



Two years ago I have written a post “Naughty APEs and the quest for the holy grail“, where I have discussed why percentage-based error measures (such as MPE, MAPE, sMAPE) are not good for the task of forecasting performance evaluation. However, it seems to me that I did not explain the topic to the full extent – the time has shown that there are some other issues that need to be discussed in detail, so I have decided to write another post on the topic, possibly repeating myself a little bit. This time we won’t have imaginary forecasters, we will be more serious.
Introduction
We start from a fact, well-known in statistics. MSE is minimised by mean value, while MAE is minimised by the median. There is a lot of nice examples, papers and post, explaining, why this happens and how, so we don’t need to waste time on that. But there are two elements related to this that need to be discussed.
First, some people think that this property is applicable only to the estimation of models. For some reason, it is implied that forecasts evaluation is a completely different activity, unrelated to the estimation. Something like: as soon as you estimate a model, you are done with “MSE is minimised by mean” thingy, the evaluation is not related to this. However, when we select the best performing model based on some error measure, we inevitably impose properties of that error on the forecasts. So, if a method performs better than the other in terms of MAE, it means that it produces forecasts closer to the median of the data than the others do.
For example, zero forecast will always be one of the most accurate forecasts for intermittent demand in terms of MAE, especially when number of zeroes in the data is greater than 50%. The reason for this is obvious: if you have so many zeroes, then saying that we won’t sell anything in the next foreseeable future is a safe strategy. And this strategy works, because MAE is minimised by median. The usefulness of such forecast is a completely different topic, but a thing to carry out from this, is that in general, MAE-based error measures should not be used on intermittent demand.
x <- rnorm(150,30,10) * rbinom(150, 1, 0.4)
The series should look something like this:
plot.ts(x)
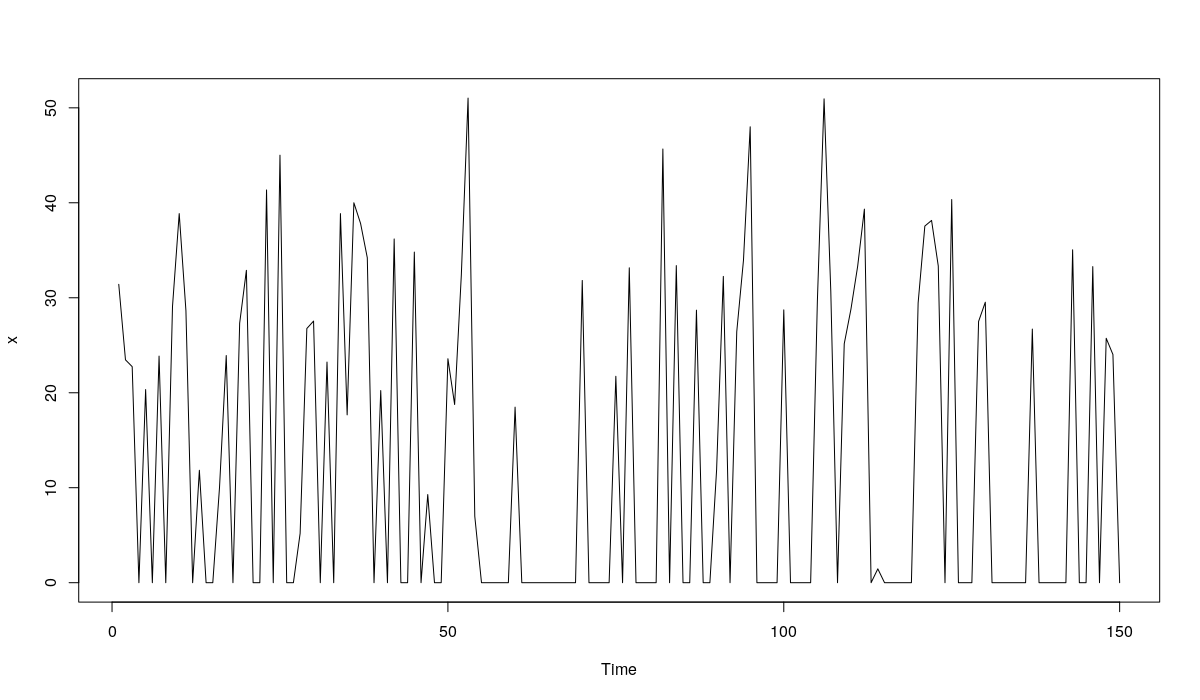
An example of artificial intermittent data
We use the first 100 observations for methods estimation and the last 50 for the evaluation of the forecasts. We use two forecasting methods: simple average of the in-sample part of the series and zero forecast (which accidentally corresponds to the median of the data). They look the following way:
plot.ts(x) abline(h=mean(x[1:100]),col="blue", lwd=2) abline(h=0,col="purple", lwd=2) abline(v=100, col="red", lwd=2)
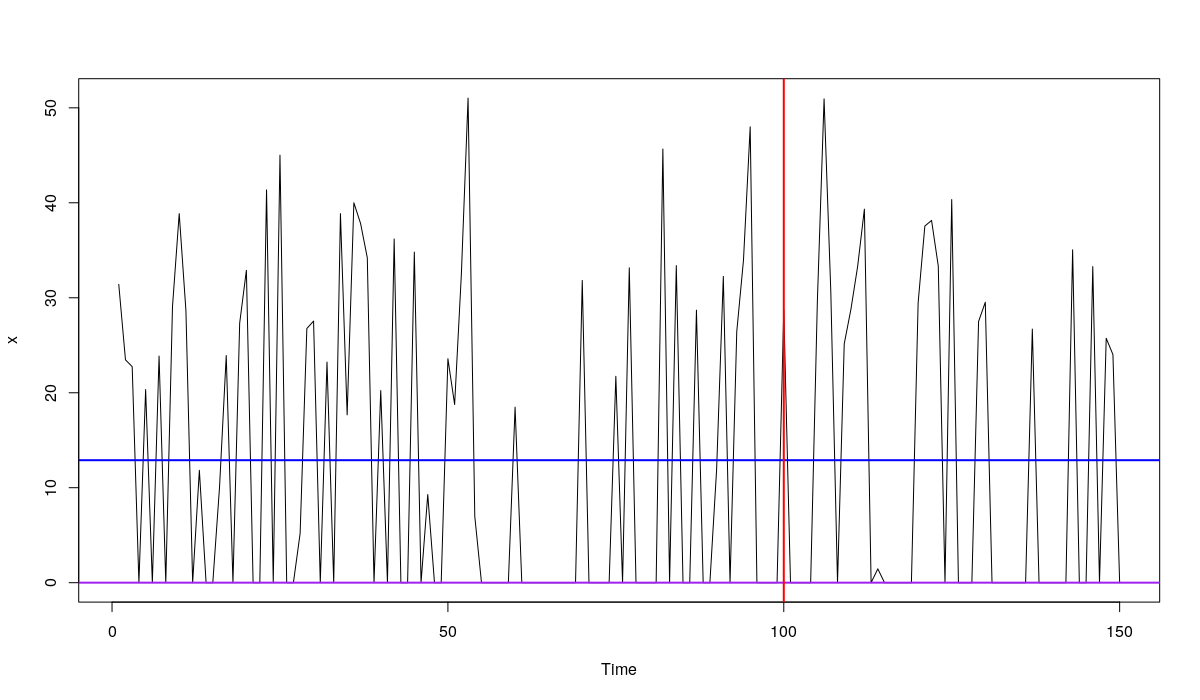
An example of artificial intermittent data and the forecasts. The blue line is the simple average, the purple line is the zero forecast. The red line splits the data into in-sample and the holdout
It is obvious that the average forecast is more reasonable than the zero forecast in this case - at least we can make some decisions based on that. In addition, it seems that it goes "through the data" in the holdout sample, which is what we usually want from the point forecasts. But what about the error measures?
errorMeasures <- matrix(c(mean(abs(x[101:150] - mean(x[1:100]))),
mean(abs(x[101:150] - 0)),
mean((x[101:150] - mean(x[1:100]))^2),
mean((x[101:150] - 0)^2)),
2,2,dimnames=list(c("Average","Zero"),c("MAE","MSE")))
errorMeasures
MAE MSE Average 15.4360 264.9922 Zero 12.3995 418.4934
We can see that MAE recommends zero forecast as the more appropriate here (it has the lower error of 12.3995 in contrast with 15.4360), while MSE prefers the Average (264.9922 vs 418.4934). This is a simple illustration of the point about the mean and median.
Second, some researchers think that if a model is optimised, for example, using MSE, then it should always be evaluated using the MSE-based error measure. This is not completely correct. Yes, the model will probably perform better if the loss function is aligned with the error measure used for the evaluation. However, this does not mean that we cannot use MAE-based error measures, if the loss is not MAE-based. These are still slightly different tasks, and the selection of the error measures should be motivated by a specific problem (for which the forecast is needed) not by a loss function used. For example, in case of inventory management neither MAE nor MSE might be useful for the evaluation. One would probably need to see how models perform in terms of safety stock allocation, and this is a completely different problem, which does not necessarily align well with either MAE or MSE. As a final note, in some cases we are interested in estimating models via the likelihood maximisation, and selecting an aligned error measure in those cases might be quite challenging.
So, as a minor conclusion, MSE-based measures should be used, when we are interested in identifying the method that outperforms the others in terms of mean values, while the MAE-based should be preferred for the medians, irrespective to how we estimate our models.
As one can already see, there might be some other losses, focusing, for example, on specific quantiles (such as pinball loss). But the other question is, what statistics minimise MAPE and sMAPE. The short answer is: "we don't know". However, Stephan Kolassa and Martin Roland (2011) showed on a simple example that in case of strictly positive distribution the MAPE prefers the biased forecasts, and Stephan Kolassa (2016) noted that in case of log normal distribution, the MAPE is minimised by the mode. So at least we have an idea of what to expect from MAPE. However, the sMAPE is a complete mystery in this sense. We don't know what it does, and this is yet another reason not to use it in forecasts evaluation at all (see the other reasons in the previous post).
We are already familiar with some error measures from the previous post, so I will not rewrite all the formulae here. And we already know that the error measures can be in the original units (MAE, MSE, ME), percentage (MAPE, MPE), scaled or relative. Skipping the first two, we can discuss the latter two in more detail.
Scaled measures
Scaled measures can be quite informative and useful, when comparing different forecasting methods. For example, sMAE and sMSE (from Petropoulos & Kourentzes, 2015):
\begin{equation} \label{eq:sMAE}
\text{sMAE} = \frac{\text{MAE}}{\bar{y}},
\end{equation}
\begin{equation} \label{eq:sMSE}
\text{sMSE} = \frac{\text{MSE}}{\bar{y}^2},
\end{equation}
where \(\bar{y}\) is the in-sample mean of the data. These measures have a simple interpretation, close to the one of MAPE: they show the mean percentage errors, relative to the mean of the series (not to each specific observation in the holdout). They don’t have problems that APEs have, but they might not be applicable in cases of non-stationary data, when mean changes over time. To make a point, they might be okay for the series on the graph on the left below, where the level of series does not change substantially, but their value might change dramatically, when the new data is added on the graph on the right, with trend time series.
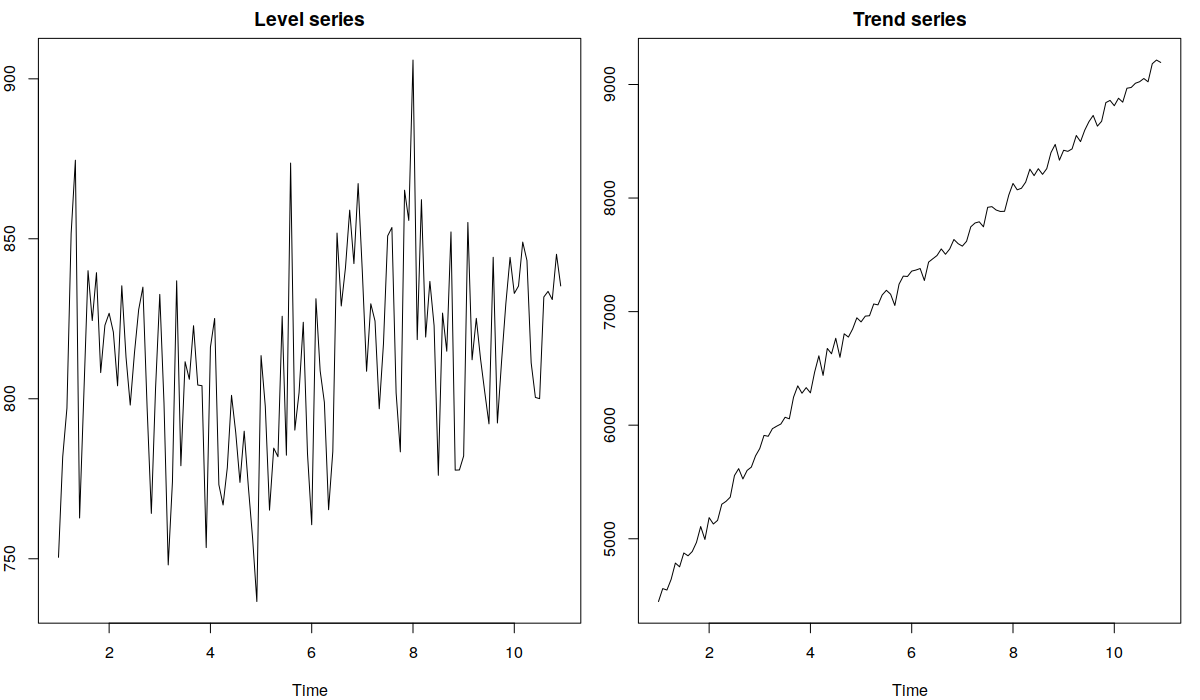
Two time series examples
MASE by Rob Hyndman and Anne Koehler (2006) does not have this issue, because it is scaled using the mean absolute in-sample first differences of the data:
\begin{equation} \label{eq:MASE}
\text{MASE} = \frac{\text{MAE}}{\frac{1}{T-1}\sum_{t=2}^{T}|y_t -y_{t-1}|} .
\end{equation}
The motivation here is statistically solid: while the mean can change over time, the first difference of the data are usually much more stable. So the denominator of the formula becomes more or less fixed, which solves the problem, mentioned above.
Unfortunately, MASE has a different issue – it is uninterpretable. If MASE is equal to 1.3, this does not really mean anything. Yes, the denominator can be interpreted as a mean absolute error of in-sample one-step-ahead forecasts of Naive, but this does not help with the overall interpretation. This measure can be used for research purposes, but I would not expect practitioners to understand and use it.
And let's not forget about the dictum "MAE is minimised by median", which implies that, in general, neither MASE nor sMAE should be used on intermittent demand.
UPDATE. The organisers of M5 competition have proposed a measure based on the idea of MASE, but which uses RMSE instead of MAE. They call it RMSSE - Root Mean Squared Scaled Error:
\begin{equation} \label{eq:RMSSE}
\text{RMSSE} = \sqrt{\frac{\text{MSE}}{\frac{1}{T-1}\sum_{t=2}^{T}(y_t -y_{t-1})^2}} .
\end{equation}
This measure is minimised by mean and can be used in cases of intermittent demand. It has properties similar to MASE and has similar limitations (not being interpretable).
The good thing about all the scaled measures is that it is very difficult for them to become infinite (division by zero). For example, sMAE and sMSE will have this problem only when the in-sample mean is zero, implying that either the data can be positive and negative, or that the data does not have variability and is equal to zero in sample. MASE and RMSSE can only become zero if there is no variability in your train set.
However, it is worth mentioning that it might not be enough to look at just mean values of measures. Analysing the distribution can give you a better idea of what is happening with the models. Typically the distribution of error measures is highly skewed, so the mean will be influenced by the cases, when your model has failed seriously. It might be the case that it did stellar job on 99.9% of cases and failed only on 0.1%. However, the mean value will tell you that your model is not good enough in comparison with a simpler one. So, I would recommend calculating at least mean and median values of sMAE / sMSE / MASE / RMSSE, when you need to aggregate them across many time series. Producing quartiles and / or boxplots might give you an additional useful information.
Relative measures
Finally, we have relative measures. For example, we can have relative MAE or RMSE. Note that Davydenko & Fildes, 2013 called them “RelMAE” and “RelRMSE”, while the aggregated versions were “AvgRelMAE” and “AvgRelRMSE”. I personally find these names tedious, so I prefer to call them “rMAE”, “rRMSE” and “ArMAE” and “ArRMSE” respectively. They are calculated the following way:
\begin{equation} \label{eq:rMAE}
\text{rMAE} = \frac{\text{MAE}_a}{\text{MAE}_b},
\end{equation}
\begin{equation} \label{eq:rRMSE}
\text{rRMSE} = \frac{\text{RMSE}_a}{\text{RMSE}_b},
\end{equation}
where the numerator contains the error measure of the method of interest, and the denominator contains the error measure of a benchmark method (for example, Naive method in case of continuous demand or forecast from an average for the intermittent one). Given that both are aligned and are evaluated over the same part of the sample, we don’t need to bother about the changing mean in time series, which makes both of them easily interpretable. If the measure is greater than one, then our method performed worse than the benchmark; if it is less than one, the method is doing better. Furthermore, as I have mentioned in the previous post, both rMAE and rRMSE align very well with the idea of forecast value, developed by Mike Gilliland from SAS, which can be calculated as:
\begin{equation} \label{eq:FV}
\text{FV} = 1-\text{relative measure} \cdot 100\%.
\end{equation}
So, for example, rMAE = 0.96 means that our method is doing 4% better than the benchmark in terms of MAE, so that we are adding the value to the forecast that we produce.
As mentioned in the previous post, if you want to aggregate the relative error measures, it makes sense to use geometric means instead of arithmetic ones. This is because the distribution of relative measures is typically asymmetric, and the arithmetic mean would be too much influenced by the outliers (cases, when the models performed very poorly). Geometric one, on the other hand, is much more robust, in some cases aligning with the median value of a distribution.
The main limitation of relative measures is that they cannot be properly aggregated, when the error (either MAE or MSE) is equal to zero either in the numerator or in the denominator, because the geometric mean becomes either equal to zero or infinity. This does not stop us from analysing the distribution of the errors, but might cause some inconveniences. To be honest, we don’t face these situations very often in real world, because this implies that we have produced perfect forecast for the whole holdout sample, several steps ahead, which can only happen, if there is no forecasting problem at all. An example would be, when we know for sure that we will sell 500 bottles of beer per day for the next week, because someone pre-ordered them from us. The other example would be an intermittent demand series with zeroes in the holdout, where the Naive would produce zero forecast as well. But I would argue that Naive is not a good benchmark in this case, it makes sense to switch to something like simple mean of the series. If you notice that either rMAE or rRMSE becomes equal to zero or infinite for some time series, it makes sense to investigate, why that happened, and probably remove those series from the analysis.
So, summarising, if you need an unbiased measure that is easy to interpret, then I would recommend using relative error measures. If you want an unbiased and robust error measure that works in almost all the cases, but does not necessarily have an easy interpretation, then use the scaled ones. Keep in mind that MSE is minimised by mean and MAE is minimised by median, and if you want to decide, what to use between the two, you should probably ask yourself: what do we really need to measure? In some cases it might appear that none of the above is needed. Maybe you should look at the prediction intervals instead of point forecasts... This is something that we will discuss next time.
Examples in R
To make this post a bit closer to the application, we will consider a simple example with smooth package v2.5.3 and several series from the M3 dataset.
Load the packages:
library(smooth) library(Mcomp)
Take a subset of monthly demographic time series (it’s just 111 time series, which should suffice for our experiment):
M3Subset <- subset(M3, 12, "demographic")
Prepare the array for the two error measures: rMAE and rRMSE (these are calculated based on the measures() function from greybox package). We will be using three options for this example: CES, ETS with automatic model selection between the 30 models and ETS with the automatic selection, skipping multiplicative trends:
errorMeasures <- array(NA, c(length(M3Subset),2,3),
dimnames=list(NULL, c("rMAE","rRMSE"),
c("CES","ETS(Z,Z,Z)","ETS(Z,X,Z)")))
Do the loop, applying the models to the data and extracting the error measures from the accuracy variable. By default, the benchmark in rMAE and rRMSE is the Naive method.
for(i in 1:length(M3Subset)){
errorMeasures[i,,1] <- auto.ces(M3Subset[[i]])$accuracy[c("rMAE","rRMSE")]
errorMeasures[i,,2] <- es(M3Subset[[i]])$accuracy[c("rMAE","rRMSE")]
errorMeasures[i,,3] <- es(M3Subset[[i]],"ZXZ")$accuracy[c("rMAE","rRMSE")]
cat(i); cat(", ")
}
Now we can analyse the results. We start with the ArMAE and ArRMSE:
exp(apply(log(errorMeasures),c(2,3),mean))
CES ETS(Z,Z,Z) ETS(Z,X,Z) rMAE 0.6339194 0.8798265 0.8540869 rRMSE 0.6430326 0.8843838 0.8584140
As we see, all models did better than Naive: ETS is approximately 12 - 16% better, while CES is more than 35% better. Also, CES outperformed both ETS options in terms of rMAE and rRMSE. The difference is quite substantial, but in order to see this clearer, we can reformulate our error measures, dividing rMAE of each option by (for example) rMAE of ETS(Z,Z,Z):
errorMeasuresZZZ <- errorMeasures
for(i in 1:3){
errorMeasuresZZZ[,,i] <- errorMeasuresZZZ[,,i] / errorMeasures[,,"ETS(Z,Z,Z)"]
}
exp(apply(log(errorMeasuresZZZ),c(2,3),mean))
CES ETS(Z,Z,Z) ETS(Z,X,Z) rMAE 0.7205050 1 0.9707448 rRMSE 0.7270968 1 0.9706352
With these measures, we can say that CES is approximately 28% more accurate than ETS(Z,Z,Z) both in terms of MAE and RMSE. Also, the exclusion of the multiplicative trend in ETS leads to the improvements in the accuracy of around 3% for both MAE and RMSE.
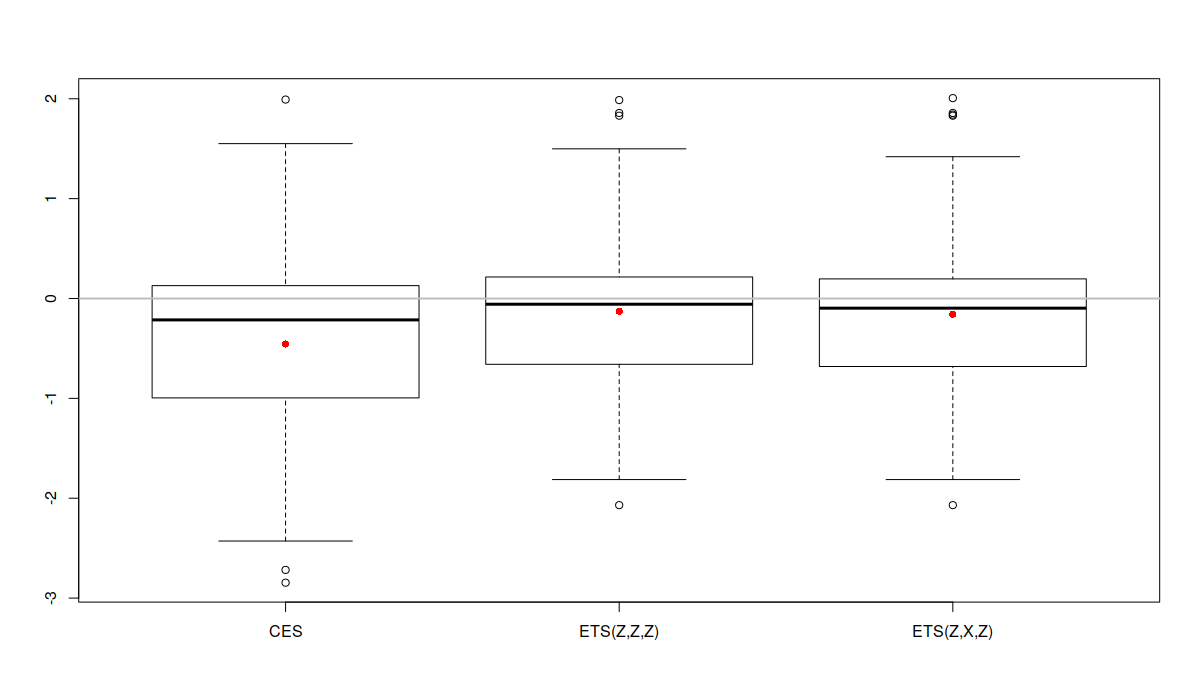
We can also analyse the distributions of the error measures, which sometimes can give an additional information about the performance of the models. The simplest thing to do is to produce boxplots:
boxplot(errorMeasures[,1,]) abline(h=1, col="grey", lwd=2) points(exp(apply(log(errorMeasures[,1,]),2,mean)),col="red",pch=16)
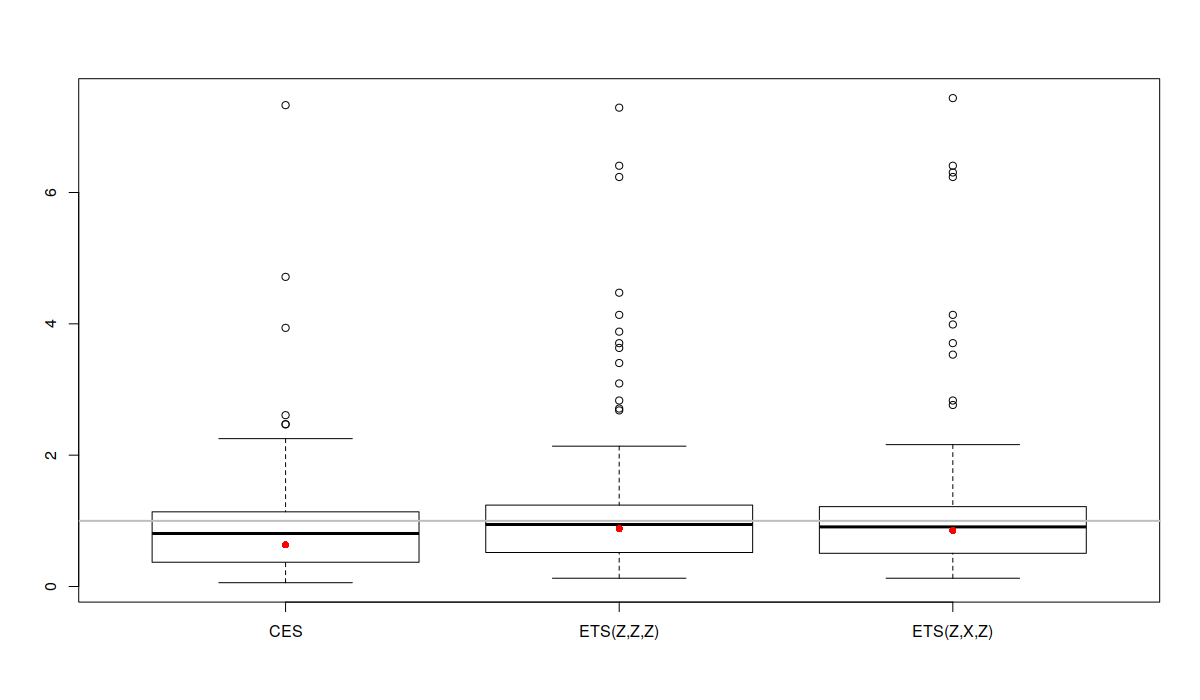
Boxplot of rMAE for a subset of time series from the M3
Given that the error measures have asymmetric distribution, it is difficult to analyse the results. But what we can spot is that the boxplot of CES is located lower than the boxplots of the other two models. This indicates that the model is performing consistently better than the others. The grey horizontal line on the plot is the value for the benchmark, which is Naive in our case. Notice that in some cases all the models that we have applied to the data do not outperform Naive (there are values above the line), but on average (in terms of geometric means, red dots) they do better.
Producing boxplot in log scale might sometimes simplify the analysis:
boxplot(log(errorMeasures[,1,])) abline(h=0, col="grey", lwd=2) points(apply(log(errorMeasures[,1,]),2,mean),col="red",pch=16)
Boxplot of rMAE in logarithms for a subset of time series from the M3
The grey horizontal line on this plot still correspond to Naive, which in log-scale is equal to zero (log(1)=0). In our case this plot does not give any additional information, but in some cases it might be easier to work in logarithms rather than in the original scale due to the potential magnitude of positive errors. The only thing that we can note is that CES was more accurate than ETS for the first, second and third quartiles, but it seems that there were some cases, where it was less accurate than both ETS and Naive (the upper whisker and the outliers).
There are other things that we could do in order to analyse the distribution of error measures more thoroughly. For example, we could do statistical tests (such as Nemenyi) in order to see whether the difference between the models is statistically significant or if it is due to randomness. But this is something that we should leave for the future posts.
P.S. For additional discussion on the topic, I would recommend reading an M4 paper by Stephan Kolassa.
Nice post, and thank you for the pointers to my stuff! You may be interested in my commentary on the M4, which is very much related: https://doi.org/10.1016/j.ijforecast.2019.02.017. (To be honest, I’m not convinced by Makridakis et al.’s rejoinder.)
Hi Stephan,
Thanks for your comment and the link. I will add it to the post.
I’m not excited by their responses either and I don’t understand the reason for their stubborness at all. But it is what it is, I guess…
The use of relative errors was not even possible given the M4 data set, as they resulted in divisions with zero for some series. What do you do in these cases? How do you produce a summary across the series? Removing these particular series is not an option if the numerator (the accuracy of each competitor) is not zero as well (otherwise you might give advantage to some participants)…
I kindly disagree with the “stubbornness” comment. But if you feel so strongly about the organisational aspects of M4, I believe that there is room for more (better?) forecasting competitions. Maybe one organised by Lancaster?
1. To be honest, I just don’t know what to do in that case. I recommend removing those series, as there is nothing to do then. This is a solution from the top of my head, it’s not ideal, but it’s a solution. Anyway, if Naive MAE is zero in the holdout, then you don’t need to produce forecasts for such series. Why bother with them at all? If in real life the sales of a product are 1,233 units each week, then why do we care about finding the best performing method for that product?
However, as I say, the measure is not ideal, but, to my personal taste, it is one of the best that we have yet.
2. Goodwin & Lawton (1999) showed the problems with SMAPE. Hyndman & Koehler (2006) suggested an alternative based on that. Davydenko & Fildes (2013) discussed existing measures and pointed out at their limitations. Petropoulos & Kourentzes (2015) proposed new scaled measures… There are also numerous discussions in Foresight, including Stephan’s contributions. So, we have done huge progress since Makridakis (1993). And yet all the progress has been ignored by the organisers, and they still use SMAPE because it allows to have “a continuation of competitions”. IMHO, the “continuation” argument is weak, because nowadays we can easily calculate any error measure for the available datasets and forecasts in seconds. So, to my taste, this is stubbornness (and, probably, some elements of politics). If we know that the measure has those limitations, why do we still insist on using it?
3. I don’t think that these types of huge competitions are useful anymore. I mean, what’s the main finding of M4? What have we learned new from it? That “machine learning doesn’t work”? In my opinion, this is not science, this is politics. So, I don’t see a point in either organising or participating in these sorts of things, because there is no good research question there.
The main value of M competitions is what they leave behind. If it was not for them, we would possibly haven’t heard of Theta method or Smyl’s method.
From my editorial (https://doi.org/10.1016/j.ijforecast.2019.01.006):
“The impacts of these competitions are threefold:
1. They inspired and motivated forecasting researchers and practitioners to develop and test their own models and approaches to forecasting.
2. They provided distinct, publicly-available data sets. For many forecasting researchers, including the first author of this editorial, these data sets have formed a “playground” on which new ideas can be tested, and so he celebrated when the 13.85% sMAPE of the Theta method on the M3 monthly subset was outperformed in the M4 Competition.
3. They bridge the gap between theory and practice.”
So, the way I see, the M competitions do promote science.
“I don’t see a point in either organising or participating in these sorts of things”: but… you did participate in the M4 competition (with two entries) regardless that you knew from the start how the evaluation is going to be done! As for the future, you can do as you wish of course but, in my opinion, it would be a huge loss if the leading forecasting centre in the UK did not participate in the next forecasting competitions.
I agree, the promotion of forecasting research is one of the good things of the competitions. That’s a good point. And don’t get me wrong, in my opinion M3 is one of the best things that has happened in the field of forecasting. It had sound hypothesis and useful results, it had a specific aim.
I participated in M4, because I had high expectations and I thought that I own something to Spyros, because of his previous work and indirect influence on my life. I was confident that the centre needed to participate in M4 in order to support him (thus the second submission). Unfortunately, it turned out that the aim of the competition was different than the organisers declared. So, now I’m sceptical about that thing. I don’t know, whether the CMAF will participate in M5, but at the moment I don’t want to be involved mainly because I will probably be helping in yet another rant on the topic of “machine learning doesn’t work” or something like that.
The problem of zero MAEs was easily solved by the method proposed in (Davydenko and Fildes, 2013, p. 24), full text available here, see note (a):
https://www.researchgate.net/publication/282136084_Measuring_Forecasting_Accuracy_Problems_and_Recommendations_by_the_Example_of_SKU-Level_Judgmental_Adjustments
If you use trimmed AvgRelMAE, then there is no problem in obtaining a certain percentage of zero MAEs.
The organisers ranked all methods based on one point forecast error, that is the OWA. The winners of the competition were decided based on that. They clearly communicated this choice from the very beginning.
Montero-Manso et al explicitly consider this as a loss function. Smyl, who was working on normalised data, opted for a bias-corrected mean absolute error.
According to your post, I understand that you really like MASE for research purposes, at least when it’s not being used for forecasting intermittent demand data. So, I guess that if M4 used MASE instead of OWA, you’d be completely OK with that, right? If you examine the results, you’ll see that the differences reported between OWA and MASE in terms of ranks are negligible. Nothing would have really changed in the conclusions of the competition. We’d have learned exactly the same things about how to improve forecasting and that’s what really matters in competitions like M4, right? So why keep criticising that strongly a choice which seems to be working well after all? For instance, do you consider M3 a failure because of sMAPE? Personally, not at all. We have learned lots of things because of M3 (I cannot really understand why you say we haven’t). You may also use the M3 series and methods to conduct research, while being completely free to change the error measure originally used if don’t like it. In any case, as you mention, it is really fast to compute any measure you like so, if you think that we can learn something else/more from M4 using a different error measure, you are free to test and report that. As you know, all the submissions are publicly available for further investigation.
Is it better to use relative measures? Probably yes, but then you’ll have to use a bunch of ad-hoc rules to deal with the limitations discussed by you and Fotis, which I believe is neither neat nor objective. It seems that no measure is perfect. Moreover, even if the choice of OWA was inappropriate, it was announced way before the start of the competition. So, forecasters not liking the error measure had the choice not to participate, while those liking it had the opportunity to adjust their submissions based on that explicit measure to further improve their results (as noted by Fotis, some of the top-performing participants actually did that). The same stands for Kaggle competitions. I’ve never heard of anyone complaining about the measures used there. Forecasters just see what the objective is and go for it.
A last comment based on your statement –I won’t participate in a competition because I don’t like the error measure–: Would you do the same for a company? Would you be unwilling to improve their forecasting process, just because the organisation or the managers don’t use a cost function of your taste? Probably you would try to convince them about the superiority of relative measures, I agree, but in the end you’d have to deal with the limitations present.
To be honest, I don’t see any politics here. Just a forecasting problem with a well-defined evaluation measure, waiting for the best solution.
Hi Vangelis,
1. I don’t say that I really like MASE, but we already know what this measure is minimised with. It is not the question of taste, it is the question of statistics. So, it is good, because we know what it does. And yes, it is better than SMAPE, few papers in IJF show that.
2. Table 4 of your paper (https://www.sciencedirect.com/science/article/pii/S0169207019301128) demonstrates that the ranking is different between MASE and SMAPE. For example, Pawlikowski et al. is ranked as 2 instead of 5, when we use MASE instead of SMAPE. The results change based on different measures, mainly because they are focused on different central tendencies.
3. OWA and MASE rank people also differently. For example, Montero-Manso is 3rd, not 2nd, if MASE is used instead of OWA. Fiorucci is 4th, not 5th etc. Once again, this is expected due to different measures, but the results a different, so we cannot just neglect them and say that the error measure is not important.
4. But my main critique is that we do not know what minimises SMAPE. So, we don’t know in what terms the methods perform better. For example, if we had MSE-based measure, we could have said that some methods produce more accurate mean values, but in the case of M4, we cannot say anything specific. Furthermore, we know that SMAPE prefers over-forecasting to under-forecasting. So the best method according to SMAPE will probably slightly overshoot the data. Why is this good?
5. I’ve never said that either of competitions is a failure! And I explicitly mentioned in the comment above that I think that M3 was one of the best things happening in forecasting. So, you got a wrong impression here. M4 was interesting, but I don’t find it as ground breaking as M3.
6. One of my points in the post is that there is no perfect error measure. There are better ones and there are worse ones. MASE and measures similar to MASE can be used in research, but when it comes to practice, I would go with relative ones, because they are easier to interpret.
7. I have never said that OWA was not appropriate for the competion. I understand why you use it, and, given the selection of error measures, it sort of makes sense. And I don’t complain about the error measures you used – it’s your business. People, participating in competitions, accept the conditions. I did as well. I only point out at the limitations of the error measures you use. I don’t understand, why you insist on using SMAPE, given all the critique in the literature for the last 20 years…
8. I never said that I won’t participate because of the error measures. Once again, there is a misunderstanding. The reason is different. Whatever the findings and conclusions of M4 are, it all comes to the statement repeated by Spyros everywhere over and over again: “machine learning doesn’t work” – which is neither fair nor correct. I have participated in M4 for a different reason. You have said in the beginning that the aim was to see, how the new methods perform, and I wanted to support you in this by submitting some innovative things. But it appears that this was not the true aim. It seems that the main aim of M4 was to show that “machine learning doesn’t work”, but this has never been vocalised in advance. So, now I feel that by participating in M4 I was deceived. My feelings would be quite different if you have stated clearly in advance the true hypotheses that you want to test. Now, I don’t want to participate in M5, because it might lead to something similar. Probably Spyros will end up ranting again that “machine learning doesn’t work” or something like that. Why should I spend my time on that (especially given my workload for the upcoming year), when I can do something more useful?
9. Are you going to use SMAPE for intermittent demand? :)
1. I don’t disagree that MASE has better properties than sMAPE. In the M4 paper we discuss the reasons of using both measures, noting that MASE is superior to sMAPE, while also stressing the limitations of the former in terms of interpretation. Personally, I’m not a sMAPE-fan either, but it’s useful for interpreting your results, can’t deny that, especially when MAPE or relative measures are not an option.
2. That will always be the case when using different error measures, either if the measures being compared are good or bad. Sure, we cannot neglect such differences, but do they matter in practice after all? I believe that the most important thing here is that both measures agree on which methods did best, providing the same results in terms of statistical significance. So, yes, one method may score position 2 or 3 depending on the measure used, we always knew that, but the conclusions about whether the examined method works systematically better than others remain the same.
3. Same with 2
4. As I said, it isn’t good. It’s just easy to interpret. That’s why it is used either way. You may use a different measure depending on your research question if you like. No problem.
5. As Nikolopoulos mentions in his commentary, first cut is the deepest. Time will tell.
6. Fair enough.
7. That’s a little bit controversial. You hate sMAPE, but have no problem with OWA, that involves sMAPE. Either way, like you said, participants accept the conditions when participating in a competition so, if OWA is the measure, just go for it.
8. Honestly, I don’t understand why you believe that the aim of M4 was to prove that ML doesn’t work. Its aim was clearly the one of the previous three competitions, i.e., identifying new accurate methods and promoting forecasting research and practice. Its motivation was also clear from the beginning till the end. The performance of ML was just evaluated as an alternative over traditional statistical methods given the hype and the advances reported since the last M competition. Actually, if you read the M4 paper, you’ll see that one of the main finding of the M4 competition was that ML works, at least when applied in a smart way (e.g., by using elements of statistical models as well). Why witch-hunt ML anyway? I don’t understand what the motivations could be. Deceived? Really? Anyway, we appreciate the work done at CMAF so, either if you are personally willing to participate or not, we’ll be happy to receive a submission from your Centre.
9. You made your point. Being sarcastic adds no value. But you are free to do so if this puts a smile on your face.
Thanks for responding to my questions.
To me personally, it’s not about hate, it’s about using the findings from the recent literature. To be honest, I used SMAPE a lot, when I worked in Russia, because it sounded as a reasonable measure at that point (I even have it as a main measure in a textbook on forecasting that I have coauthored). But then the new findings came into light, and I decided that I need to take them into account. So, nothing personal, just pragmatism.
As for the very last point, my apologies. I did not want to sound sarcastic, it was more like a joke, and, as it appears, not the best one. My bad.
As a very last note, to clarify something out, I personally think that you did a very good job in organising the competition and writing the papers on that, especially given all the existing limitations. Still, this does not mean that there is no room for improvement… :)
Hi Ivan,
Thanks for the article. Some very nice insights on forecasting error measures. I have a question on the use of error measures which cause forecast to be more closely aligned to the median of the distribution (E.g., MAE).
In supply chain, we often aggregate/disaggregate forecasts using hierarchical forecasting models. Mathematically, while we can add/subtract/average point forecasts that align to average (E.g., if we use MSE), we cannot extend the same to median-based point forecasts.
What is the impact of performing these operations on median-based point forecasts in the real-world? Is it still okay?
Thanks,
Suraj
Hi Suraj,
I think we need to distinguish two things: what the model produces and what the forecast corresponds to, when we evaluate it. So, when you work with averages, you can easily aggregate forecasts, no matter what error measure you use (there might be some issues with non-linear models from the distributional point of view, but this is a different topic). But when it comes to evaluating the model using MAE for different levels, what you do is assess how your forecast performs in terms of median of the true distribution for the specific levels. So, there should not be an issue here, as long as you are aware of what you do.
However, if you want to align your model estimation with the evaluation (i.e. produce median forecasts and evaluate models using MAE), then this is a different question, because then you will be dealing with medians produced by models, and the sum of medians is not the same as the median of sums. Everything becomes much more complicated in this case… You might need to revert to simulations in order to produce correct median forecasts.
Renaming AvgRelMAE into ArMAE and AvgRelMSE intro ArRMSE is not a great idea (unless you intentionally want to disguise the original names) because of these reasons:
1) It is not very ethical to rename a method proposed by other people just because “you find it tedious”, especially after many people used the original names.
2) The original names, AvgRelMAE and AvgRelMSE, were chosen in order to avoid confusion with other metrics based on the arithmetic means (some researchers had already used the ARMSE abbreviations for the arithmetic means).
3) This makes the measures recognizable and using the same name across different studies helps summarize research made by different authors. For example, you can see the AvgRelMAE in the review on retail forecasting and it is immediately clear as to what aggregation scheme was used.
It is also not very ethical that are making every effort to avoid mentioning that the the scheme based on the geometric averaging of relative performances was proposed and justified in (Davydenko and Fildes, 2013). In fact, the AvgRelMSE and AvgRelMAE are special cases of a general metric proposed in this Ph.D. thesis: (Davydenko, 2012, p. 62):
https://www.researchgate.net/publication/338885739_Integration_of_judgmental_and_statistical_approaches_for_demand_forecasting_Models_and_methods
It is also not very ethical that are making every effort to eschew mentioning that the the scheme based on the geometric averaging of relative performances was proposed and justified in (Davydenko and Fildes, 2013). In fact, the AvgRelMSE and AvgRelMAE are special cases of a general metric proposed in this Ph.D. thesis: (Davydenko, 2012, p. 62):
https://www.researchgate.net/publication/338885739_Integration_of_judgmental_and_statistical_approaches_for_demand_forecasting_Models_and_methods
The IJF paper is just a chapter of the Ph.D. thesis. The boxplots of log(RelMAE) were also first demonstrated in (Davydenko and Fildes, 2013), which is worth noting when following this approach.
And, yes, this metric has the best statistical properties among other alternatives, but you must give proper references when writing about it (either Davydenko and Fildes, 2013, or Davydenko, 2012).
As for zero MAEs, as I wrote above, there’s no problem with these occurrences, the method of working with zero MAEs was given in (Davydenko and Fildes, 2014, p. 24)
https://www.researchgate.net/publication/282136084_Measuring_Forecasting_Accuracy_Problems_and_Recommendations_by_the_Example_of_SKU-Level_Judgmental_Adjustments
So it is not very clear as to why you still think that obtaining zero MAEs is a problem. One important thing is, of course, that your loss function used for optimization should correspond to the loss function used for evaluation. This criteria for a good error measure was formulated in this chapter (Davydenko and Fildes, 2016, p. 3):
https://www.researchgate.net/publication/284947381_Forecast_Error_Measures_Critical_Review_and_Practical_Recommendations
The same chapter says that if you have a density forecast, then you need to adjust your forecast depending on the loss function. But most commonly you’ll obtain your forecast optimized for the linear symmetric loss (explained in the same chapter), thus the AvgRelMAE is generally a reasonable option.
Dear Andrey Davydenko,
Thank you for your comments. A couple of points from my side:
1. The name “AvgRelMAE” is objectively complicated in perception and difficult to pronounce, and I personally think that a simpler name can be used instead. For example, using “rMAE” instead of “RelMAE” looks shorter and easier to read. I don’t use “Avg” part because I usually present results in a table that contains both mean and median values of rMAE. In fact, I’m not the first person using this abbreviation – I’ve seen it in some presentation of the ISF2019.
2. As for MAE becoming equal to zero, it is an issue of any relative measure. Trimming is one of the solutions to the problem, indeed. But it is just a solution to the problem appearing in the measure naturally. In fact, this is what I suggest in this post: “Having said that, if you notice that either rMAE or rRMSE becomes equal to zero or infinite for some time series, it makes sense to investigate, why that happened, and probably remove those series from the analysis.”
3. As for my ethics, I promote your error measure and refer to your work every time I mention it.
Kind regards,
Ivan Svetunkov
“MAE-based error measures should not be used on intermittent demand.”
Or any distribution where the mean and the median are different ;)
(i.e., nearly all demand distributions in supply chains)
Yes, very good point, Nicolas! Agreed :)