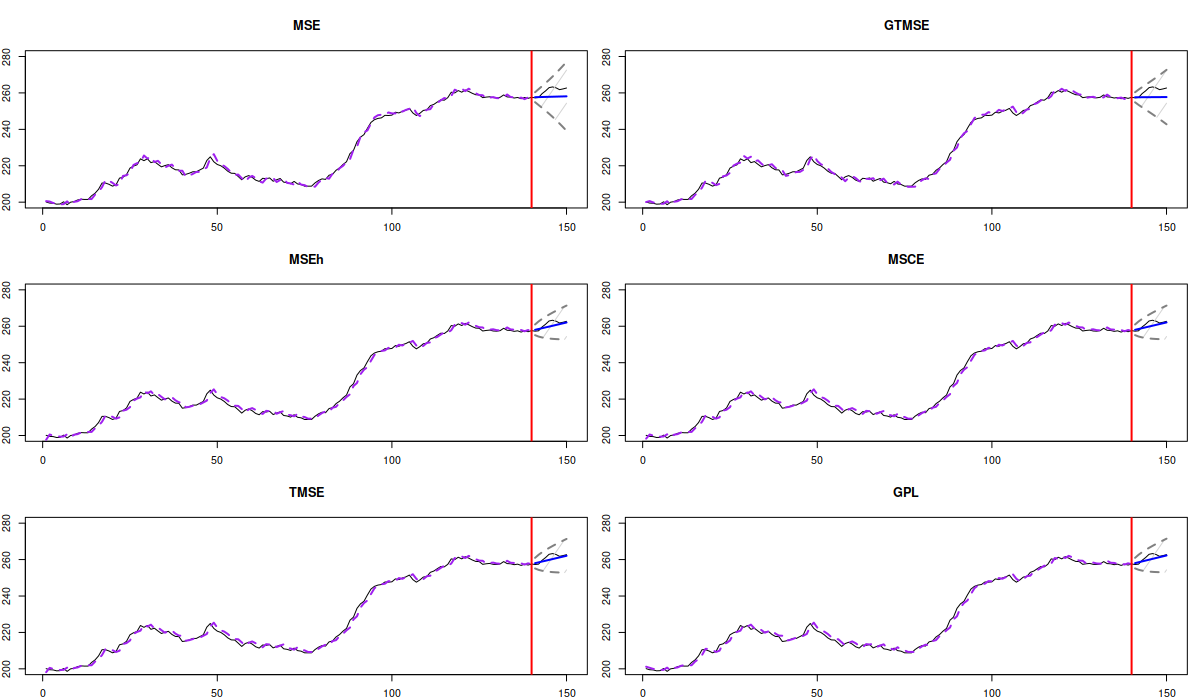
ADAM ETS on Box-Jenkins data with several estimators
Analysing the figure, it looks like the shrinkage of the smoothing parameter \(\beta\) is useful for this time series: the forecasts from ETS(A,A,N) estimated using MSEh, TMSE, MSCE and GPL look closer to the actual values than the ones from MSE and GTMSE. To assess their performance more precisely, we can extract error measures from the models:
sapply(adamETSAANBJ,"[[","accuracy") |>
round(5)[c("ME","MSE"),]
MSE MSEh TMSE GTMSE MSCE GPL ME 3.22900 1.06479 1.05233 3.44962 1.04604 0.95515 MSE 14.41862 2.89067 2.85880 16.26344 2.84288 2.62394
Alternatively, we can calculate error measures based on the produced forecasts and the measures() function from the greybox package:
lapply(adamETSAANBJ, forecast, h=10) |>
sapply(function(x, ...) measures(holdout=x$model$holdout,
forecast=x$mean,
actual=actuals(x$model)))
A thing to note about the multistep estimators is that they are slower than the conventional ones because they require producing 1 to \( h \) steps ahead forecasts from every observation in-sample. In the case of the smooth functions, the time elapsed can be extracted from the models in the following way:
sapply(adamETSAANBJ, "[[", "timeElapsed")
In summary, the multistep estimators are potentially useful in forecasting and can produce models with more accurate forecasts. This happens because they impose shrinkage on the estimates of parameters, making models less stochastic and more inert. But their performance depends on each specific situation and the available data, so I would not recommend using them universally.