



While Naive is considered a standard benchmark in forecasting, there is a case where it might not be a good one: intermittent demand. And here is why I think so.
Naive is a forecasting method that uses the last available observation as a forecast for the next ones. It does not have any parameters to estimate, it does not require training, it can be applied to the sample of any data (even if you only have one observation). When you deal with a regular demand, it makes perfect sense to use Naive as a benchmark, because it costs nothing in terms of computational time, you get a forecast of demand, and if you cannot beat it, you should rethink your forecasting process.
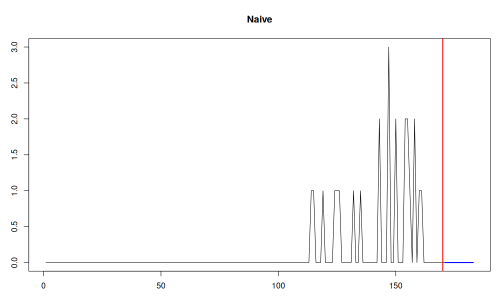
However, in case of intermittent demand, the demand itself does not happen on every observation. As a result, when the Naive copies the last available value, it can either reproduce either a proper non-zero demand, or just the absence of demand. The latter implies that nobody bought our product today, and nobody will do in the next week or whatever the forecasting horizon we use. In the following image, Naive will be the most accurate forecasting method, because in the training set, the final observation was zero, and in the test set we did not have any sales:

Naive forecast on intermittent demand
But is this useful? To answer this question, we need to understand what specifically we are forecasting when we deal with demand with zeroes.
As discussed in a previous post, zeroes can occur for different reasons: some of them happen because nobody came to buy the product (naturally occurring zeroes), while the others appear because there was some sort of disruption (e.g. a stockout) or a product was discontinued (artificially occurring zeroes). The two situations are fundamentally different, but if we work with the sales data exclusively (no stock information), it can be hard to tell the difference between them. Naive might work perfectly in both cases, forecasting no sales for the next few observations, and it can be 100% right in some cases. But the problem is that this is not useful. If we indeed cannot beat Naive on the data with zeroes, it does not mean that we should use it, because there is a chance that we have stockouts in the holdout period. If that’s the case, we might be doing something fundamentally wrong. After all, “we will not sell anything” is in general a simple statement, but not ordering products based on that could be a mistake, because “no sales” is not the same as “no demand”. In fact, if Naive indeed performs very well on your series with zeroes, this might indicate that your evaluation is wrong and you need to clean the data, removing the discontinued and out of stock items from the evaluation.
There are three lessons here:
- we should forecast demand, not sales;
- we should measure accuracy on the data with naturally occurring zeroes – do data cleaning before setting up your evaluation;
- it’s better to use a benchmark that tries capturing demand, not the one that reproduces sales.
Arguably, a more helpful benchmark forecast would be the one in the following image:

Forecast for intermittent demand from the SMA
The forecast above was generated using the Simple Moving Average, and it tells us that there is a demand for the product over the next 13 days. Yes, it is less accurate than Naive, but it gives an estimate of the expected demand, not the expected sales.
The blog post mentions SMA as a possible alternative to Naive for forecasting intermittent demand. Could you elaborate on other forecasting methods that might be more suitable for this scenario? Telkom University Jakarta
Yes, sure. I would include the following in the list of benchmarks for intermittent demand:
1. SMA,
2. Simple Exponential Smoothing,
3. Global Average,
4. Zero forecast (just a sanity check to make sure that everything is in order).
The more complicated benchmarks would be:
5. Croston’s method (https://doi.org/10.2307/3007885)
6. TSB (https://doi.org/10.1016/j.ejor.2011.05.018)
Hope that helps.